
Whatever
1.5K posts


i've been using pi + playwright + chrome, to close the loop for my agents on webapps. Is this still where it's at? are people using that chrome extension thing codex uses for computer use?
English
@lightpanda_io Can I use it instead of chrome for github.com/browser-use/br… ? Browser harness seems to work better than anything else I’ve tried and it’s getting very popular. Assuming I disable screenshot etc or use chrome instead for those commands that are incompatible
English

New blog post with everything you need to know about the Hermes integration
There is no reason you shouldn’t set up Lightpanda with chrome fallback for your web agent
lightpanda.io/blog/posts/lig…
English
@goodreads I wish you had a better, more thorough, breakdown of different non fiction genres with more books in those categories. You list every genre of fiction but confine all of non fiction to one category
English

Our annual Big Books of Summer list is here ☀️ New Maggie O'Farrell, Liane Moriarty, Marlon James, Riley Sager, and SO many more great books (including a peek ahead at fall!) 🔥
goodreads.com/blog/show/3088…
English
Whatever retweetledi

Today we're releasing ZAYA1-8B, a reasoning MoE trained on @AMD and optimized for intelligence density.
With <1B active params, it outperforms open-weight models many times its size on math and reasoning, closing in on DeepSeek-V3.2 and GPT-5-High with test-time compute. 🧵
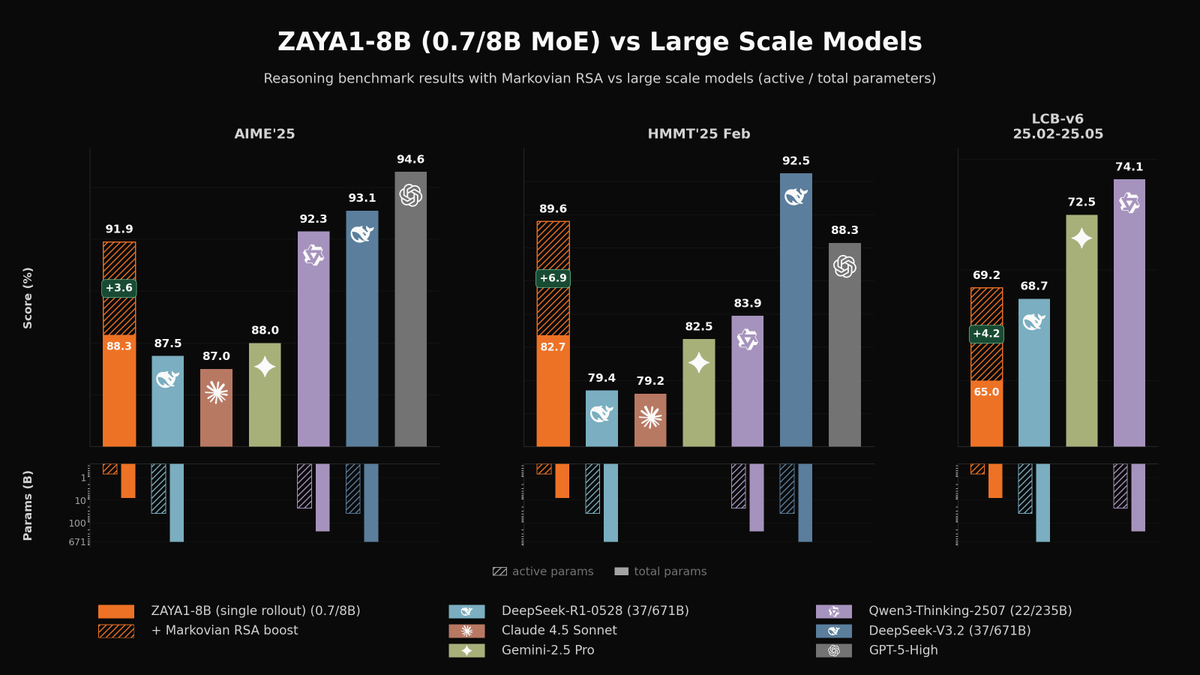
English
@ArtificialAnlys @SambaNovaAI @FireworksAI_HQ @novita_labs @togethercompute Do you do tests for quality for different providers of the same model?
English

