@RishiBommasani@percyliang The analogy for cloud vs local would be restaurant vs takeout. At the restaurant you better behave otherwise you get kicked out. At home you eat your food however you want.
I like the analogy. Notably in the restaurant world, only one of these even is afforded the word open. Option 3 is an "open kitchen" restaurant. (I don't think all such restaurants would appreciate the customer shouting at the chef but let's put that aside)
Though maybe there is some mismatch in the analogy:
- Option 1 is just "you get the food". Analogue is "you get the model". This probably collapses open weight with everything less open than it since we don't distinguish weights vs API in food as far as I can imagine, and certainly there is no local vs. cloud distinction for food
- Option 2 is "you get the food and recipe". I think this is a bit of a mismatch with open source since recipe is transparency (i.e. information about how to build) but not the actual ingredients themselves (whereas you might/do have the dataset in some stronger sense with open-source). But, worth noting in both cases that you are not given the cooking infrastructure or compute infrastructure to consume the ingredients and produce the food.
One other subtlety is open kitchen restaurants are not fully open due to constraints: chefs do prepwork so that the cook time in front of the diner is reasonable length (e.g. omakase restaurant needs to prepare rice in advance). That's fine because the customer doesn't need 100% open and to see every gory detail, but not fine for researchers.
I find myself repeatedly explaining the difference between open-weight (DeepSeek), open-source (Olmo), open-development (Marin). Let's see if this restaurant analogy helps:
- Open-weight: food is made behind closed doors, server brings you the dish
- Open-source: food is made behind closed doors, server brings you the dish and the recipe
- Open-development: you see the chef make the dish in the kitchen (and can shout suggestions while its cooking)!
@MatthewBerman Sure about this? Given the current reproducibility crisis in ML research, I doubt that humans would achieve a much higher replication score.
Which model won?
Turns out Claude 3.5 Sonnet leads the pack, achieving a ~21% replication score on PaperBench!
