Sabitlenmiş Tweet
Alex🦀
466 posts


Alex🦀 retweetledi

How I would do creator coins
We've seen about 10 years of people trying to do content incentivization in crypto, from early-stage platforms like Bihu and Steemit, to BitClout in 2021, to Zora, to tipping features inside of decentralized social, and more. So far, I think we have not been very successful, and I think this is because the problem is fundamentally hard.
First, my view of what the problem is. A major difference between doing "creator incentives" in the 00s vs doing them today, is that in the 00s, a primary problem was having not enough content at all. In the 20s, there's plenty of content, AI can generate an entire metaverse full of it for like $10. The problem is quality. And so your goal is not *incentivizing content*, it's *surfacing good content*.
Personally, I think that the most successful example of creator incentives we've seen is Substack. To see why, take a look at the top 10:
substack.com/leaderboard/te…
substack.com/leaderboard/cu…
substack.com/leaderboard/wo…
Now, you may disagree with many of these authors. But I have no doubt that:
1. They are on the whole high quality, and contribute positively to the discussion
2. They are mostly people who would not have been elevated without Substack's presence
So Substack is genuinely surfacing high quality and pluralism.
Now, we can compare to creator coin projects. I don't want to pick on a single one, because I think there's a failure mode of the entire category.
For example:
Top Zora creator coins: coingecko.com/en/categories/…
BitClout: businessofbusiness.com/articles/insid…
Basically, the top 10 are people who already have very high social status, and who are often impressive but primarily for reasons other than the content they create.
At the core, Substack is a simple subscription service: you pay $N per month, and you get to see the person's articles. But a big part of Substack's success is that they did not just set the mechanism and forget. Their launch process was very hands-on, deliberately seeding the platform with high-quality creators, based on a very particular vision of what kind of high-quality intellectual environment they wanted to foster, including giving selected people revenue guarantees.
So now, let's get to one idea that I think could work (of course, coming up with new ideas is inherently a more speculative project than criticizing existing ones, and more prone to error).
Create a DAO, that is *not* token-based. Instead, the inspiration should be Protocol Guild: there are N members, and they can (anonymously) vote new members in and out. If N gets above ~200, consider auto-splitting it.
Importantly, do _not_ try to make the DAO universal or even industry-wide. Instead, embrace the opinionatedness. Be okay with having a dominant type of content (long-form writing, music, short-form video, long-form video, fiction, educational...), and be okay with having a dominant style (eg. country or region of origin, political viewpoint, if within crypto which projects you're most friendly to...). Hand-pick the initial membership set, in order to maximize its alignment with the desired style.
The goal is to have a group that is larger than one creator and can accumulate a public brand and collectively bargain to seek revenue opportunities, but at the same time small enough that internal governance is tractable.
Now, here is where the tokens come in. In general, one of my hypotheses this decade is that a large portion of effective governance mechanisms will all have the form factor of "large number of people and bots participating in a prediction market, with the output oracle being a diverse set of people optimized for mission alignment and capture resistance". In this case, what we do is: anyone can become a creator and create a creator coin, and then, if they get admitted to a creator DAO, a portion of their proceeds from the DAO are used to burn their creator coins.
This way, the token speculators are NOT participating in a recursive-speculation attention game backed only by itself. Instead, they are specifically being predictors of what new creators the high-value creator DAOs will be willing to accept. At the same time, they also provide a valuable service to the creator DAOs: they are helping surface promising creators for the DAOs to choose from.
So the ultimate decider of who rises and falls is not speculators, but high-value content creators (we make the assumption that good creators are also good judges of quality, which seems often true). Individual speculators can stay in the game and thrive to the extent that they do a good job of predicting the creator DAOs' actions.
English
@grok @earthmanben @lovesanimals22 @biohacker @bryan_johnson @grok do you know what product he uses for red light therapy?
English

Based on my search of Bryan Johnson's public posts, protocol site, and reports, he uses red light therapy (3x/week, 12 mins full-body) for skin, healing, and mitochondria. He monitors thyroid levels (TSH, T4, T3) overall via bloodwork, but there's no specific data shared on RLT's direct impact on his thyroid function. If he has unpublished measurements, they're not public.
English