MiniMax-M2.7 is now available across six inference providers on Artificial Analysis, with significant differentiation in speed and price
@SambaNovaAI leads on speed at 435 output tokens/s, >3x faster than any other provider. @FireworksAI_HQ, @novita_labs, @togethercompute, and @GMI_cloud have all matched @MiniMax_AI's first-party API pricing, while SambaNova is 2x higher.
Key takeaways:
➤ Fireworks and SambaNova are on the Pareto frontier for Speed vs. Price. At 127 output tokens/s and ~$0.22 per 1M tokens blended, Fireworks is ~2.2x faster than MiniMax's first-party API at the same blended price, whereas SambaNova delivers 435 output tokens/s but at ~2-3.5x the blended price of the other providers (depending on cache usage)
➤ SambaNova is the fastest provider at 435 output tokens/s, ~3.4x the next fastest provider (Fireworks at 127 output tokens/s). The remaining providers run substantially slower: MiniMax’s first-party API at 57 output tokens/s, Novita at 54, GMI at 41, and Together AI at 29
➤ Cache discounts vary across providers. Fireworks, MiniMax, Novita, and Together AI offer 80% cache hit discounts, while GMI and SambaNova do not offer a discount. For cache-heavy workloads, this can materially increase the relative pricing for GMI and SambaNova
➤ Optimal provider choice depends on workload. SambaNova may be more suited to latency-sensitive deployments, albeit at a higher cost, while Fireworks may be more suitable for high-volume workloads that are not as latency-sensitive
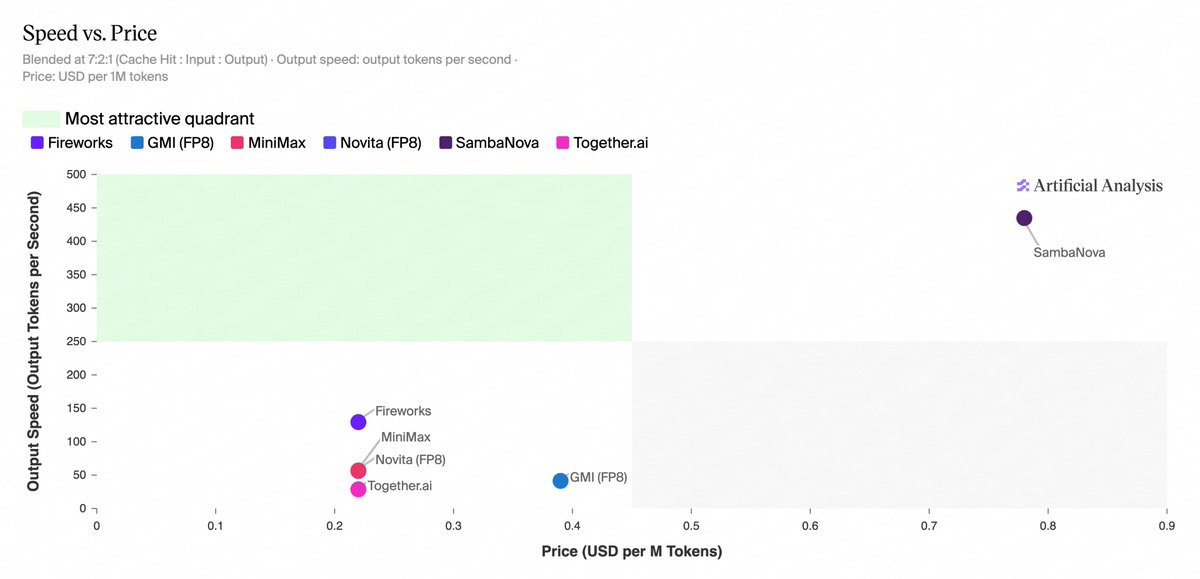
English

