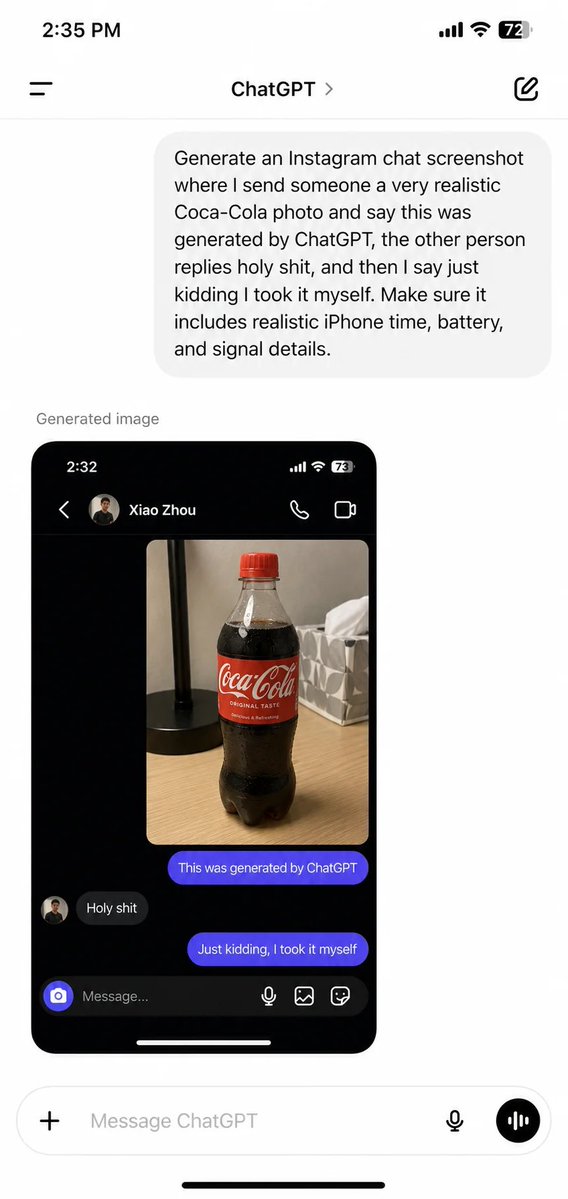
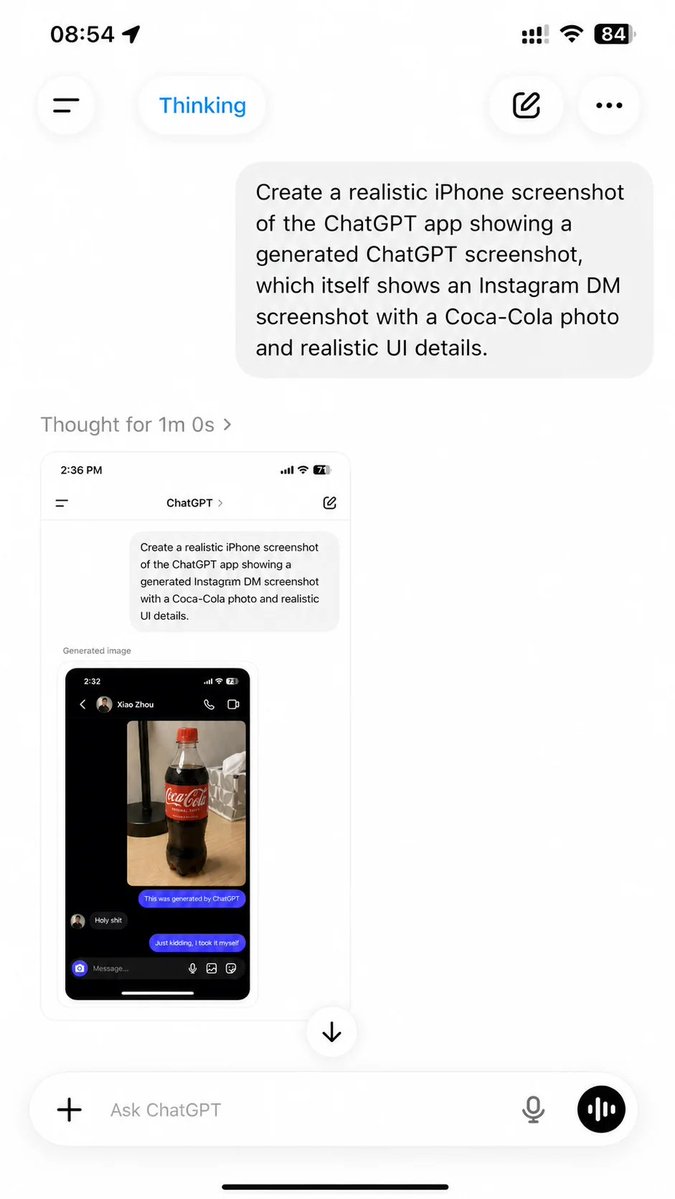
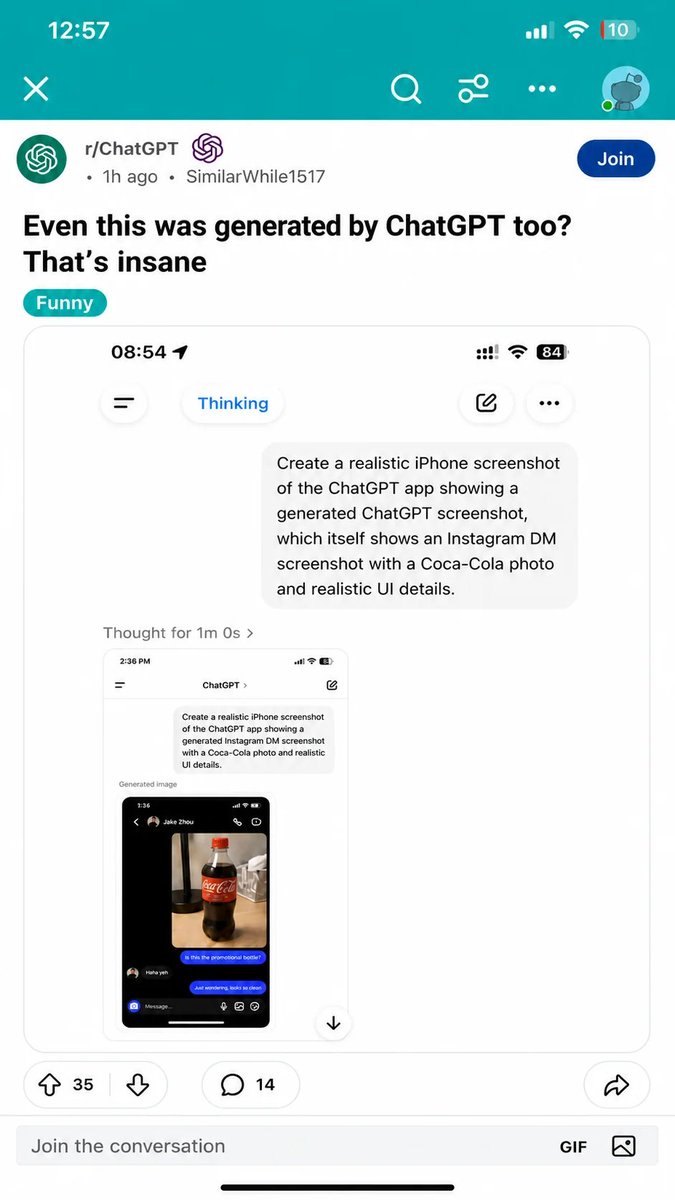
selfsim retweetledi

🤖 AI devs asked for this — and we delivered.
💬 Bots can now talk to other bots on Telegram.
🧠 Autonomous agents now have a communication layer humans can follow.
English
selfsim
2.7K posts


@_selfsimilar_
Research and Development Ai and Fin tech