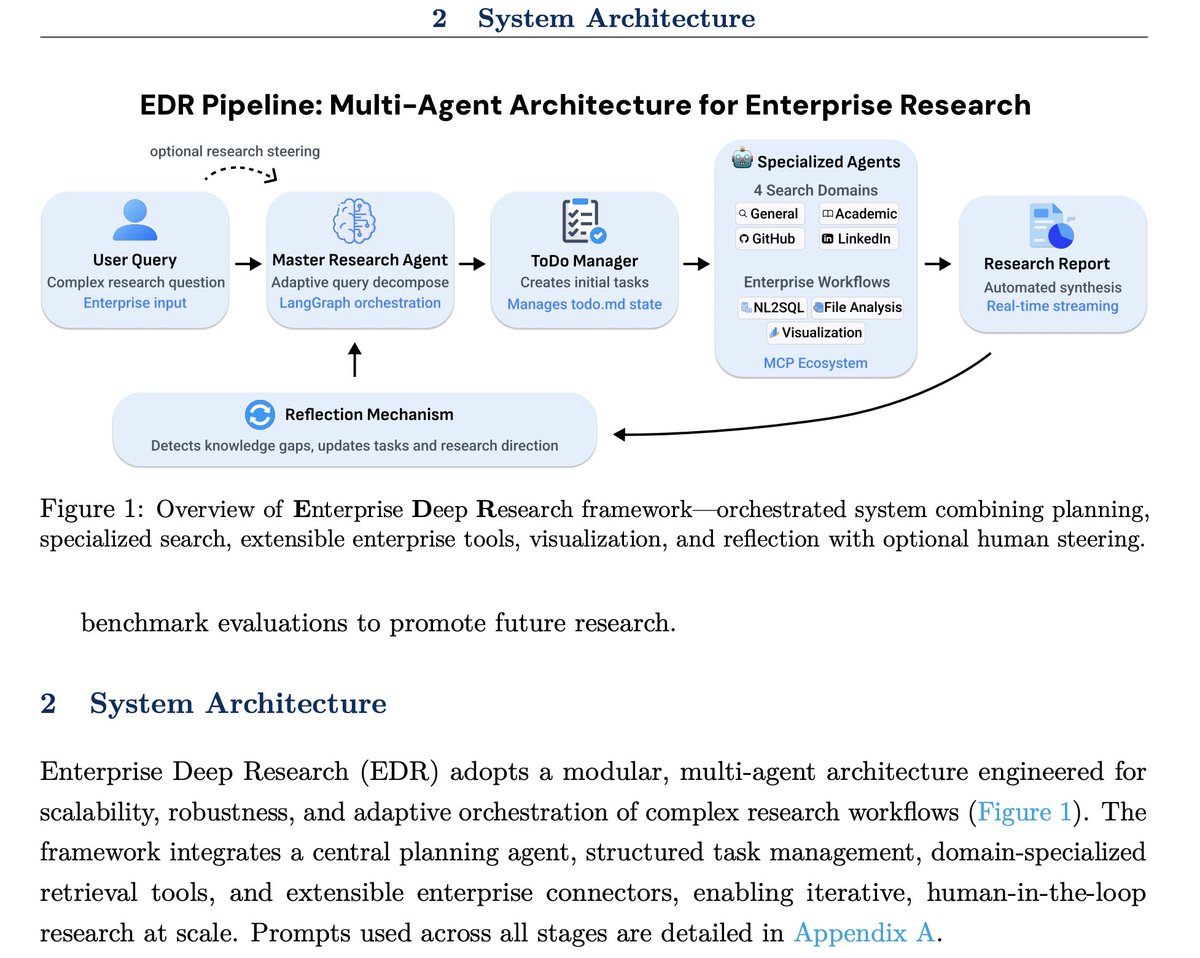
Sabitlenmiş Tweet

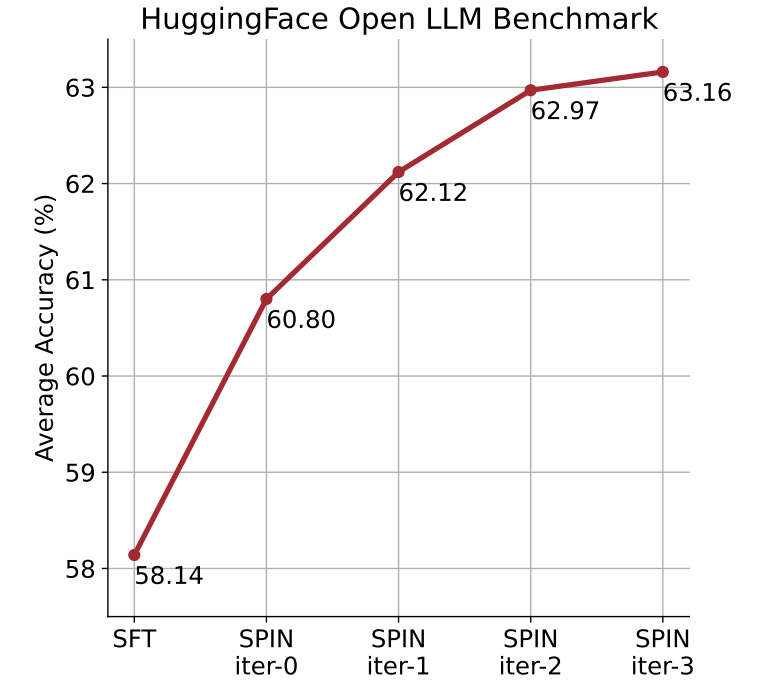
Excited to share our method called 𝐒𝐞𝐥𝐟-𝐏𝐥𝐚𝐲 𝐟𝐈𝐧𝐞-𝐭𝐮𝐍𝐢𝐧𝐠 (SPIN)! 🌟Without acquiring additional human-annotated data, a supervised fine-tuned LLM can get stronger by SPIN. Check out how SPIN unleashes the full power of human-annotated data.
Joint work with @Yihe__Deng, @HuizhuoY, Kaixuan Ji, and @QuanquanGu👏
Link: arxiv.org/pdf/2401.01335…
Key Tech:
👉 LLM generates its own training data from its previous iterations.
👉 LLM refines its policy by discerning these self-generated responses from those obtained from human-annotated data.
Check the detail 🔍 [1/N]
English