important note, the cache price update is meant to match the lowered cache prices of deepseek, I plan on raising the cache price once they raise theirs but my goal is to see if I can keep prices at a max of 0.80/m input, 0.09/m cache, and $1.50/m output.
We'll see how this goes but no matter what, I promise to do everything I can to run the cheapest inference available at any point in time
English


xai is the most unserious US lab lmao why would u ever release this? its a closed source model worse than open source models like why would i use this over deepseek or kimi
Artificial Analysis@ArtificialAnlys
xAI has launched Grok 4.3, achieving 53 on the Artificial Analysis Intelligence Index with improved agentic performance, ~40% lower input price, and ~60% lower output price than Grok 4.20 The release of Grok 4.3 places @xAI just above Muse Spark and Claude Sonnet 4.6 on the Intelligence Index, and a 4 points ahead of the latest version of Grok 4.20. Grok 4.3 improves its Artificial Analysis Intelligence Index score while reducing cost to run the benchmark suite. Key Takeaways: ➤ Grok 4.3 improves on cost-per-intelligence relative to Grok 4.20 0309 v2: it scores higher on the Intelligence Index while costing less to run the full benchmark suite. Grok 4.3 costs $395 to run the Artificial Analysis Intelligence Index, around 20% lower than Grok 4.20 0309 v2, despite using more output tokens. This makes it one of the lower-cost models at its intelligence level ➤ Large increase in real world agentic task performance: The largest single benchmark improvement is on GDPval-AA, where Grok 4.3 scores an ELO of 1500, up 321 points from Grok 4.20 0309 v2’s score of 1179 Grok 4.3, surpassing Gemini 3.1 Pro Preview, Muse Spark, Gpt-5.4 mini (xhigh), and Kimi K2.5. Grok 4.3 narrows the gap to the leading model on GDPval-AA, but still trails GPT-5.5 (xhigh) by 276 Elo points, with an expected win rate of ~17% against GPT-5.5 (xhigh) under the standard Elo formula ➤ Grok 4.3’s performs strongly on instruction following and agentic customer support tasks. It gains 5 points on 𝜏²-Bench Telecom to reach 98%, in line with GLM-5.1. Grok 4.3 maintains an 81% IFBench score from Grok 4.20 0309 v2 ➤ Gains 8 points on AA-Omniscience Accuracy, but at the cost of lower AA-Omniscience Non-Hallucination Rate of 8 points, so Grok 4.20 0309 v2 still leads AA-Omniscience Non-Hallucination Rate, followed by MiMo-V2.5-Pro, in line with Grok 4.3 Congratulations to @xAI and @elonmusk on the impressive release!
English
@mkurman88 If you don’t need zdr and don’t mind sending data to china deepseeks api directly is the best, although their api has quirks openrouter doesn’t have
English

DeepSeek via OpenRouter can be costly when an unexpected provider switch occurs. $3 in total when using the DeepSeek provider (caching++), then the next $3 for 3 prompts when changed to SilliconFlow (no cache lol).
I am adding the option to include and/or exclude providers in Zorai. It's been an expensive lesson!
English
@karminski3 I had this issue in openwebui, Deepseek pro wrote the fix.
openwebui.com/posts/deepseek…
English

