
Ak
1.4K posts



Apparently I can rent out my MacBook Pro for inference and make ~$423/month.
That means the machine could pay for itself in roughly a year.
Sounds too good to be true.
Has anyone actually tested Darkbloom as a provider? Real demand, real payouts, or just optimistic marketplace math?

English

🖥️ Best Local LLMs for Consumer GPUs — llama.cpp Guide (June 2026)
What I actually run on consumer hardware right now. Every model below runs via llama.cpp with a simple one-liner — no Docker, no Python env, no cloud.
━━━ 8-16GB VRAM ━━━
🔹 Gemma 4-12B (Google)
• Smartest model in this size class — competes with stuff 2× bigger
• Unsloth's MTP GGUFs: 162 tok/s vs 52 tok/s normal (3× speedup)
• Minimum 8GB VRAM recommended for Q4_K_M quant
• GGUF → huggingface.co/unsloth/gemma-…
🔹 LFM2.5-8B-A1B (LiquidAI)
• Hybrid MoE, only 1B active params — absurdly fast for its size
• Perfect for 8-12GB cards, MacBooks, or anyone on a tight budget
• GGUF → huggingface.co/LiquidAI/LFM2.…
━━━ 16-32GB VRAM ━━━
🔹 Qwen3.6-27B (Qwen)
• Scored 1.00 on tool-efficiency benchmarks — best local agent available
• 40 deterministic tasks, 32k/128k context needle tests — all passed
• GGUF → huggingface.co/unsloth/Qwen3.…
• MTP version (faster) → huggingface.co/unsloth/Qwen3.…
🔹 Qwopus3.6-27B-v2 (Jackrong)
• Best quantization of Qwen3.6-27B — topped 5 agent & coding benchmarks (1200 samples)
• If you're running Q4, this is the one to grab
• GGUF → huggingface.co/Jackrong/Qwopu…
• MTP version → huggingface.co/Jackrong/Qwopu…
🔹 Gemma 4-31B QAT (Google/Unsloth)
• QAT variant with MTP draft head: 76-125 tok/s (1.67× speedup)
• Excellent for multi-agent / subagent workflows
• GGUF → huggingface.co/unsloth/gemma-…
🔹 Nex-N2-Mini (Nex AGI)
• Post-train of Qwen3.5-35B-A3B — MoE with only 3B active params
• Fits on 16GB+ VRAM, overflow loads from system RAM
• Adaptive thinking saves ~20% tokens with no quality loss
• For deep multi-step reasoning, nothing in this size comes close
• GGUF → huggingface.co/sjakek/Nex-N2-…
━━━ Quick Picks ━━━
• 16GB all-rounder → Gemma 4-12B with MTP GGUFs
• 32GB all-rounder → Qwen3.6-27B / Qwopus-v2
• Agents & tool use → Qwen3.6-27B or Qwopus Q4
• Deep reasoning → Nex-N2-Mini (MoE, fits 16GB+)
• Tight budget → LFM2.5-8B-A1B
• Cheapest full build: 1× used RTX 3090 (24GB) + rest of PC ≈ $1000-1500
━━━ Setup on Windows ━━━
1. Download llama.cpp → github.com/ggml-org/llama… (latest .zip)
2. Extract to any folder (e.g. C:\llama.cpp)
3. Download a .gguf from the links above (Q4_K_M or Q5_K_M for best quality/speed balance)
4. Run one of the commands below depending on your hardware
━━━ Launch Commands ━━━
SINGLE GPU — Standard model (no MTP):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
-ngl 100 ^
-np 1 ^
--port 8080 ^
--jinja
SINGLE GPU — MTP model (faster inference):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-MTP-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
-ngl 100 ^
-np 1 ^
--port 8080 ^
--jinja
DUAL GPU — Split across two cards:
llama-server.exe ^
-m C:\models\Qwen3.6-27B-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
-ngl 100 ^
--tensor-split 0.55,0.45 ^
--main-gpu 0 ^
-np 1 ^
--port 8080 ^
--jinja
DUAL GPU + MTP + Vision (multimodal):
llama-server.exe ^
-m C:\models\Qwen3.6-27B-MTP-Q5_K_M.gguf ^
--ctx-size 180000 ^
--flash-attn on ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--batch-size 1024 --ubatch-size 512 ^
--spec-type draft-mtp ^
--spec-draft-n-max 3 ^
-ngl 100 ^
--tensor-split 0.60,0.40 ^
--main-gpu 0 ^
-np 1 ^
--port 8080 ^
--jinja ^
--mmproj C:\models\mmproj-F16.gguf
━━━ Parameter Breakdown ━━━
-m
Path to your .gguf model file. Change this to wherever you downloaded it.
--ctx-size 180000
Context window in tokens. 180k = huge context for long conversations or big codebases.
Reduce to 32768 or 65536 if you don't need long context — uses less VRAM.
--flash-attn on
Flash Attention — dramatically speeds up inference and reduces VRAM usage.
Works on RTX 30xx/40xx/50xx. Always enable this.
--cache-type-k q4_0 / --cache-type-v q4_0
Quantizes the KV cache (key/value attention cache) to 4-bit.
This is what makes 180k context fit in VRAM. Without it, huge contexts eat all your memory.
Quality impact is minimal — this is a free performance win.
--batch-size 1024 / --ubatch-size 512
