
Alex Koo
38 posts

Talked to my wife about agents. Her initial response was “so these will make not do things of a parent”.
The more we talked and I described how you use them it made it better.
Would love to have you discuss it with her or someone like her.
The role of the parent feels challenged when you take things off the plate. The key imo is to take the essential but do not like.
I made the analogy about a dish washer and washer/dryer. Those used to be the “job of a parent”.
English

Yes. This is the way.
This halcyon era of productive but present parenting is here ☀️
kache@yacineMTB
gpt 5.5 has changed my life. my kid has been sick the past couple of days and ive been hanging out with him, but set up a tmux fork with TTS and automatic sshing to all my boxes. and man. im getting more work done than ever
English
@karpathy Love this idea. I agree about using HTML (ie. simply interactive apps) as an information super highway to the brain to learn. I think book juicing is the way to go: x.com/akoo1010/statu…
Alex Koo@akoo1010
One of the best use cases for AI (that nobody is talking about?): what I call "book juicing." Take your favorite non-fiction book that you have in PDF form, ask your favorite coder LLM to create an app to make concepts and illustrations interactive from the book.
English

This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Thariq@trq212
English
@awnihannun @SwiftOnSecurity Makes you wonder how Amanda at Anthropic talks in real life 😄
English

Adopting Claude speak in my regular life, episode 1:
Partner: Did you do the dishes tonight?
Me: Yes they're done.
Partner: Why are they still dirty?
Me: You're right to push back. I didn't actually do them.
English
@Scobleizer How is imagining every possible bad thing that could go wrong, like M Phelps did, different from ruminating?
English

One of the most interesting neuroscience reads I have ever consumed.
How you should train your brain.
Jaynit@jaynitx
English

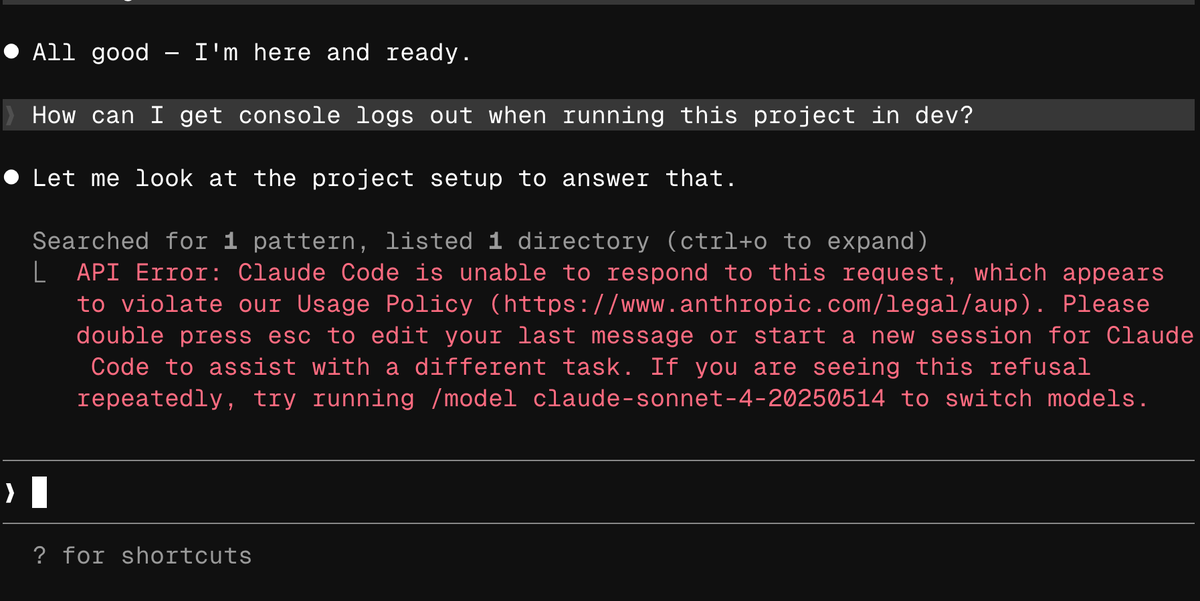
Claude Code now throws an error if you use it to try and analyze the Claude Code source
English
Surprised with how good the comments on github gists are. A lot more helpful, insightful, constructive, a lot less AI... Is it the user community? The markdown format? The (lack of) incentives?
Suddenly feeling like I should gist more.
@github consider competing with X (?)
English
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
English

@AlexFinn @MasonFoard What if I’m a regular person with a 9-to-5 job and I don’t need to build apps, what can I use this for?
English

Do you even understand what this means?
An open source model just released that is:
• Outperforms models 20x its size
• Can run on a base model Mac Mini
• Is AMERICAN 🇺🇸
If you have a base model Mac Mini you can have unlimited super intelligence on your desk. For free.
Sonnet 4.5 was released 5 months ago
In 5 months that level of intelligence went from frontier to free on your desk
And not only that, can run on any basically any computer out there
If you have even a remotely modern computer, do the following immediately:
1. Download LM Studio
2. Go to your OpenClaw and ask which of these new Gemma 4 models is best for your hardware
3. Have it walk you through downloading and loading it
4. Build apps with it knowing you are using your own personal, private super intelligence on your desk
The people denying this is the future are so beyond lost.
Google DeepMind@GoogleDeepMind
Meet Gemma 4: our new family of open models you can run on your own hardware. Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵
English
Alex Koo retweetledi

🔥 New Episode Alert!: 0.37 - From Startup CTO to Acquired by Google -- Anant Jhingran, CTO @Apigee #b2b
startupcto.io/?p=528281

English
Time To Go Big With #APIs! Adapt or Die #DigitalKnowHow World Tour- first stop SF bit.ly/adaptSF #apigeek TW-ADAPT for 10% off
English
Growth and vibrancy of #APICommunity is amazing! 4500+ API practitioners and counting. bit.ly/apicommunity #transparency #apigeek
English
Another insightful post from @jhingran. Gotta be careful of cargo cult engineering--Apigee can help. apigee.com/about/blog/cto… via @apigee.
English
Without an API, connected things don’t connect bit.ly/1qeBMDz via @rww
English
Alex Koo retweetledi

Test public APIs with the Run in Postman button. Check it out live on 10 well known API publishers. #OneClickTesting buff.ly/1QIO54S
English