
Vancore
73 posts


@OfficialLoganK Do you have their revenue numbers? Do they have any paid clients? For me it looks like the second dotcom boom: everyone has a domain.com and no one is selling anything.
English

Very excited to see millions of new businesses come into the world over the next year, a very special moment to build!
English
The bottleneck has so quickly moved from code generation to code review that it is actually a bit jarring.
None of the current systems / norms are setup for this world yet.
English

We’re evolving Google AI plans to give you more control over how you build. Every subscription includes built-in AI credits, which can now be used for Antigravity, giving you a seamless path to scale.
Google AI Pro is the home for the practical builder, hobbyists, students, and developers who live in the IDE and don't necessarily rely on an agent. This plan features generous limits for Gemini Flash, with a baseline quota included to "taste test" our most advanced premium models.
Google AI Ultra serves as the daily driver for those shipping at the highest scale who need consistent, high-volume access to our most complex models.
If you’re on Pro but need "extra juice" for a heavy sprint or deeper access to premium models, simply top up your AI credits to customize your plan.
Keep building. Keep shipping.
English
@OfficialLoganK Yeah Yeah🥱, the creative writing score on the 3.1 Pro is actually lower than that on the 3.0 Pro. It's truly an "epic" upgrade!
English
PSA: we are turning down Gemini 3 Pro next Monday March 9th.
You can upgrade to 3.1 Pro Preview which improves on lots of the things folks gave feedback about on the first Gemini 3 rev. Please keep the feedback coming : )
English
@AnthropicAI So... can you guarantee that you haven't distilled any LLM data from any other company since your inception?
English

We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
English
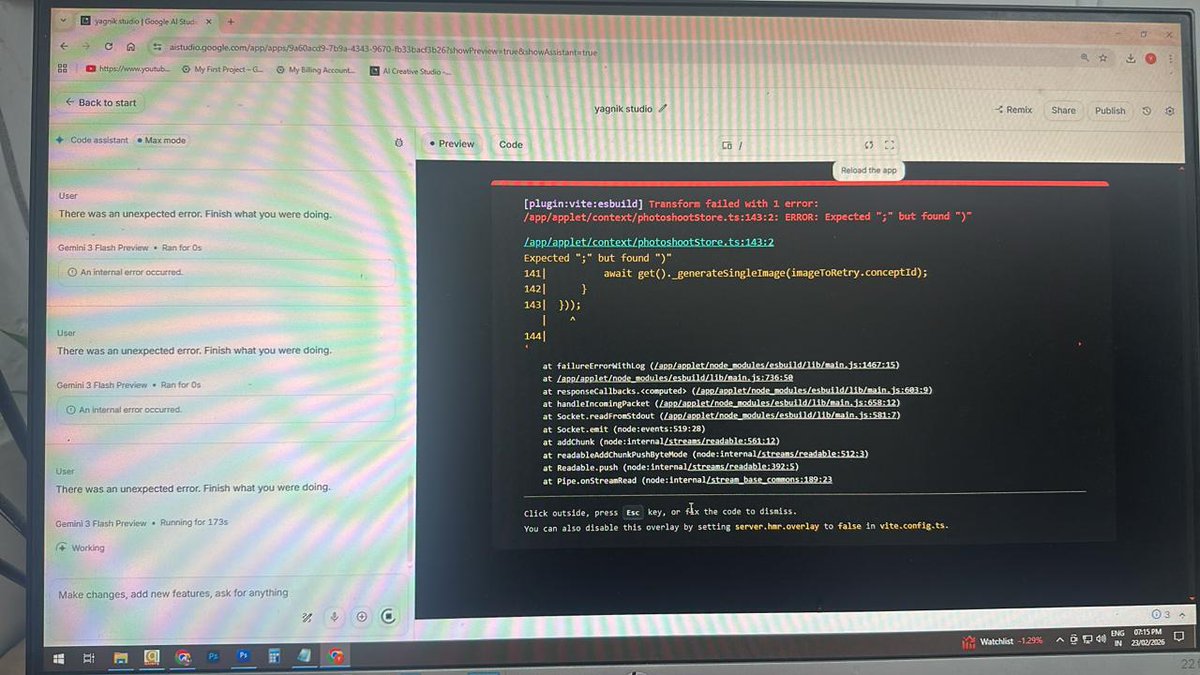
@sanganisahil @GoogleAIStudio team is working hard to stabilize, lots of new infra in place rn, fire fighting across the stack, issues are currently effecting ~10% of requests
English

i guess ai studio team got cooked with this update. tons of customers asking for what's wrong with @GoogleAIStudio
@OfficialLoganK bhai any update when this will be fixed?