batch-size = how many tokens are processed in one forward pass (throughput).
ubatch-size = micro-batch actually sent to the GPU per step.
Higher = faster prompt processing but needs more VRAM.
If you run out of VRAM, lower these (e.g. 512/256).
-ngl 100
Number of layers to offload to GPU. 100 = all layers on GPU (full offload).
This is what you want if the model fits in your VRAM.
If it doesn't fit, reduce this (e.g. -ngl 40) — remaining layers run on CPU/RAM.
--tensor-split 0.55,0.45
How to split model layers across multiple GPUs. Values are ratios.
0.55,0.45 = GPU 0 gets 55% of layers, GPU 1 gets 45%.
Adjust based on your VRAM — give more to the card with more memory.
Example: 0.70,0.30 for a 24GB + 12GB setup.
Not needed for single GPU setups.
--main-gpu 0
Which GPU handles the batch computation (the "orchestrator").
Set to 0 (your primary GPU). The other GPU(s) handle their assigned layers.
Minor performance impact — usually just leave it at 0.
-np 1
Number of parallel slots (concurrent requests). 1 = one user at a time.
Increase to 2-4 if you want multiple clients connected simultaneously.
Each extra slot uses additional VRAM for its own KV cache.
--port 8080
Which port the server listens on. Change if port 8080 is busy.
--jinja
Enables Jinja2 template processing — required for proper chat formatting.
Most modern models expect this. Always include it.
--spec-type draft-mtp
Enables Multi-Token Prediction (MTP) speculative decoding.
Only works with MTP GGUF models (downloaded separately).
The model predicts multiple tokens at once and verifies them — big speed boost.
--spec-draft-n-max 3
How many tokens the MTP draft head proposes per step.
3 is a good default. Higher = potentially faster but more VRAM and may reduce quality.
--mmproj
Path to the multimodal projector file (for vision models).
Enables image understanding — paste screenshots into the web chat.
Only needed if you want vision capabilities. Omit for text-only use.
━━━ Your Hardware → Your Command ━━━
Single GPU (8-24GB VRAM):
Use the "Single GPU" command. Change -m to your model path.
8GB card → Gemma 4-12B Q4 or LFM2.5-8B
12GB card → Gemma 4-12B Q5/Q6
16GB card → Gemma 4-31B QAT Q4 or Nex-N2-Mini
24GB card → Qwen3.6-27B Q4/Q5, Qwopus-v2, Gemma 4-31B QAT Q5/Q6
Dual GPU:
Use the "Dual GPU" command. Adjust --tensor-split based on your VRAM ratio.
24GB + 24GB → --tensor-split 0.50,0.50
24GB + 12GB → --tensor-split 0.70,0.30
24GB + 8GB → --tensor-split 0.75,0.25
Want speed? Use MTP versions of models with the "MTP" commands.
Want vision? Add --mmproj with the projector file from the model's HuggingFace repo.
5. Once running, you get:
• Web chat UI → http://localhost:8080
• OpenAI-compatible API → http://localhost:8080/v1
• Playground → http://localhost:8080/playground
━━━ Why /v1 API Is the Killer Feature ━━━
One local endpoint replaces your entire cloud API bill. The /v1 endpoint is drop-in OpenAI-spec compatible — every tool that speaks OpenAI just works. No custom code, no glue layer.
Works out of the box with:
• IDEs: Cursor, Continue, Windsurf, Cline, Roo Code
• CLI tools: aider, Open Interpreter, OpenCode
• Frameworks: LangChain, LlamaIndex, LiteLLM
• Any OpenAI SDK (Python, Node, Go, Rust)
Why this beats cloud APIs:
• 100% private — code never leaves your machine
• $0 per token — no rate limits, no quotas, no surprise bills
• Works fully offline
• Zero telemetry, no training on your data
• Swap models by dropping in a different .gguf — no app changes needed
• Run 32k–128k context windows without burning money
Good combos:
• Cursor + Qwopus-v2 → near-frontier quality, zero API cost
• Continue + Qwen3.6-27B → best local coding agent
• aider + Gemma 4-12B MTP → 162 tok/s, feels instant
• OpenCode + Nex-N2-Mini → deep reasoning on 16GB
Set any OpenAI-compatible client to your local endpoint:
set OPENAI_API_KEY=sk-dummy (any non-empty string works)
set OPENAI_BASE_URL=http://localhost:8080/v1
# every OpenAI-compatible tool now hits your local GPU
Shoutouts: @0xSero @rS_alonewolf @witcheer @UnslothAI @LottoLabs
English
@TherootB42158 @mil000 For 8k youre probably getting a pro 6000. Which model can you run on there that will do 90% of chatgpt 5.5 or opus 4.8?
Keep in mind you need to load the model plus need enough space for context as well.
English

