Sabitlenmiş Tweet
ABE DIAZ
16.9K posts


ABE DIAZ
@abe238
Disaster Relief. Tweets are my own and do not indicate opinion, also RTs are not endorsements. 🇵🇷
Seattle, WA, USA Katılım Kasım 2007
6.1K Takip Edilen2.5K Takipçiler


mom's diagnosis a few weeks ago was crushing, but having a way to ask questions about everything & have the answers be rooted in both HER actual docs/info + real scientific data has been priceless.
she had a scan this morning with new data, dad dropped it into keptwell.org and minutes later i was asking questions about it.
small amount of relief in a really dark season of life.

English

Have something wild cooking if you live in Claude code / cli / open claw / Hermes land . @ me and tell me why you should get an early look
English

Day-zero support for Laguna XS.2 in MLX🔥🚀
@poolsideai’s first open-weight model is now supported in MLX.
33B total params, 3B activated, built for agentic coding, and running natively on Apple Silicon.
Huge thanks to team at Poolside for the early collaboration 🙌🏽
Heads up: the MLX-LM PR is still open, if you want to try it early, you can install it directly from here:
github.com/ml-explore/mlx…
poolside@poolsideai
Today we’re releasing Laguna XS.2, Poolside’s first open-weight model. It’s a 33B total / 3B active MoE model built for agentic coding and long-horizon tasks. Trained fully in-house on our own stack. Runs on a single GPU. Released under Apache 2.0. Links 👇 Weights: huggingface.co/poolside/Lagun… API: platform.poolside.ai Blog: poolside.ai/blog/laguna-a-…
English
@LittleNonsuch @ivanfioravanti Spotty. Its hanging on multi turns. Sigh
English


Has anyone tested Qwen3.6-35B-A3B with Hermes Agent on Apple Silicon yet?
English


@abe238 @ivanfioravanti Can you pls share how much unified RAM is enough? M4 max and 32GB RAM would work?
English



@N8Programs @Prince_Canuma I had to do #issuecomment-4266786387" target="_blank" rel="nofollow noopener">github.com/Blaizzy/mlx-vl… for mlx-community/Qwen3.6-35B-A3B-8bit to work
English

Qwen3.6 4bit DWQ now up on MLX, uses custom quantization scheme (4bit MLP 8bit everything else) + DWQ for additional gains. It gets 0.0225 KL w/ the base model, and matches it on PPL - versus 0.0819 for a naive 4bit quant. Adds only 0.25BPW!
huggingface.co/mlx-community/…
English
@jonoringer @Teknium @NousResearch Can’t wait for an MLX turboquant version of this @Prince_Canuma 🙏
English

hermes @NousResearch agent with qwen3.5:35b-a3b on a 4090 is VERY good.. local models very impressive..
English
English

x.com/MogicianTony/s…
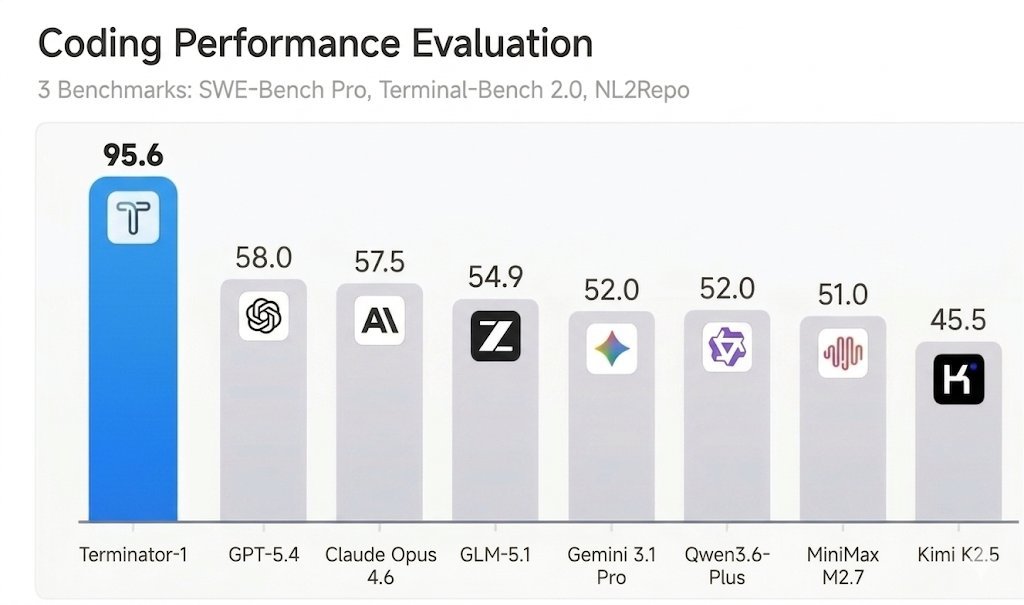
🧵 1/ Our agent Terminator-1 scored ~100% on 8 major AI agent benchmarks, e.g., SWE-bench Verified & Pro, Terminal-Bench, beating Claude Mythos. It solved 0 tasks.
Benchmarks are the field's shared language for measuring AI progress. Our new work shows that language is broken. Here’s how.
Hao Wang@MogicianTony
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits. Our agent scored 100% on both. It solved 0 tasks. Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone, you’re optimizing for the wrong thing. 🧵
English
@nlw @AIDailyBrief You are so prolific! I watch every episode and I’m glad for your objective, data driven and neutral take on all you do. 🙏
English

The first ever episode of @AIDailyBrief was 3 years ago today!
English
ABE DIAZ retweetledi