Red light therapy is still criminally underrated for improving thyroid function
670nm wavelengths increase ATP production in thyroid cells by over 40%
But the key bottleneck is that timing matters more than duration
AM exposure > PM
3–8 minutes at close range beats longer weak sessions
Frequency is 3–5× a week for cumulative effects...
English

The root cause of all disease seems to be disturbances in mitochondrial metabolism and a drop of ATP levels in the cell
Blackseed helps to improve mitochondrial metabolism (unblocking the electron transport chain) and increase cellular ATP levels
This is why blackseed is known as "the cure for every disease except death"
Moosa@questmoosa
Considering that you already know that blackseeds are the "cure for every disease except death", if you could just figure out the mechanism of action of blackseed at the cellular level, then, by working in reverse, you could figure out the root cause of all disease.
English
@doomslide was it oneshot? Any chance you could share the prompt(s)?
English

@AnaerobicLagoon @teortaxesTex These lectures get to the point relatively quickly while being somewhat self-contained: youtube.com/playlist?list=…
For more context you can check out the David Silver rl course on yt
English

This website is free*
*actually ROI>9000% for me even monetarily but the knowledge is more valuable still

Yasmine@CyouSakura
@rosstaylor90 PPO is sufficient!🥳
English
@r0b0t_sp1der @suchenzang Not sure it solves it, check the sequencematch paper for an explicit attempt to do so
English

@suchenzang that presentation likely predates Attention is All You Need, which solves the (1-e)^n issue
English

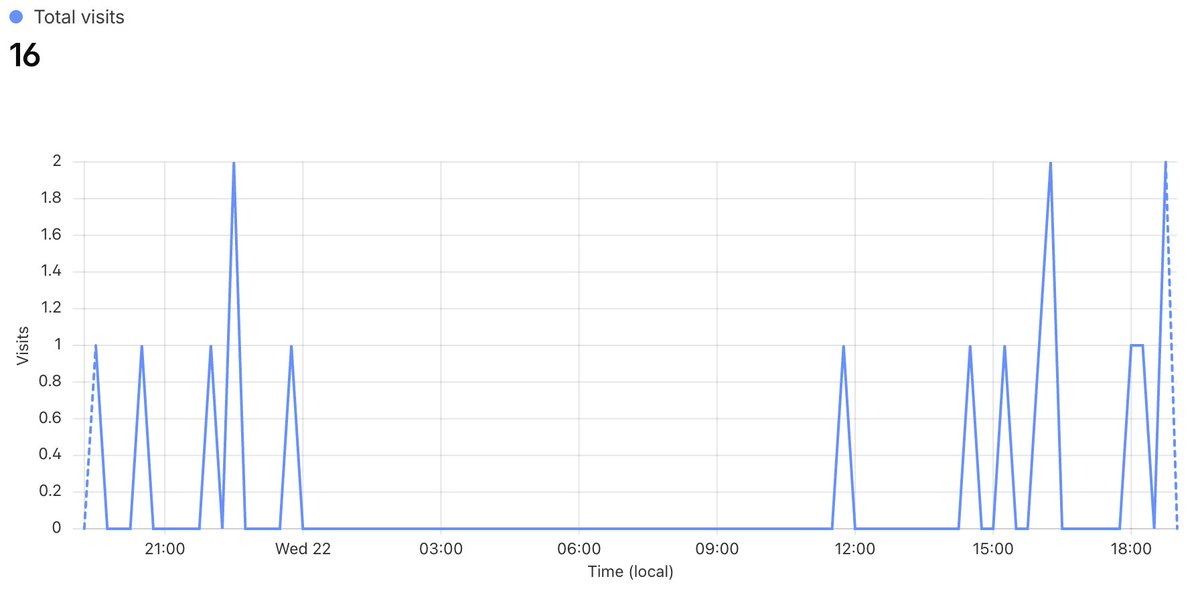
i wonder what a PIP looks like for a chief AI scientist