给大家说下目前使用 DeepSeek-V4 (pro/flash) 的最需要注意的问题. 本身其实并不算 bug, 但是却很致命.
问题大概是这样的, 在请求 DeepSeek API 或者 terminal coding agent (claude code, kimi cli 等) / AI IDE (cursor 等) 用 DeepSeek 的时候偶尔会遇到报错:
HTTP 400
{"error":{"message":"The `reasoning_content` in the thinking mode must be passed back to the API.","type":"invalid_request_error","param":null,"code":"invalid_request_error"}}
这个报错的意思是, 请求 DeepSeek API 必须在 tool_call 的时候回传 reasoning_content 这个字段. 听上去没问题, 开了思考模式那肯定要把 reasoning_content 作为上下文回传.
但是来了, 如果任务的这一步制定的 tool_call 过于显而易见, deepseek 返回的 reasoning_content 其实是空字符串. 这就导致了有些写代码的 IDE 直接过滤掉了这个字段, 不回传, 导致 DeepSeek API 报错, 编码任务或者 Agent 就直接挂了.
DeepSeek-V4 API会不会真的有的时候 reasoning_content 空字符串? 答案是会的, 我专门构建了个 POV 场景, 复现概率高达 59%.
那么出现 reasoning_content 为空字符串的时候该怎么办?
经过验证, 答案是必须原样传回去. 即也在 context 中保留这个值为空字符串的字段. 不能是空对象, 也不能丢掉.
那就原样传回去呗? 废什么话呀?
关键是, 现有的各种 terminal coding agent 或者 AI IDE 这并不是默认行为, 它们大部分的默认行为是直接把字段丢掉了, 导致 DeepSeek-V4 API 报错.
所以现在的解决方法是, 要么等 IDE 的官方修复, 要么你用的 IDE 或者 coding agent 是开源的, 自己 fork 一个版本魔改.
另外, 如果你的 Agent 项目要使用 DeepSeek-V4 也要注意这个坑. 避免运行到一半直接报错退出.
以及, 报错重试不太行的, 因为 DeepSeek-V4 在我 POV 这个场景, 59% 的概率都会为空. 如果重试次数为 3, 那偶尔都不够用. 所以还是老实的把问题解决为好.
#deepseek #deepseekv4

中文

Ngl, which model release are you waiting for the most right now?

English

What's the best ai-assisted coding setup in neovim?
Need to seamlessly mix writing code by hand, agentic work, diff review, and file browsing.
English
@iamdothash Can it stream my autogenerated playlists from YouTube music/spotify etc?
English

Look how pleasant cliamp is. Spend 10 seconds of your time and enjoy it.
English
@ufukaltinok @evilrabbit_ Ever consider turning this into a pi extension too?
English

@evilrabbit_ Add magic context, 10x your opencode experience.
github.com/cortexkit/open…
English



@Presidentlin @deepseek_ai Tbf Anthropic didn’t care about math until relatively recently maybe ~opus 4.5ish
English

@deepseek_ai Victory
Whales are smarter than ants, I guess
15.18% vs 5.80%
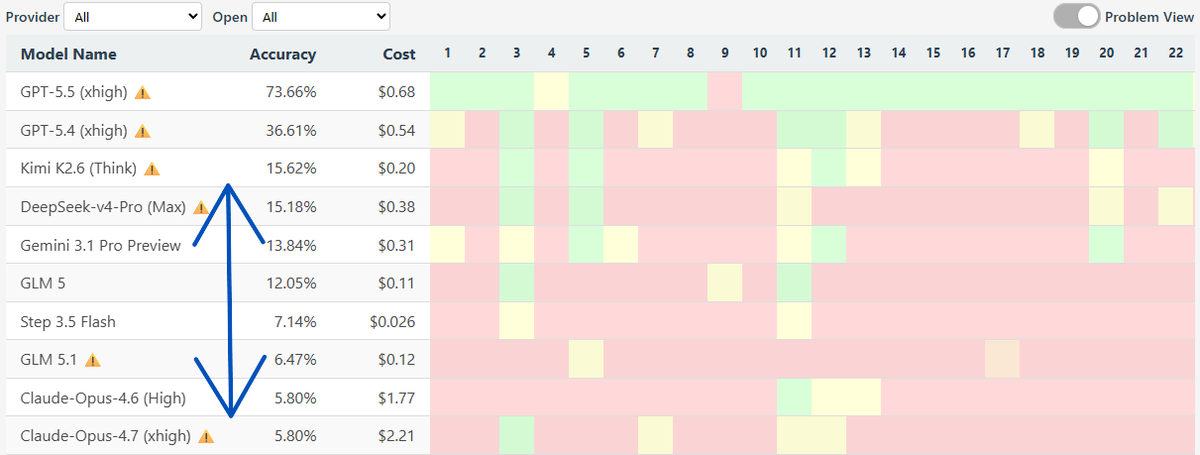
Lisan al Gaib@scaling01
holy IQ mog
English
@scaling01 Don’t think is going to happen at least until the non preview v4 model comes out
English