This is impressive, but, it shows there's still a gap compared to human PhD-level experts.
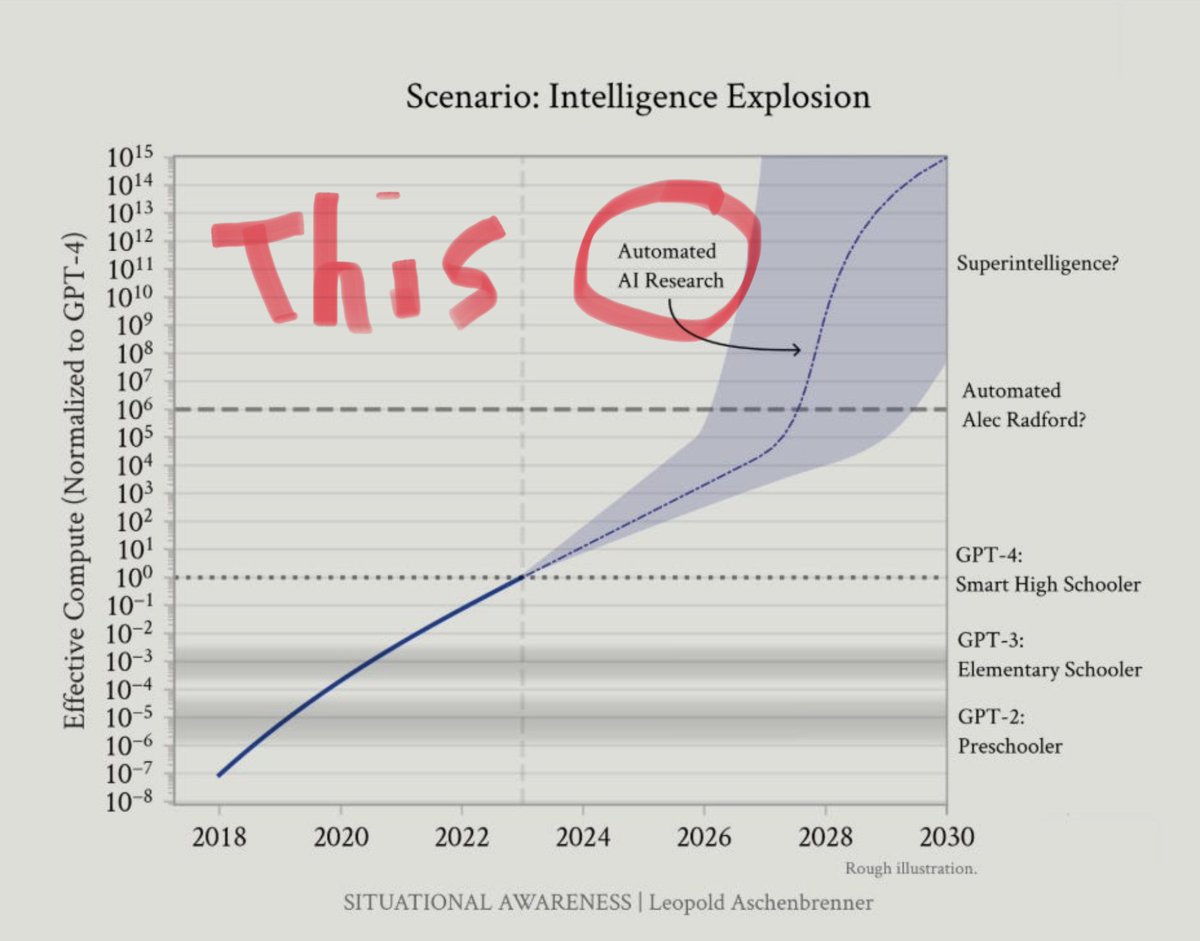
.@OpenAI dropped a new research paper showing AI agents are now capable of replicating cutting-edge AI research papers from scratch.
This is one step closer to the Intelligence Explosion: AI that can discover new science and improve itself.
Here’s what they learned: 🧵
4/ In academia, the work is very different. PhD students or even undergraduates are the ones doing most the actual research work. But as a PhD student, you need to decide whether you prioritize the project work over your own PhD work (papers and thesis).
3/ LLMs and other foundation models are no longer research artifacts but products. Frontier models are developed by dedicated teams of +100 people specialized across the whole stack (from low level hardware optimization over data to ML and UX topics).
I am currently working on an end-to-end OCR pipeline for research papers. Open Research Assistant needs high a quality OCR pipeline to work properly, so I really have to solve the OCR problem before making more progress in the OpenRA project.
Good news: paper OCR will be solved soon.
@XYOU@pjox13 We're happy to run a training on the same conditions, but you can find details on the model setup (we haven't posted the exact training script yet) and the exact eval code on our blogpost
@gui_penedo@pjox13 We will release a filtered version of Colossal OSCAR soon. Is your training and evaluation script somewhere available? I would love to do the comparison with that version.
@mark_cummins For Germany, we have ~50B tokens of court decisions but that are only the publicly available ones and that represent ~1% of all court decisions. However, you won't need all for LLM training due to high duplicate ratio. @mlissner might have the US numbers.
@XYOU One other thing I forgot to include was court documents. Seems like you might know about that. Do you have any data on how many publicly accessible court documents exist?
@gui_penedo Awesome work. Will the remaining models also be released? And from your experience what model and data size do you need to see a significant difference in performance?
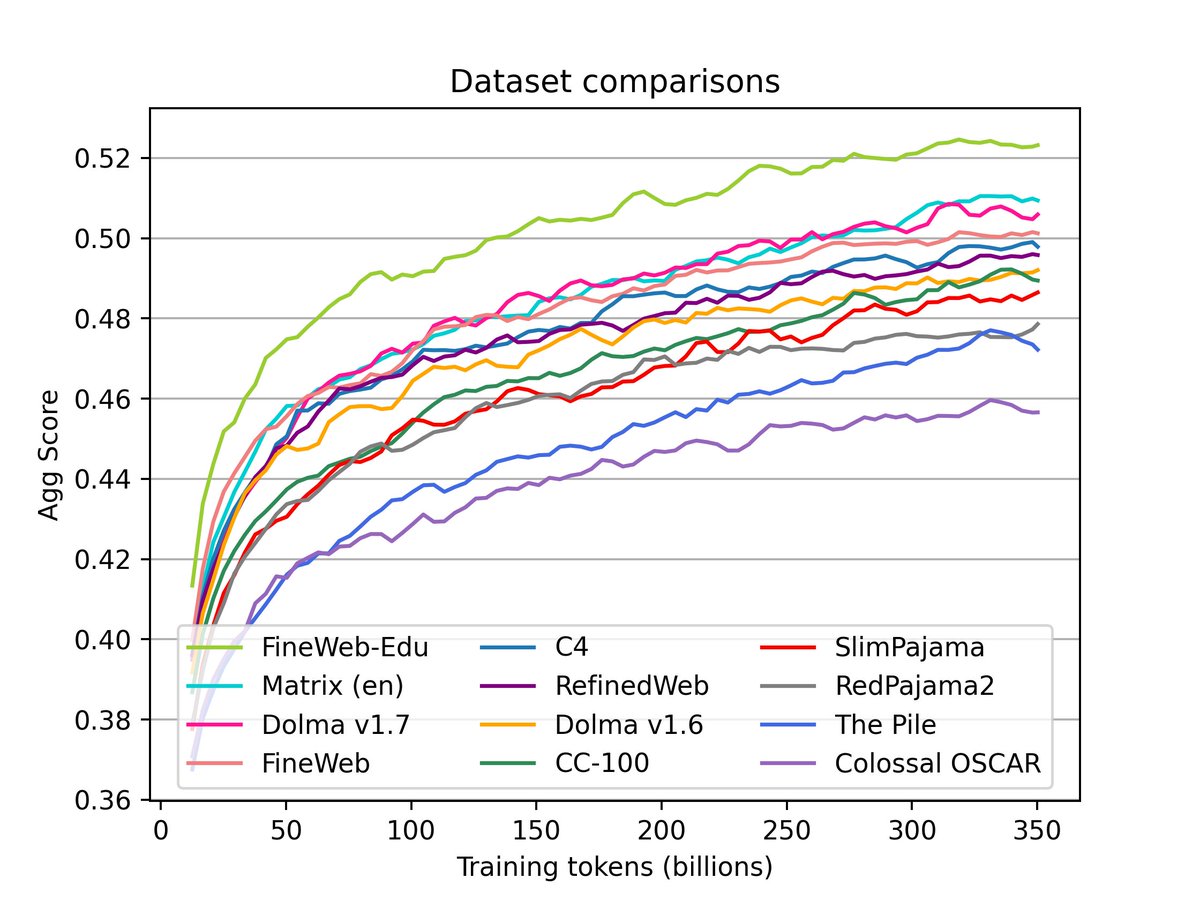
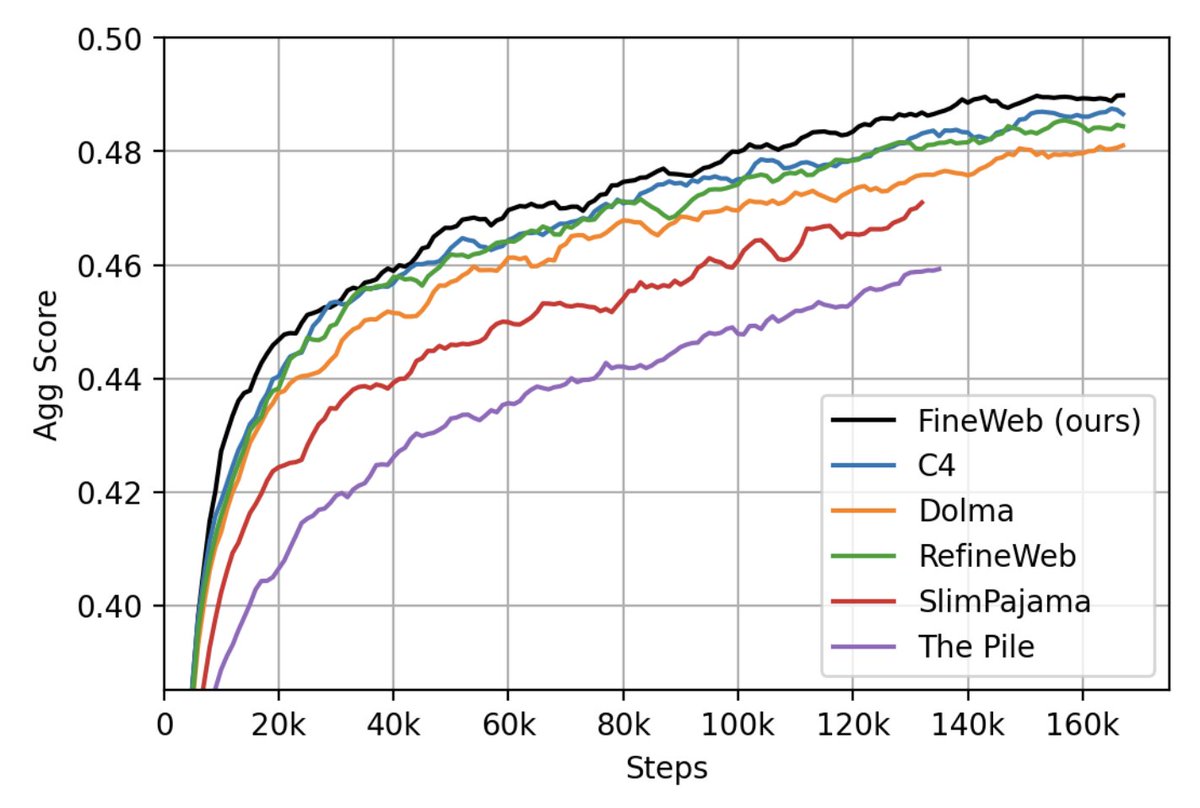
We have just released 🍷 FineWeb: 15 trillion tokens of high quality web data.
We filtered and deduplicated all CommonCrawl between 2013 and 2024.
Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!
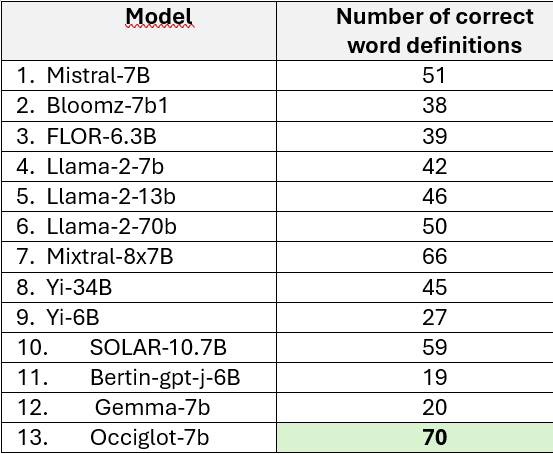
We have some great new evaluation results to share that provided by the community.
The German Occiglot model is the best in class on ScandEval.
scandeval.com/german-nlg/
And our Spanish model achieves SOTA results in lexical word understanding.