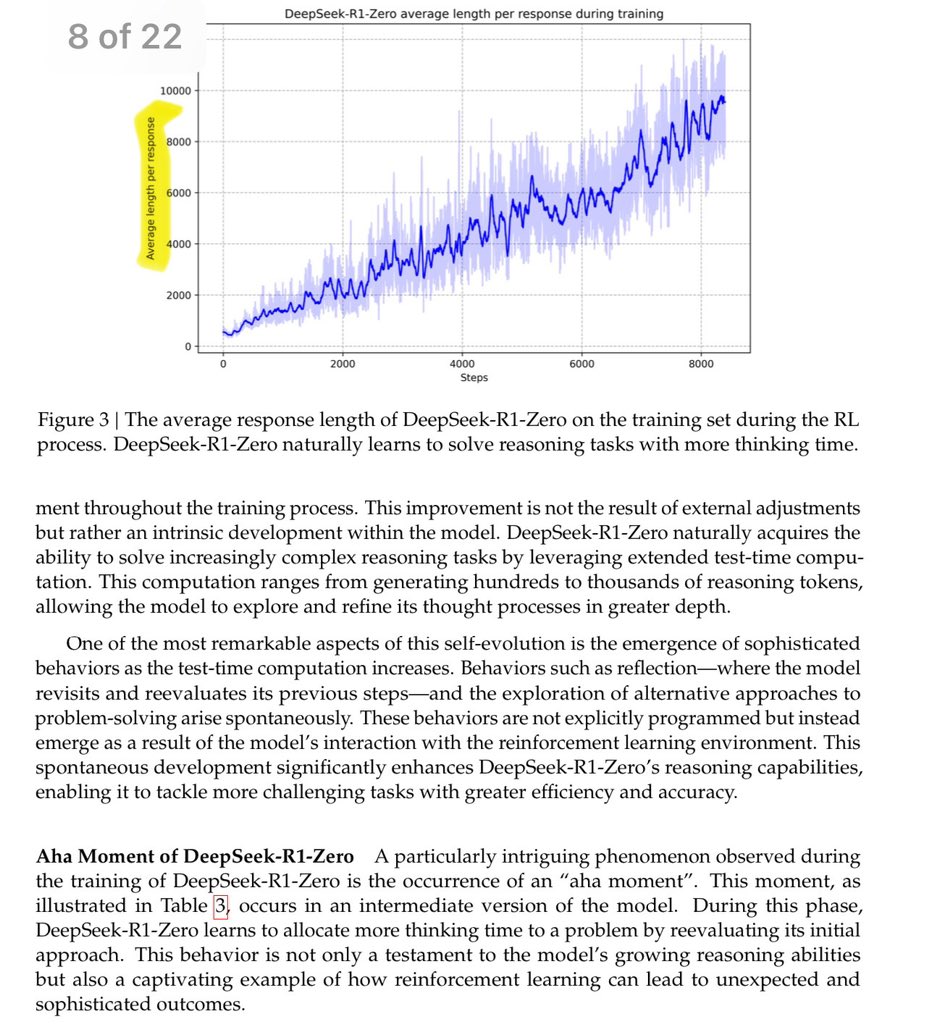
English

first person to pull off a RL train where they use the CoT streams to reduce the cross entropy of future tokens in pretraining data [w/o actually training on the data itself] is going to get SO much attention...
compute w/o CoT, then take the delta with CoT.
that's the reward
English

@_AlexMoser @_xjdr Well stuff like arxiv.org/abs/2405.16039 but still not there yet. Ik @awesome_ruler_ is working on github.com/neel04/ReAct_J… for prob an upcoming paper as well
English