Scores I would like to see from DeepSeek-V4 to confirm it being less than 6 months behind frontier models
ARC-AGI-1: ~75%
ARC-AGI-2: ~35%
GSO: ~26%
METR: 4.5-5 hours
WeirdML: ~63%
basically Opus 4.5 / GPT-5.2 scores
English

@tanishqk the free mcp includes our extract api too parallel.ai/blog/parallel-…
English
We've made our search MCP super easy to use. No need for an account or API keys. And it's free!
claude code prompt: "add free search.parallel.ai/mcp - no auth needed. add permissions.allow for both tools and deny native web search and fetch"
codex cli prompt: "edit ~/.codex/config.toml to add web_search = "disabled" and add the free mcp search.parallel.ai/mcp - no auth needed"
Parallel Web Systems@p0
The best web search for agents is now free. Upgrade to Parallel's web search tools in any MCP-supported tool or agent, for free, in under 60 seconds. No account. No API keys. Zero cost. docs.parallel.ai/integrations/m…
English
Whatever retweetledi

🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice.
Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today!
📄 Tech Report: huggingface.co/deepseek-ai/De…
🤗 Open Weights: huggingface.co/collections/de…
1/n

English
@EpochAIResearch Surprised that 100K household is considered high income, do you have any data on other, higher, income brackets?
English

Yesterday, we shared a chart showing 80% of Claude users live in $100k+ households, more than any other major AI service.
But Claude’s user base is smaller than other AI services, so this isn’t the same as being the most popular service among high-income households.
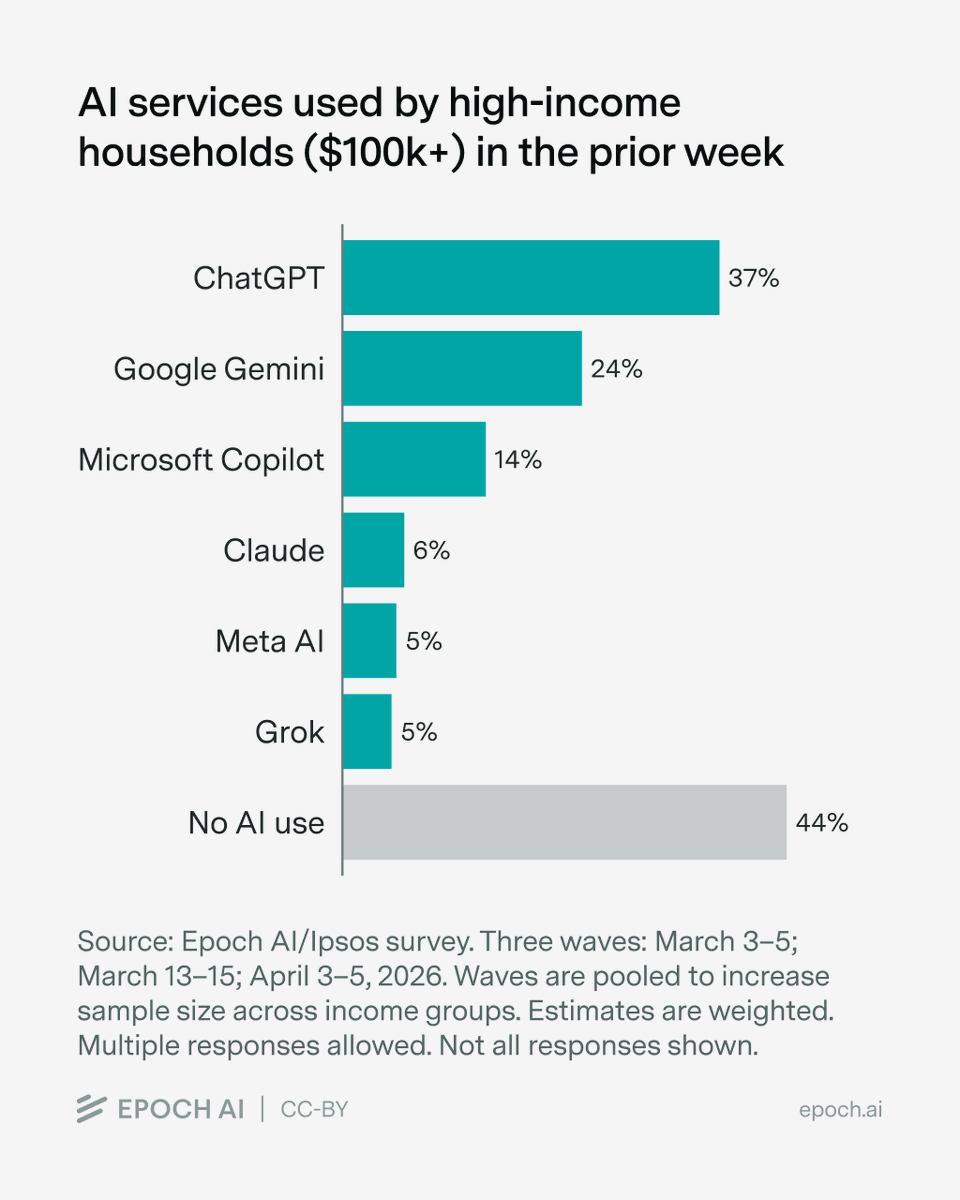
Epoch AI@EpochAIResearch
80% of US adults who report using Claude in the previous week live in households earning $100,000 or more a year, compared to 37% of Meta AI users. Other major providers cluster in a relatively narrow band, with 56–64% of users in $100,000+ households.
English