English
@_mohansolo First, fix the 429 error issues on the Gemini 3.1 Pro, and improve its performance in creative writing. I didn't pay for a product that's worse than the 2.5 Pro.
English

We’ve been seeing a massive increase in malicious usage of the Anitgravity backend that has tremendously degraded the quality of service for our users. We needed to find a path to quickly shut off access to these users that are not using the product as intended. We understand that a subset of these users were not aware that this was against our ToS and will get a path for them to come back on but we have limited capacity and want to be fair to our actual users.
English
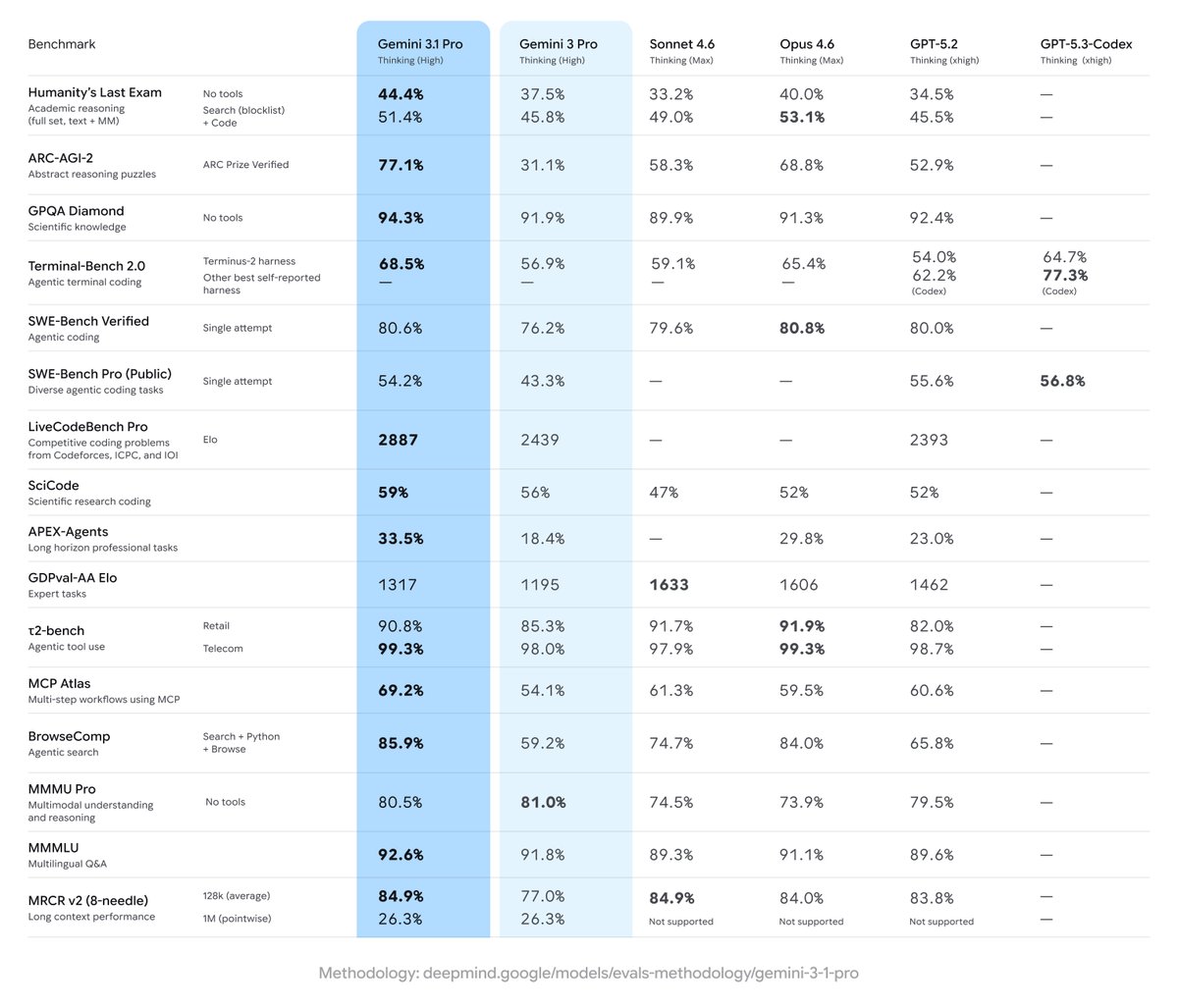