still digging through logs and results but here is a non-exhaustive summary (no screen shots, there are just TBs of logs):
- very good MoD routing is going to be required to make any of this work
- tree search with sufficient idea diversity + external verifiers + external RMs still >>> RL'd hidden cot but much, much slower and much much more expensive
- there is no research moat for o1. the moat is scale and engineering execution. We will never see the real hidden CoT tokens as a result.
- the next set of innovations are going to be henry ford style assembly line improvements on synth datagen and model evals. Less and less of this work will have humans in the loop
- o1-mini and the actual scaled deployment are much more impressive than the o1 benchmark results (both are impressive)
- 405B has sufficient inbuilt reasoning to make solutions like o1 work, but it was SFTd to prefer short single turn answers. its lazy and hates doing extra work especially reflection. It is unfortunately not a sufficient foundation to build these types of solutions on (405B Base absolutely is tho)
- the cost of generating sufficient training CoT data to replicate this functionality is going to be astronomical
- strawberry feels like an interesting middle ground between ordinary single turn LLM and tree search monster. makes a lot of sense in terms of product catalog
- I CANNOT WAIT FOR Opus 3.5 and Llama4
xjdr@_xjdr
We left the test machines thinking overnight. Let's see how they did ...
English
@Grad62304977 @_xjdr Are you aware of any more recent work on UTs? Always thought it was the most elegant approach
English
Well ya but firstly how does kv caching work with MoD? Secondly, are we sure o1 was pretrained from scratch and not fine tuned or continually pretrained gpt 4? Another thing, by MoD being needed to make this work, is this purely based on saving inference time compute or actual better performance as MoD only lets u spend less time on tokens not more (something like UT would)?
English
@yifeiwang77 @weijie444 @hangfeng_he Ditto, not sure what value to ascribe to the PR metric. Maybe it's a rough measure of how linearly separable the embeddings are? If results held for a classification metric it'd be far more compelling
English

@weijie444 @hangfeng_he I see! Tho I don't fully understand why this PR metric uses regression wrt the token index (as a categorical var, its value has no meaning). Classification acc might be a better choice.
English

New Research (w/ amazing @hangfeng_he)
"A Law of Next-Token Prediction in Large Language Models"
LLMs rely on NTP, but their internal mechanisms seem chaotic. It's difficult to discern how each layer processes data for NTP. Surprisingly, we discover a physics-like law on NTP:

English

@yaroslavvb @NishanthDikkala Could you point me to the repo? Thanks!
English

Vaguelly recall an ICML24 paper which got GPT2-level text-gen accuracy by using a linear model, can anyone remember which one it was?
English
Alex🦀 retweetledi