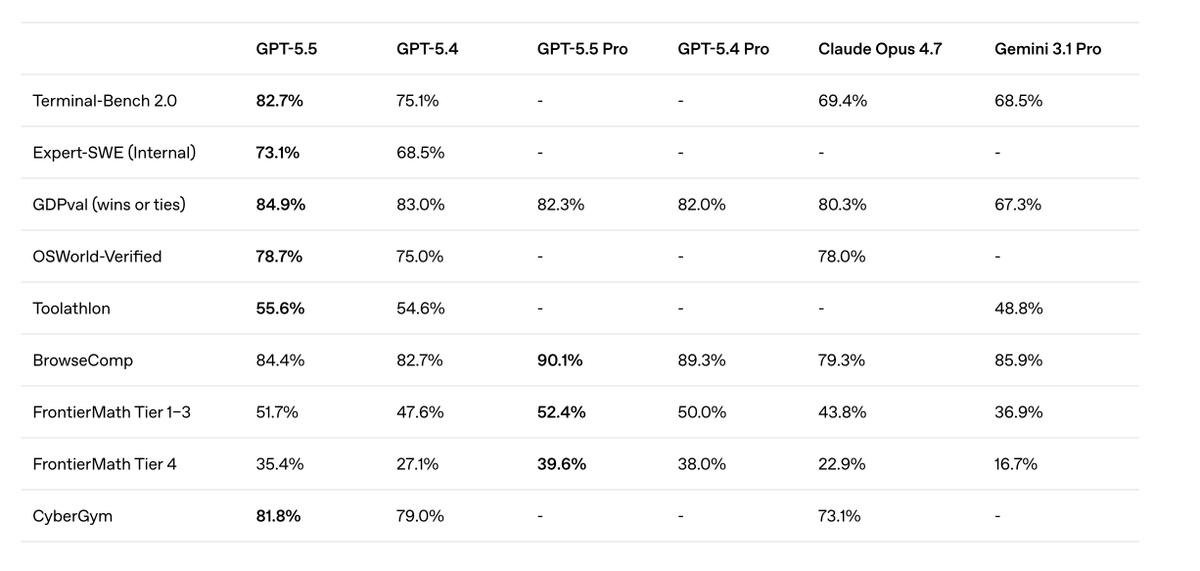
Also, a detail some of you may have missed:
Anthropic’s gated Mythos model scored 83% on CyberGym.
OpenAI just dropped GPT-5.5 at 82%.
Except GPT-5.5 is actually available for people to use.
English