Gemini 3.1 Pro is super strong, it is incredible to see the progress from 3.0 to 3.1 in such a short time. The acceleration is real!
blog.google/innovation-and…
English
Introducing Gemini 3.1 Pro, our new SOTA model across most reasoning, coding, and stem use cases!
English
@OfficialLoganK Boring, has the LLM 32K Sparse Attention problem been fixed yet?
English
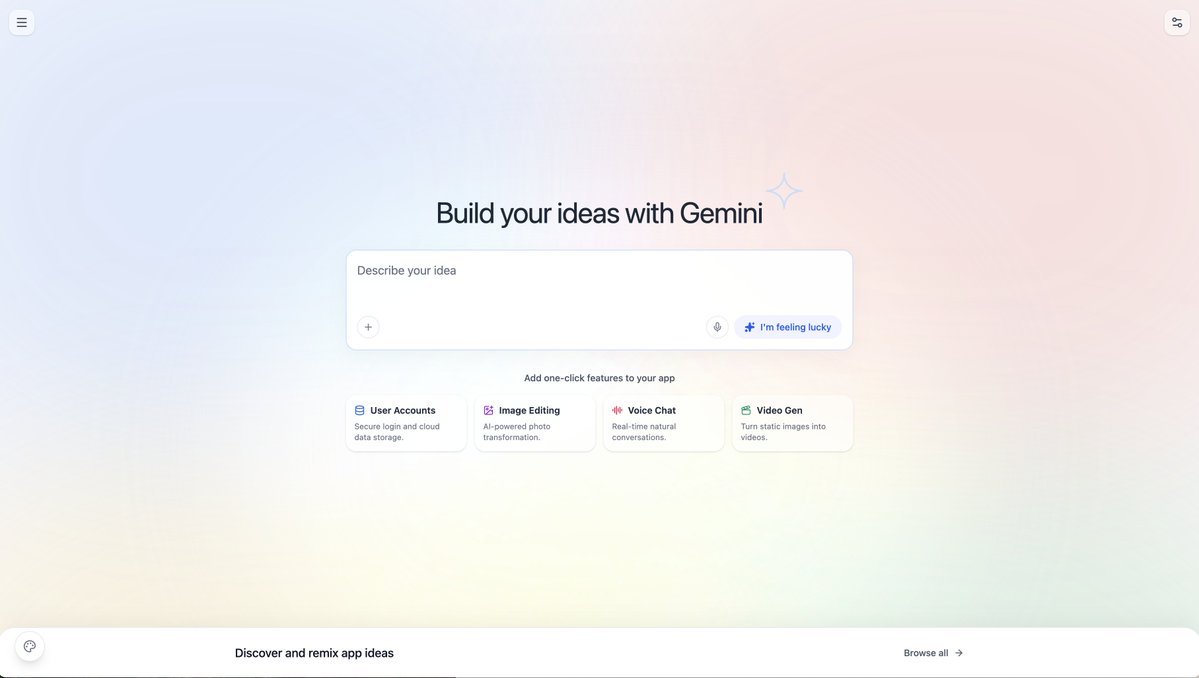
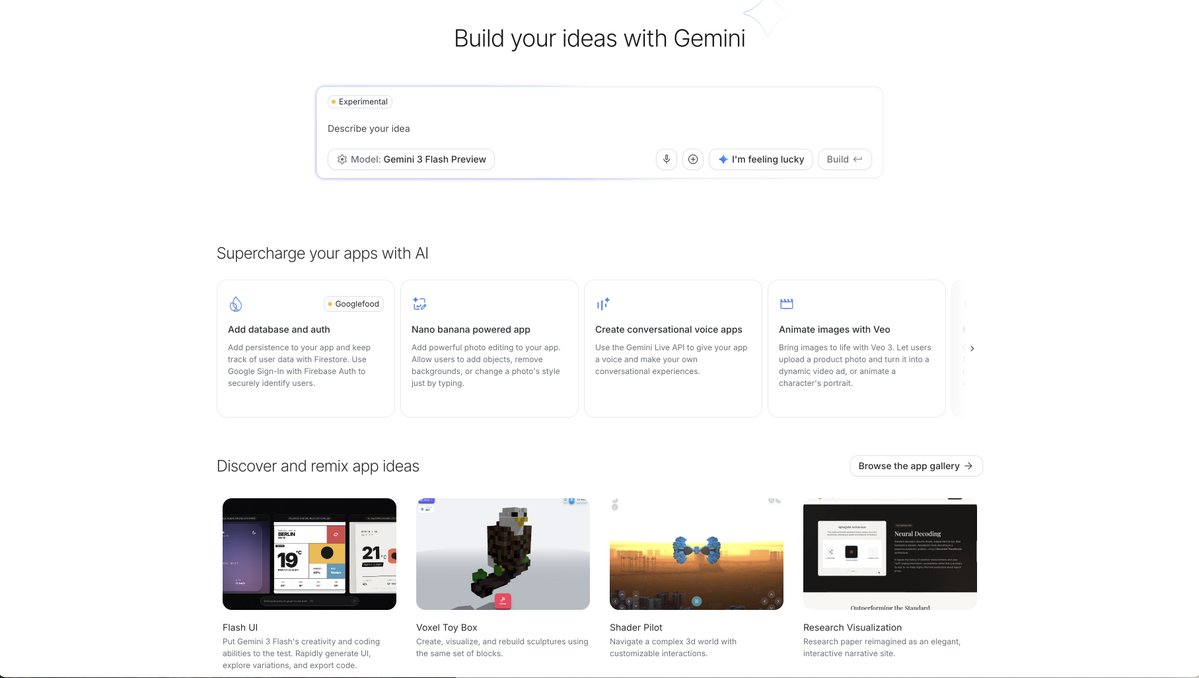
Experimenting with new AI Studio vibe coding start screens today, New vs Old. What do you think?
English
We just made paying for the Gemini API 10x easier : )
You can now upgrade to a paid Gemini API account without leaving AI Studio, track your usage, filter spend by model, and much more to come!
English