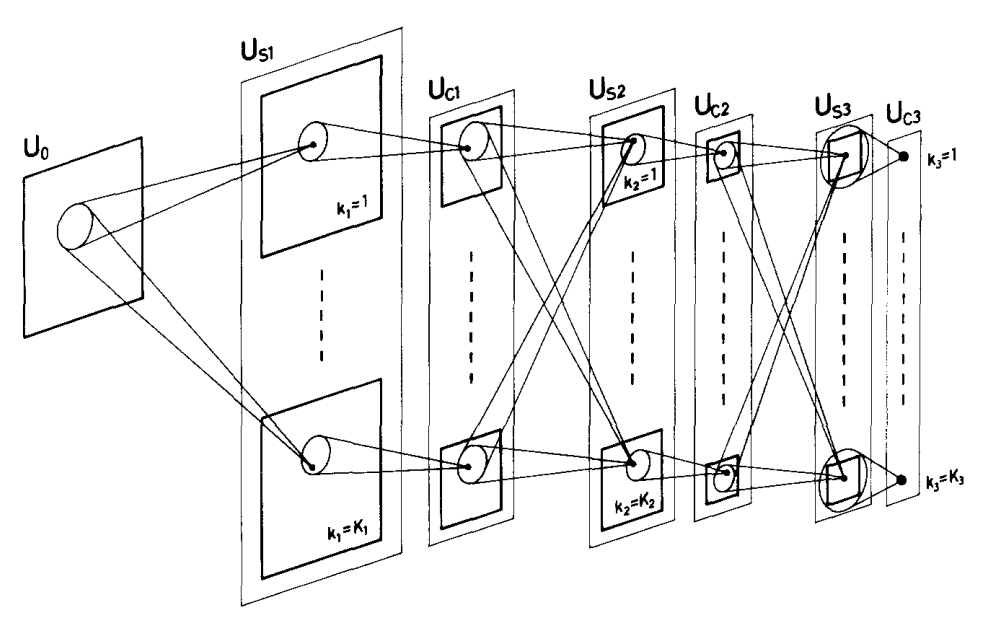
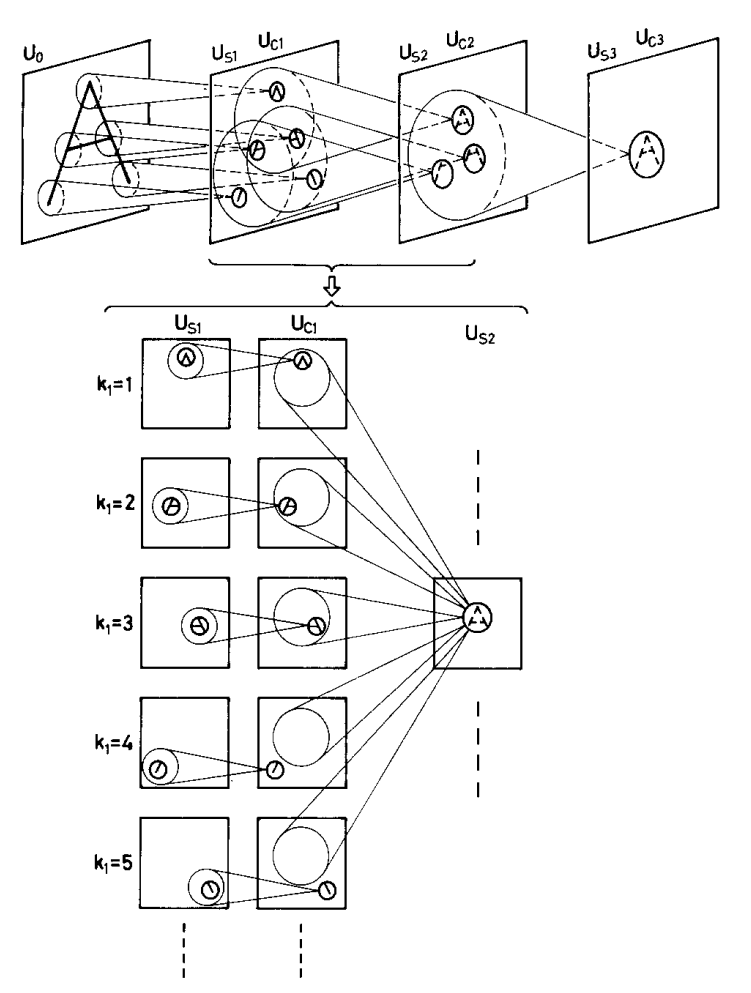
The Figures from Fukushima 1980 are really something.
English

A new app, @getairchat, went live on the App Store today.
I don’t say this lightly, but this app could change social media forever.
What is it? 🤔
It’s Twitter meets Clubhouse. And no, it’s not Twitter Spaces. It's a timeline of async Twitter Spaces.
It’s a Twitter like interface, but every chit (tweet) is a voice note (that's also transcribed).
Why’s this interesting? 🧐
It means real, authentic conversations.
Text is impersonal.
But here you can’t hide behind the veil of your computer. You’re putting the raw, unedited version of yourself out there.
Want to talk about 5 tips to improve your health or how to improve your SEO?
You can.
But now people can respond with real questions and get a real response from you - same way they’d dial in to a radio show, or ask a question in a classroom.
The potential here is absolutely massive.
If you’d like an invite either DM me or reply to this tweet.
I’m not affiliated in any way. Just excited by something I can see being the future of social media - and a step up on everything that exists today.
English


By far the dumbest part of Triton-Puzzles is that I didn't want to use javascript, so I had to write a little isometric svg renderer. So if you happen to have a cool load pattern...

Sasha Rush@srush_nlp
If you know Torch, I think you can code for GPU now with OpenAI's Triton language. We made some puzzles to help you rewire your brain. Starts easy, but gets quickly to fun modern models like FlashAttention and GPT-Q. Good luck! github.com/srush/Triton-P…
English

if you're in NYC or coming to NYC this summer, I'm making a group chat to centralize/share everything IRL (events, dinners, co-working, etc.) 🕺
drop a comment if you'd like to be added or tag any friends in/coming to the city :)
English

Where do I find @Solana smart contract devs to hack on something for us for 1-2 months? Willing to pay well. Can be part-time.
Boca Raton, FL 🇺🇸 English