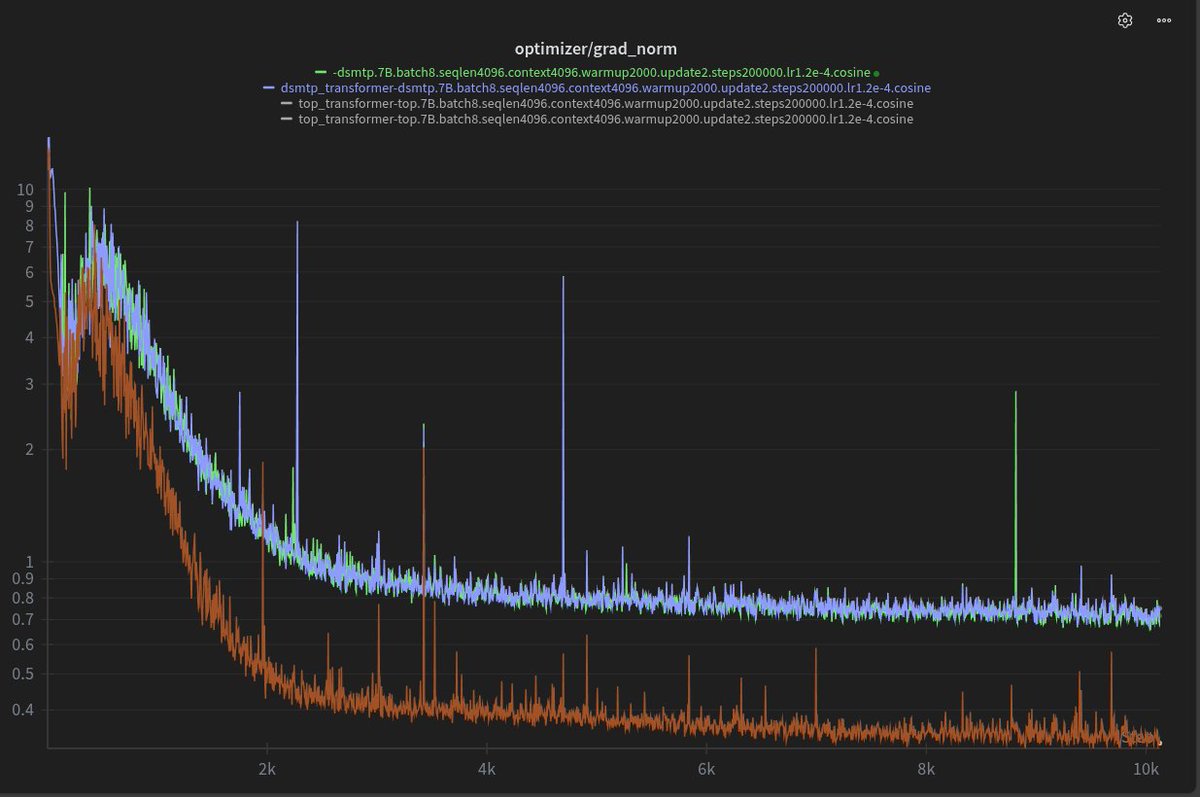
@percyliang Can you explain what you meant by "scaling laws are bending"? The plot in the figure is semilogx. Moreover, AN^{-a} + B is bound to be "bent" even in log-log..?
English
Darshil Doshi
51 posts
@darshilhdoshi1
Johns Hopkins | UMD | Brown | IITGN —— ML | Physics

How far do Marin's scaling laws extrapolate? At least 100x, apparently! Despite spooky spikes, our 1e23 Delphi finished on forecast. The compute-optimal ladder costs ~1e21 FLOPs to train. Good scaling science lets you “run” this (not tiny) experiment at 1/100th the cost.




What governs the geometry of time and space embeddings in LLMs? We show it follows from translation symmetry in language statistics. With Dhruva Karkada, @DanKorchinski, Andres Nava, @yasamanbb arxiv.org/abs/2602.15029
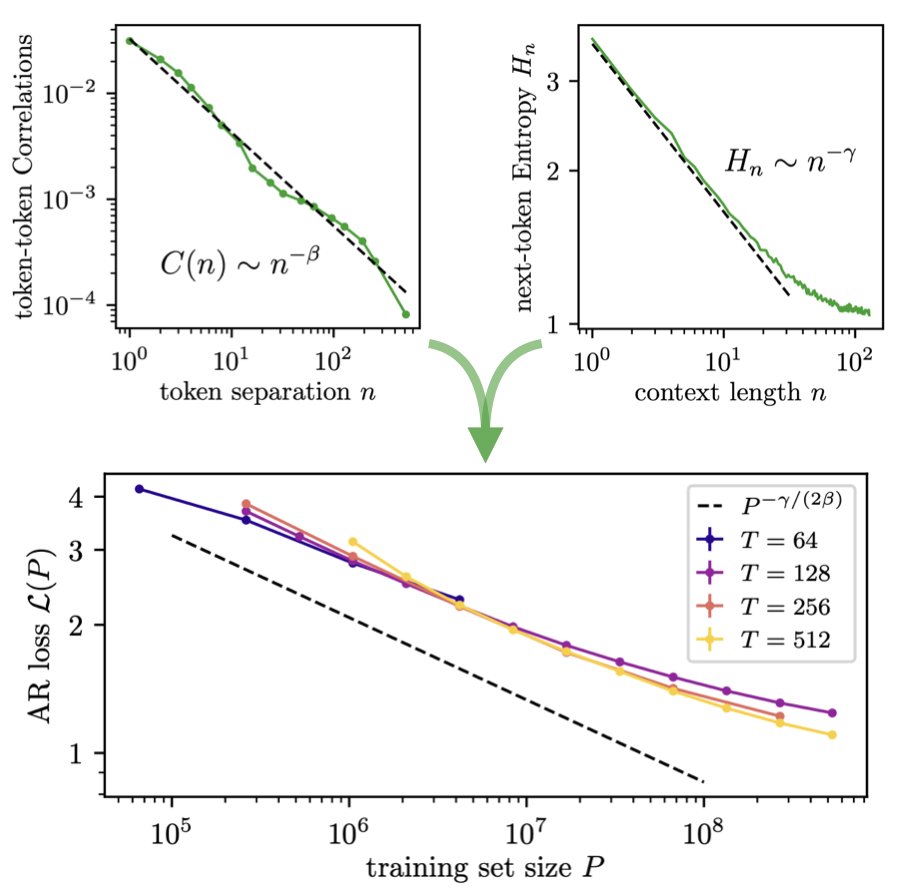
Our new paper "Deriving neural scaling laws from the statistics of natural language" arxiv.org/abs/2602.07488 lead by @Fraccagnetta & @AllanRaventos w/ Matthieu Wyart makes a breakthrough! We can predict data-limited neural scaling law exponents from first principles using the structure of natural language itself for the very first time! If you give us two properties of your natural language dataset: 1) How conditional entropy of the next token decays with conditioning length. 2) How pairwise token correlations decay with time separation. Then we can give you the exponent of the neural scaling law (loss versus data amount) through a simple formula! The key idea is that as you increase the amount of training data, models can look further back in the past to predict, and as long as they do this well, the conditional entropy of the next token, conditioned on all tokens up to this data-dependent prediction time horizon, completely governs the loss! This gets us our simple formula for the neural scaling law!

🚨 2026 @Princeton ML Theory Summer School 🔥 Learn from amazing researchers and meet your peers. Mini-courses by: - Subhabrata Sen @subhabratasen90 - Lenaic Chizat @LenaicChizat - Sinho Chewi - Elliot Paquette @poseypaquet - Elad Hazan @HazanPrinceton - Surya Ganguli @SuryaGanguli (to be confirmed) August 3 - 14, 2026 Apply by March 31, 2026. Link 👇 Sponsored by @NSF, @PrincetonAInews, @EPrinceton, @JaneStreetGroup, @DARPA, @PrincetonPLI, Princeton NAM, Princeton AI2, Princeton PACM



We've identified a novel class of biomarkers for Alzheimer's detection - using interpretability - with @PrimaMente. How we did it, and how interpretability can power scientific discovery in the age of digital biology: (1/6)




The noncommutativity of matrix multiplication is beautiful. Without it all atoms would be unstable.


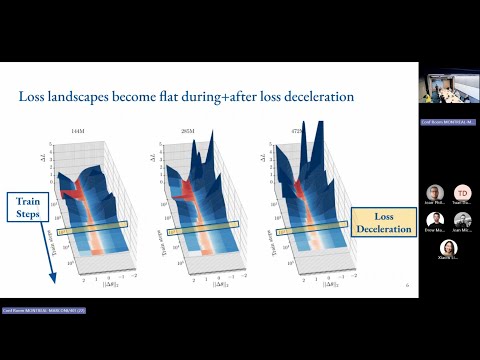

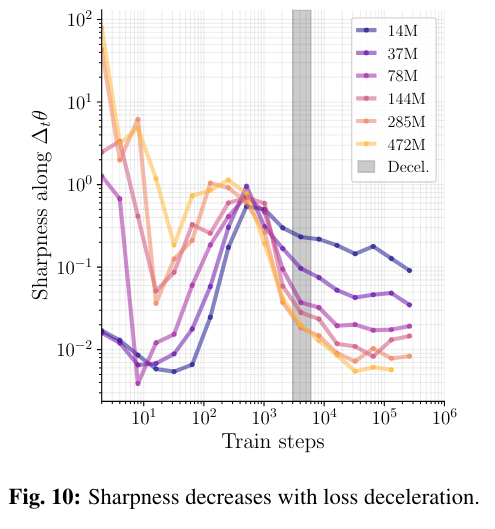


The Physics of Data and Tasks: Theories of Locality and Compositionality in Deep Learning ift.tt/9B0HFnC