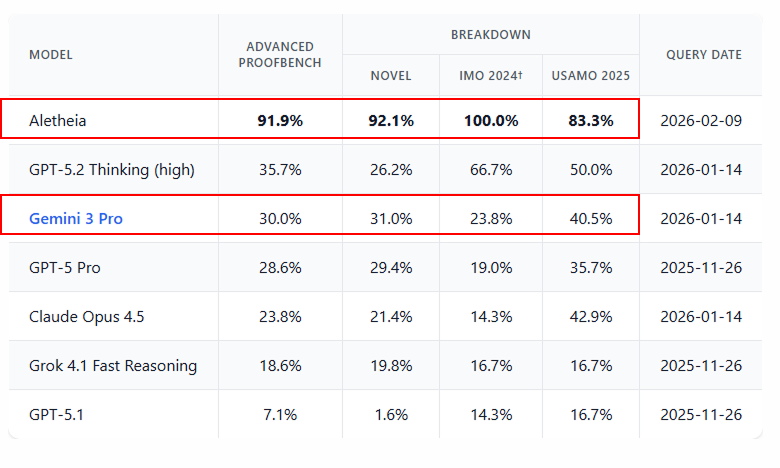
this is happening faster than i thought
DeepMind's "Aletheia" pushes gemini deep think beyond Olympiad math — reaching up to 90% on IMO-proofbench advanced and autonomously solving multiple open erdős problems
i've always believed google had stronger models, but openai pushed them to release them publicly
English

Sonnet 5 next week?
I know a guy who spoke to an engineer at Anthropic last week and asked “when Sonnet 5?”
Response:
“Can’t say exactly, but very very soon.”
It can’t be long now.

Dan Shipper 📧@danshipper
@inductionheads Not true
English

Upcoming Gemini 3 Pro GA one-shot
Prompt: "Create a SVG of a horse riding an astronaut"
It's a bit better than other models at this task...

theseriousadult@gallabytes
a horse riding an astronaut, by Claude 4.6 Opus
English

@OfficialLoganK Shall we tackle the most fundamental LLM issues first?
reddit.com/r/GeminiAI/com…
English
world builders, world explorers, world remixers
English
English

🆕 We have updated SWE-rebench with the December tasks!
SWE-rebench is a live benchmark with fresh SWE tasks (issue+PR) from GitHub every month.
Some insights:
> top-3 models right now are:
1. Claude Opus 4.5
2. gpt-5.2-2025-12-11-xhigh
3. Gemini 3 Flash Preview
> Gemini 3 Flash Preview is very strong for its low price, around $0.29 per problem
> the best open-source model is GLM-4.7, which is a big improvement compared to GLM-4.6: 40%->51% @Zai_org
> DeepSeek-v3.2 is not far behind GLM-4.7 and cheap to run ($0.25), we enabled caching after @teortaxesTex comment
> we tried running gpt-oss-120b-high and it turned out to be surprisingly good, improving from 22% to 37% compared to the standard run.
You can find the full leaderboard here (including other models like Kimi-K2-thinking, Qwen3-Coder, devstral and others):
swe-rebench.com
And feel free to write here or dm if you have questions, ideas, or complaints.

English
As we balance giving the best possible quotas and maintaining fairness between users, especially under incredible demand, we will be establishing generous weekly limits for all models. This will only affect a minority of Google AI Pro users. These limits do not apply to Google AI Ultra, which continues to be the best plan for power developers!
English