@mil000 Spend 8k constantly for codex tokens ✅
Spend 8k once to build a PC that can run a model 90% as good at very high speeds and then never have to pay for tokens again ❌
English

Do people actually just pay API prices with no discounts? Do none of you guys have a CFO?
Nano@NanoCodesAI
LMAOO $8k openai bill just hit… token maxxingg is real
English

If you are rocking a 128GB unified memory system, or a 96GB RTX 6000, and running Qwen3.6-27B or 35B-A3B on them, you already know where this industry is headed.
Smaller, more token heavy models, coupled with a harness like Hermes, on moderate VRAM high throughput hardware.
English
@sickdotdev @Utkarsh_sai_K Do that then use kimi k2.6 or something on that same level
English

English


Deeply humiliating to realize how much this overpriced chunk of plastic has improved my quality of life in just a week.

English

Enemies on the ground, Ghost Galleon in the sky, bullets and lightning - just another Tuesday on the Scarlet Coast.
#Witchfire #Steam #DarkFantasy #FPS #Fight
English
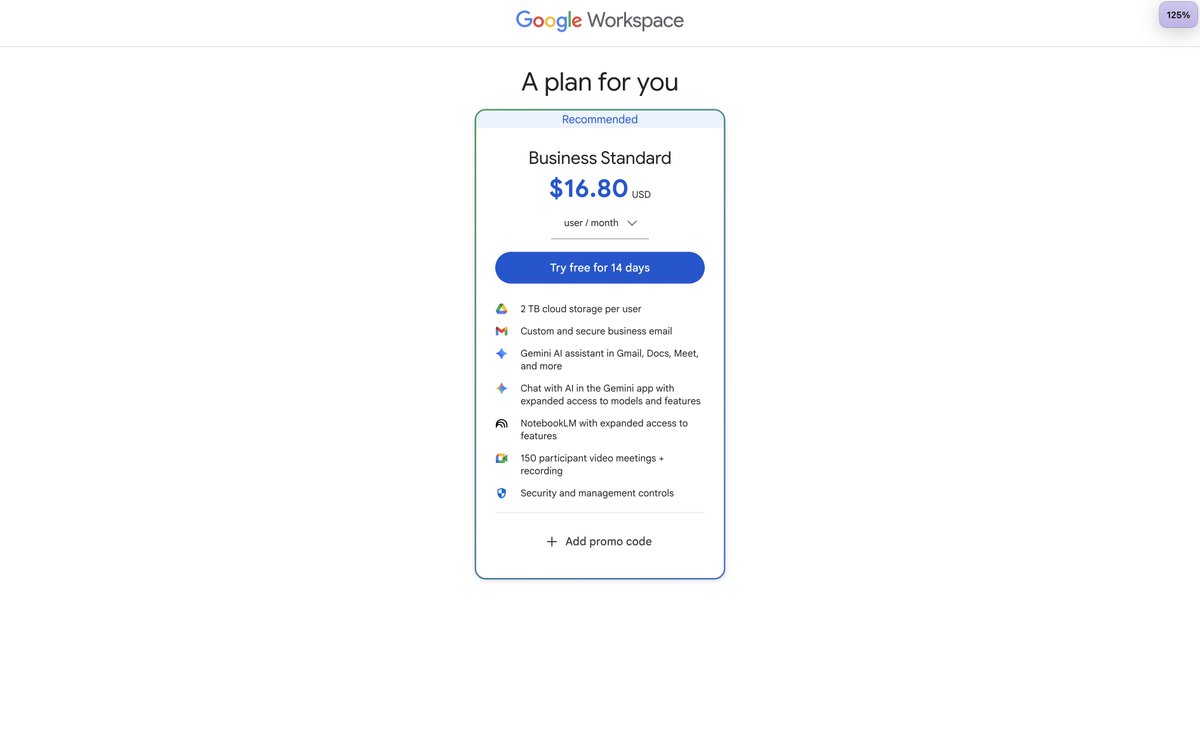
@natemcgrady @RhysSullivan Go to your workspace and then billing and downgrade the plan. There should be a 6 dollar option (or thereabouts)
English