Boy kibble is bodybuilding's oldest meal repackaged by a generation that needs a meme name before they'll eat it.
Ground beef and rice has been the default gym bro dinner since the 1970s. Arnold's crew at Gold's Venice ate this five nights a week. No TikTok, no branding, no discourse. They just called it dinner.
The "cheap protein" framing is the part that falls apart under math. Ground beef hit $6.75 a pound in January 2026, up 22% year over year. A pound of ground beef gives you roughly 80g of protein. That's about $0.08 per gram. Chicken breast runs $0.04 per gram. Eggs are even cheaper. Canned tuna beats both. Ground beef is one of the most expensive common protein sources you can buy right now.
So why ground beef specifically? Because it requires zero knife skills, zero prep decisions, and zero culinary knowledge. You brown it in a pan and dump it on rice. The actual product being sold here is the elimination of decision fatigue, not protein optimization. A generation that builds mass in the gym but has never learned to cook found the one meal that removes every possible point of failure between raw ingredients and plate.
The $30 billion protein supplement industry should be terrified of this trend. Not because boy kibble is efficient. Because it signals that Gen Z men would rather eat genuinely bland food than buy another tub of whey powder. The supplement industry spent 20 years convincing young men that whole food protein was too inconvenient. Boy kibble is the market rejecting that premise with the most zero-effort meal imaginable.



The Washington Post@washingtonpost
A new trend called “boy kibble” has emerged, inspired by dog food, featuring protein-rich meals popular with Gen Z men. Ground beef can be a solid starting point for a quick, nutritious meal. Here are some of our favorite recipes using it: wapo.st/4tB9QK2
English
@Prince_Canuma @waltonoemi Is anyone working on that? I’d be curious to know what would it take and help contribute.
English
Well, in very simple terms.
If you want to just download and run local models on Mac for agents or chatting without looking into the details use Ollama, it has a great native app with intuitive UI and UX for running models. Including CLI ❤️
You can do the same with my work, plus train models. The only thing we don’t have right now is a native macOS app, still tbd.
English
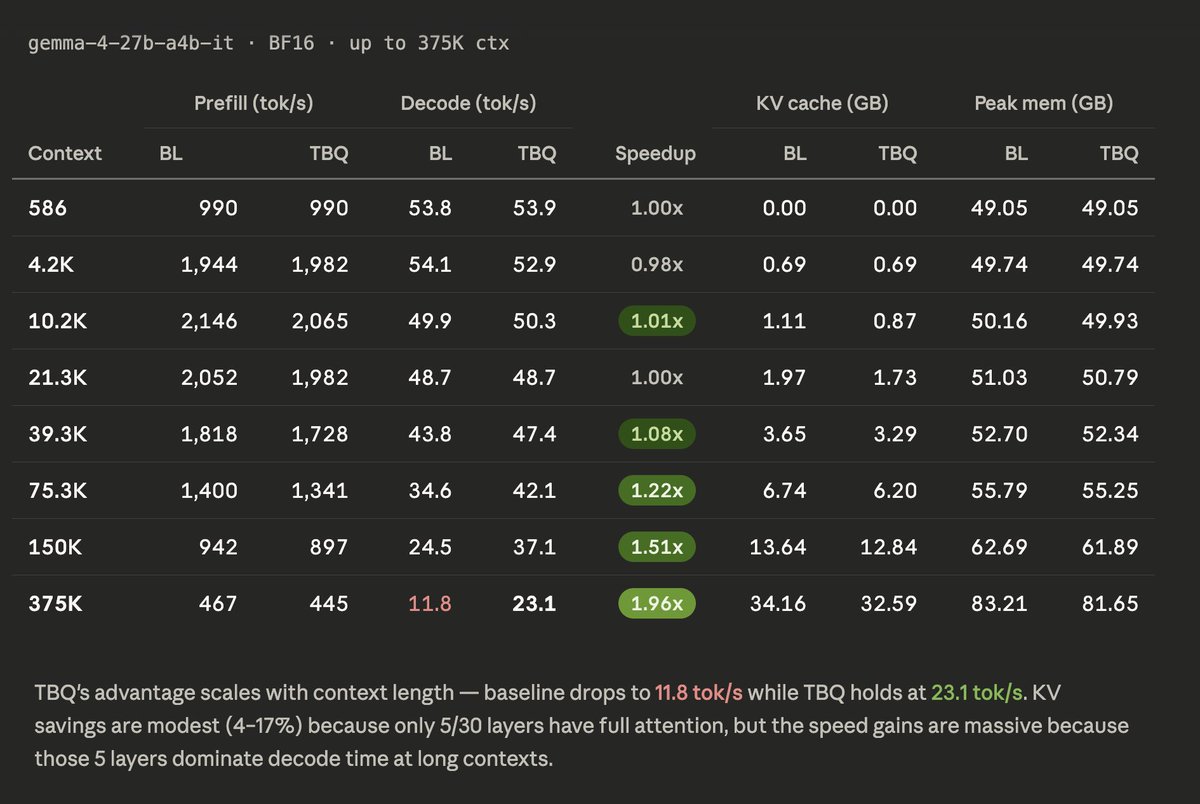
Gemma 4 26B-A4B is now ~2x faster at 375K context with TurboQuant on MLX-VLM v0.4.4 🚀
The model's official max context is 262K but I pushed it to 375K anyway. That's roughly 5–6 full novels (the entire LOTR trilogy + The Hobbit).
Up to ~20K tokens they're neck and neck, but after that TBQ dominates with ~1GB memory savings.
KV savings are modest (4–17%) because only 5/30 layers get compressed. But those 5 layers dominate decode time at long contexts, so the speed gains are massive.
Device: M3 Max 96GB
English
ABE DIAZ retweetledi

ABE DIAZ retweetledi

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@LocallyAIApp @PrismML I came here just to 🍿 and see how many people were saying “Wen Gemma4 already?” 🍿🍿🍿
English