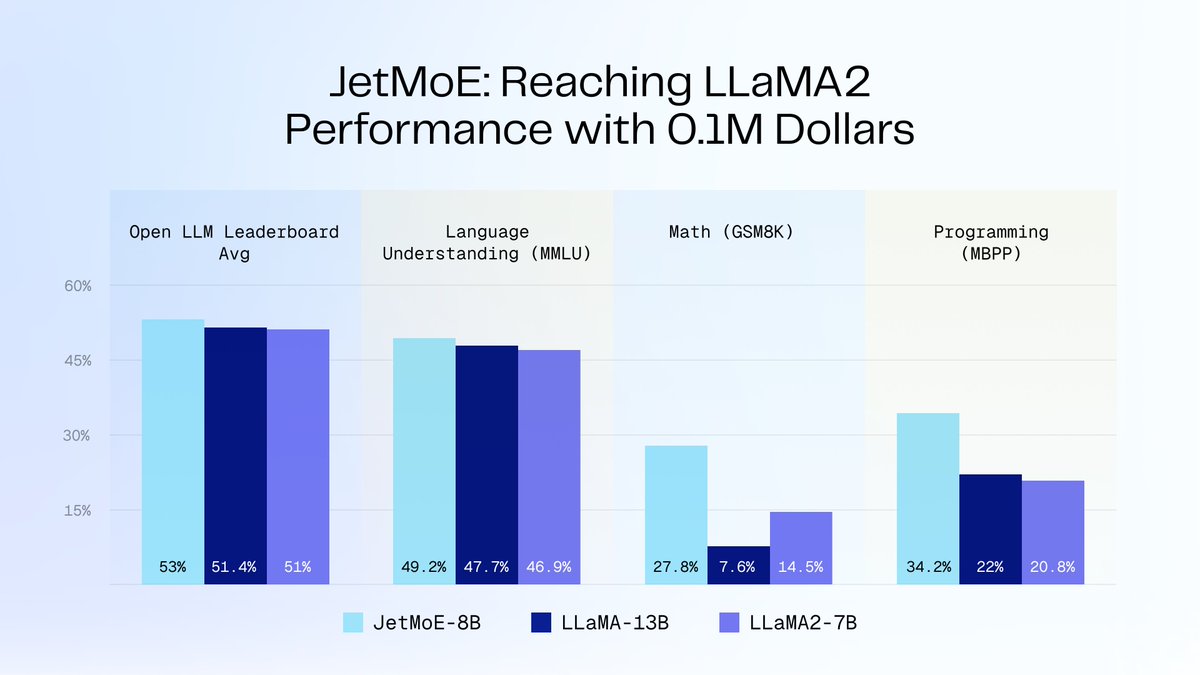
Training LLMs can be much cheaper than previously thought.
0.1 million USD is sufficient for training LLaMA2-level LLMs🤯
While @OpenAI and @Meta use billions of dollars to train theirs, you can also train yours with much less money.
Introducing our open-source project JetMoE: research.myshell.ai/jetmoe
A thread 🧵
@BramVanroy@VSC_HPC If your cluster uses slurm you can catch the kill signal and save a checkpoint before that. See this script for an example. Line 14 and 293-300 do the magic. #file-bigscience-deepspeedmeg-example-sbatch-L293-298" target="_blank" rel="nofollow noopener">gist.github.com/malteos/71635c…
@SebastianB929 Opengptx is an official government funded research project. Occiglot is a loose group of individuals from different organizations without any formal ties. We call it a research collective. You may also call it simply a discord server. And yes, the website needs to be improved.
@ZedDou1@occiglot As mentioned in the readme, we suspect that this is due to the benchmarks being machine translated from English and based on English prompts.
@occiglot Nice to see multilinguality more and more addressed, great work!
I do have a question though, how would you explain the gap in the evals in the 5 languages between your models (base and instruct) and the Mistral models which are mostly English? 🤔
Today, we are announcing Occiglot!
A large-scale collaborative research collective focusing on open-source European LLMs.
We invite anybody working on multilingual datasets, benchmarks, or models to get in touch/join our discord.
occiglot.github.io/occiglot/posts…
@burkov “SOLAR-10.7B incorporates the innovative Upstage Depth Up-Scaling. We then integrated Mistral 7B weights into the upscaled layers, and finally, continued pre-training for the entire model.” Honest question: how do you start with pretrained weights from a model of diffident size?