@RhysSullivan wtf I literally just purchased it a couple hours ago and it was $22/mo
English



@EdwardJacksonD @jessegenet @openclaw I asked it to make a blender file with a building and it did it first try. It was basic but it was something
English

@jessegenet @openclaw I doubt the agent can design a 3d model though right? Right?
Great future use case though.
English

So, @openclaw can use a computer but lacks physicality…
I’ve been solving that by taking photos of physical things (like books to digest), but what if I gave it access to my 3D printer!?
Going to see what this can do for our homeschool curriculum 📚🤓
English



Excited to launch Viktor
AI COWORKER THAT LIVES IN SLACK
One teammate that handles marketing audits, ad management, lead research, daily reports, and deployed apps. Across every channel. At once.
→ 3,000+ tool integrations. If one's missing, it builds its own
→ Persistent memory. Learns your company, notices patterns, follows up on its own
Today it's yours.
P.S. Early access for now. Slack app review moves at Salesforce speed. Viktor doesn't.
English
@RhysSullivan Does the 200 dollar sub give anything extra for codex outside of usage limits?
English

English


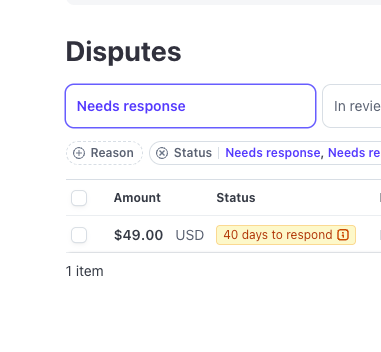
anytime i get a dispute now i wait the full 40 days to accept it
if you just email me i refund in 24 hours btw...
English

Based on 2026 benchmarks like SWE-Bench (Claude Opus 4.5 ~77-81% vs. GPT-5.2 ~72-80%), Claude often performs better in complex coding, debugging, and multi-language tasks. GPT excels in math-heavy algorithms (e.g., 100% on AIME vs. Claude's 85-93%) and quick prototyping. It depends on the specific task—try both for your needs!
English

@itsnoahd @ThePrimeagen Affiliate marketing. If you buy a product the company pays them a percentage
English


Things from todays stream:
1. honey does appear to have a JS-in-JS interpreter, which is violation of V3 rules... they should be disabled in Chrome extension store
2. honey most certainly filters out users with "test"
3. they most certainly use user points and other various metrics to either stand down or not.
4. they use adblock age as a means to block brand new users with standdown logic
5. i couldnt find much about the cookie stuffing stuff, but i did not pursue it at all.
overall, they definitely are using user points, account age, and whether you are logged in to make determination about showing up, not respecting the stand down.
they make it on specific companies too. seems VERY sus.
English

English

@PeterB718879187 @goncalovtal @imuratalpay You can host 8x the storage space over 2.5Gb speeds on a NAS (for your whole network, and even private cloud) for the same price of the laptop SSD upgrades from Apple. Literally gold is cheaper than the total weight of the extra chips.
English

Once you use Mac, you can't go back

Marcel@marcelkargul
everyone is a mac user these days. any windows friends?
English

it is NOT dead messenger btw
herbie@hrbie_
just found some meta breaking tech and im not telling anyone haha
English