
@andrewwhite01 @andrewwhite01 Who do you have on your team who's coming up with ideas for your agents to research? I'm curious what their process is like.
English
Aiden Kolodziej
84 posts
@aidenosinetrip1
MIT Biology https://t.co/WSoeyApucV


Today we all lost our jobs..... Three Nature papers showing that scientists in the conventional sense are obsolete At least read the first one.... the AI replaced all things that the scientist does .... nature.com/articles/s4158…

Today we all lost our jobs..... Three Nature papers showing that scientists in the conventional sense are obsolete At least read the first one.... the AI replaced all things that the scientist does .... nature.com/articles/s4158…


$40k-$60k/year for a gene editing job in Boston Academia is cooked bro


1/2 If you think that the Protein Data Bank is a representative DB, it is not. The data is highly biased. The CATH suggests that there are 1,472 protein folds, yet among the ~600k domains present in the PDB, ~39% are represented by the 10 most abundant folds (AKA superfolds).
Every biologist needs to try vibe coding, they're perfectly trained for it. Who else is totally comfortable prodding alien, indecipherable blobs with vague incantations, watching them slosh and churn with only the foggiest mental model of the intricate yet sloppy machinations churning inside the box. Then getting wildly surprising outputs that you then have to patiently corral toward something that’s, if not exactly what was in mind, at least an interesting and useful creation

Can we design mutations that predictably bias proteins towards desired conformational states? Today in @ScienceMagazine, we introduce Conformational Biasing (CB), a simple and scalable computational method that uses contrastive scoring by inverse folding models to identify conformation-biasing mutations. science.org/doi/10.1126/sc…
This experimental result from OpenAI is like when Google maps forces you to get on the highway to save 1 minute but its like 1000x more annoying Its functional significance is next to non-existent because people doing it don't understand that not everything in biotech needs an efficiency improvement. Biotech is definitely a game of probabilities but generally there's a probability threshold where everything over it is functionally the same. This experiment isn't optimizing something that had such low efficiency that everybody was begging for it to be better. Sure a human can do this but I think that's a dumb argument. The fact of the matter is that humans didn't want to do this. Nobody thought it was worthwhile enough to try and optimize it even though it's been done millions of times. On the low end of getting Gibson assembly to work it doesn't matter. Generally you're only looking for a handful of colonies or even just one. On the high end, there are much more important parts to focus on to get the probabilities you need like the freshness of the competent cells that can influence transformation efficiency on the order of 10^6-10^10+ or fragment size or other parts that dominate the functional efficiency For a company with the resources of OpenAI I'm just going to outrate say that this is pretty bizarre and sad and is a stark realization that the capabilities of LLMs are so blown out of proportion Literally no one is asking how to make Gibson assembly more complicated and expensive for a slightly better efficiency



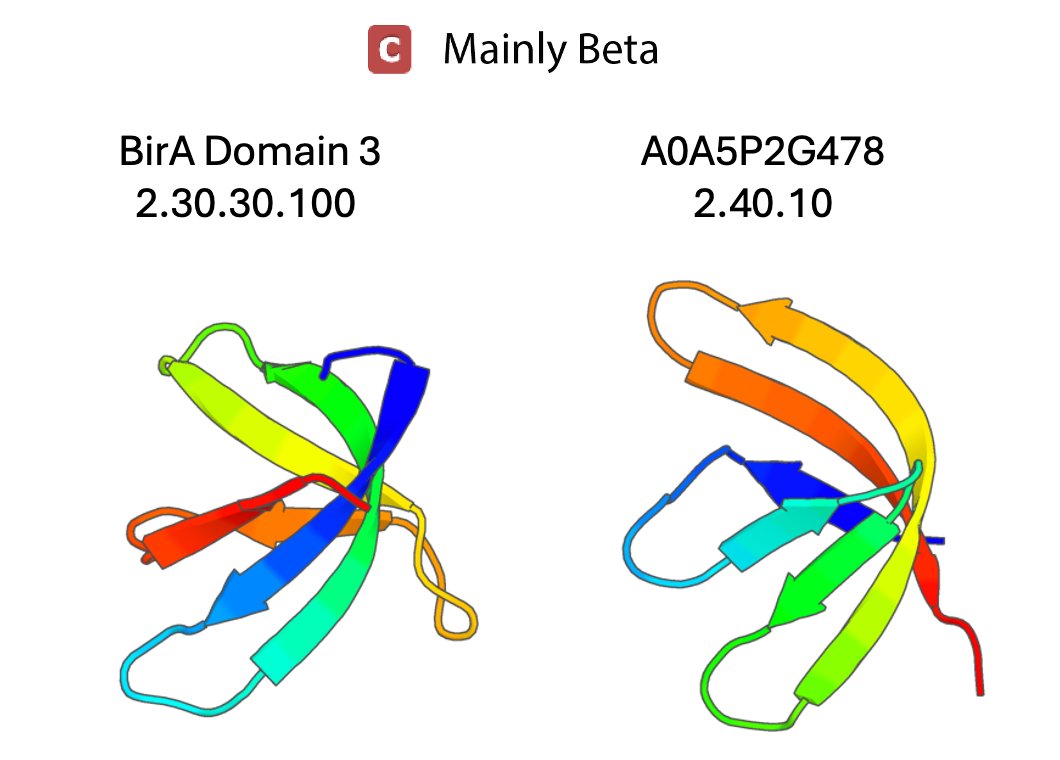
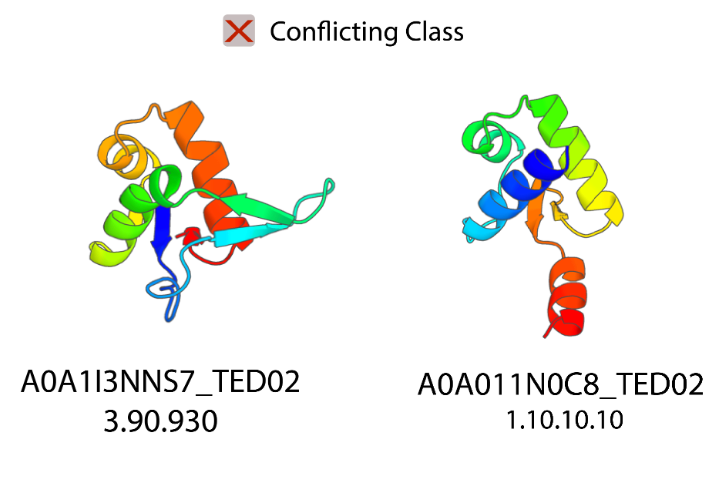
🚨 For those training DL models on proteins, it's possible your "structural" train/test split might have leakage cus tools like foldseek/TMalign (and CATH/SCOP databases) do not always account for structural relationship of circularly permuted proteins:


