
Andreas Rücklé
68 posts

Andreas Rücklé
@arueckle
Sr. Applied Scientist @Amazon in Berlin • Previously @UKPLab @TUDarmstadt • Opinions are my own
Deutschland Katılım Ağustos 2010
617 Takip Edilen343 Takipçiler

>This year, we received 12,148 submissions and accepted 19% of the submissions as Main papers and 18% as Findings.
We have two orals accepted, which makes this an extra special effort by my PhD students @livuninews @LivUni
Prof. Danushka Bollegala@Bollegala
Three papers accepted to ACL main with my current/former students! A proud supervisor moment to see all my current PhD students getting accepted to ACL main at the same time. 🎉🎉🎉 1️⃣ Map of Encoders: There are way too many sentence encoders (over 17K sentence-transformer backends alone!) out there and their landscape is not clear. Which encoders are similar to what others and in what ways? We show that Quantum Relative Entropy is a great metric to compare encoders and create a map of encoders. (arxiv.org/abs/2602.08740) w/ @GaifanZhang 2️⃣ Synthetic Data for Diversified Commonsense Generation: 8B people on Earth are talking to a handful of LLMs these days. LLMs should not be returning templated, fixed, boring responses. How can we make them return more diversified responses? We create the first-ever synthetic dataset for post-training LLMs for diversified response generation. Tianhui is in job market and wrapping up his thesis now with many xACL papers! Grab him while you can. (arxiv.org/abs/2603.18361) w/ Bei Peng and @ThuiZhanglsy 3️⃣ Multilingual Social Bias Benchmark: Thinking process, not just the final answer matters when evaluating social biases in LLMs. This benchmark reveals some of the hidden social biases in LLMs that were not easily surfaced by prior evaluation frameworks. If you care about social biases in LLMs please take a look. w/ @MasahiroKaneko_ and @eltimster #NLProc #ACL2026
English
Andreas Rücklé retweetledi

📢📢📢 The Eval4NLP workshop will take place this year at AACL 2023. Special focus: Evaluation of/with LLMs. Including a shared task on Prompting LLMs as Explainable Metrics. 📢📢📢
Direct submission deadline: 25.08.
Webpage: eval4nlp.github.io/2023/index.html
CFP: eval4nlp.github.io/2023/cfp.html
English
Andreas Rücklé retweetledi

Happy to share the results of the Efficient NLP survey (07/2021) looking into 🌱 environmental impact , 💻 access to compute , and 🕵️ its impact on peer reviewing! Across 312 participants, we find: 👉 a high disparity wrt. compute power 👉 a high support to make things better! 🧵
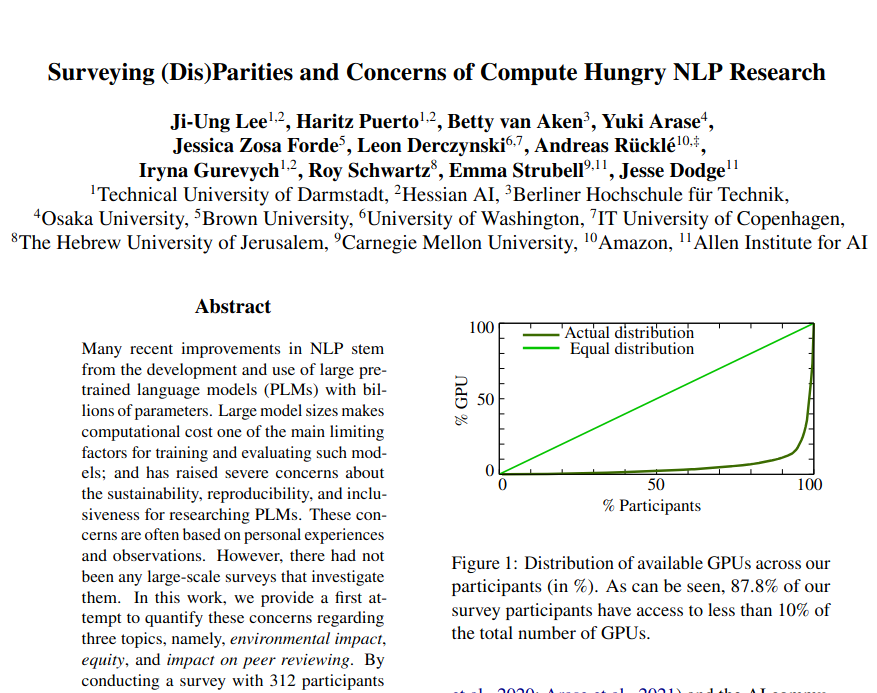
English
Andreas Rücklé retweetledi

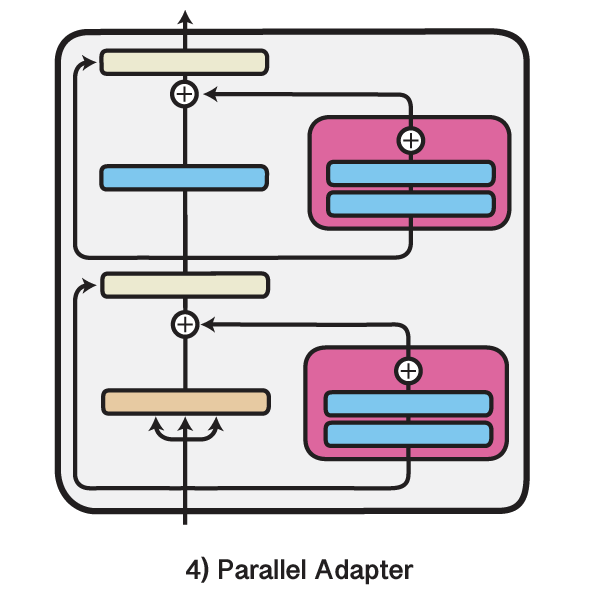
We are excited to release Version 3 of the AdapterHub.ml framework!
We now support more architectures
- Prefix Tuning
- Compacter
- Parallel Adapter
and make it easy to UNION i.e. Mix-and-Match adapters
Our blog covers results and changes: adapterhub.ml/blog/2022/03/a…
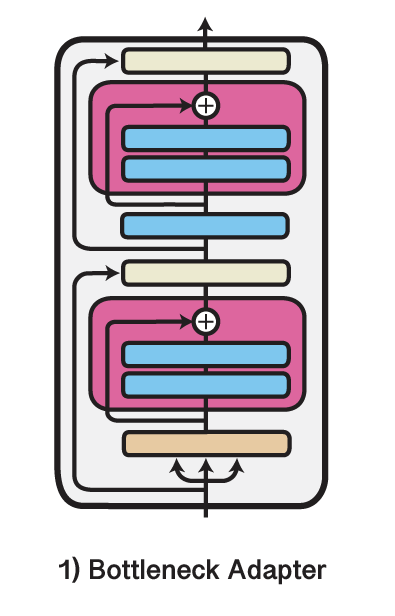
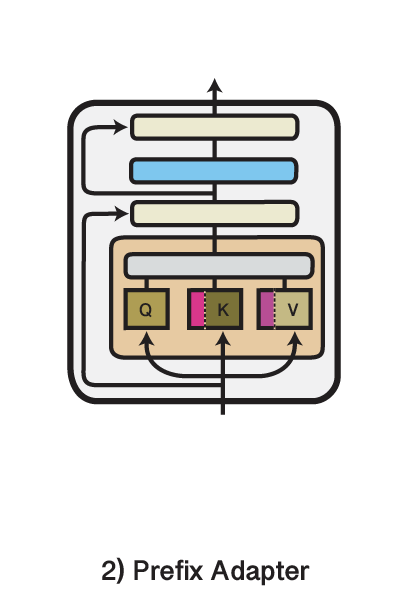
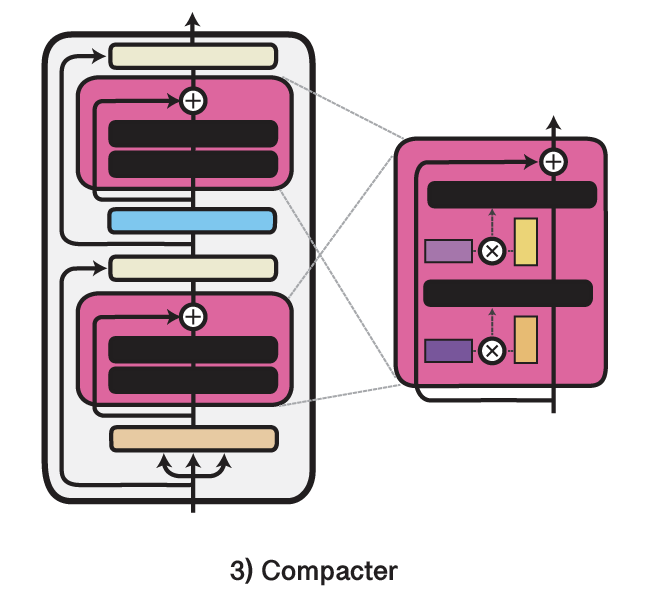
English

I am thrilled and flattered to share that, starting from the next Monday, I will join Amazon Science in Berlin (@AmazonScience) as an Applied Scientist.
I am so looking forward to joining the team and face novel and exciting challenges on #Search #RecSys #Adversarial #IR #NLP!
Berlin, Germany 🇩🇪 English
Andreas Rücklé retweetledi

Happy to announce, we just released v2.2.0 of adapters-transformers🥳
What's new:
🆕Adding adapter support for T5
🏋️AdapterTrainer for fine-tuning adapters
🔮Prediction Heads for language modeling
All changes: github.com/Adapter-Hub/ad…
English
Andreas Rücklé retweetledi

I’m happy to announce🍻BEIR was accepted at #NeurIPS2021 Dataset Track!!😍
We received good feedback for our diverse zero-shot #IR benchmark suite with 18 datasets and 9+ domains. We will continue to improve #BEIR, but for now, let’s celebrate!😎🍻
Link: openreview.net/forum?id=wCu6T…


English
Andreas Rücklé retweetledi

@huggingface Also, happy to add that our paper “What to Pre-Train on? Efficient Intermediate Task Selection” (w. @PfeiffJo & @arueckle), for which all adapters were trained, has been accepted to #EMNLP2021. Code & updated version following.
arxiv.org/abs/2104.08247
twitter.com/clifapt/status…
Clifton Poth@clifapt
In our new paper “What to Pre-Train on? Efficient Intermediate Task Selection” we investigate efficiently selecting the best intermediate training tasks for a target task in an adapter-based transfer setup. w. @PfeiffJo @arueckle tinyurl.com/WhatToPreTrain…
English
Andreas Rücklé retweetledi

Tomorrow at the ACL Business Meeting we will have a panel discussion (14:30–15:30 UTC+0, all registered for ACL can attend) to get feedback on policy recommendations relating to the trends of large computational budgets and efficiency in NLP.
This is an exciting panel including:
English
Andreas Rücklé retweetledi

“How Good is Your Tokenizer?
On the Monolingual Performance of Multilingual Language Models”
by Philip Rust, @IGurevych, @PfeiffJo, @seb_ruder, @licwu
🕐: Session 9A, 03.08, 11:00 — 12:00 GMT
📃: aclanthology.org/2021.acl-long.…
🎥: underline.io/events/167/ses…

English
Andreas Rücklé retweetledi
We have just released v2.1.0 of adapter-transformers!
What's new:
🤗Integration into @huggingface's Model Hub (⬇️)
🗂 Split input batches between adapters
🔄Automatic prediction head conversion
All changes: github.com/Adapter-Hub/ad…

English
Andreas Rücklé retweetledi

Extremely honored by the best long paper award at EACL 2021 @eaclmeeting! Paper (with my dear friend and co-author @licwu):
aclweb.org/anthology/2021…
English
Check out BEIR, our new IR benchmark with 17 diverse datasets from different domains + tasks! The paper thoroughly compares nine(!) different IR models and provides interesting insights such as cosine vs dot product for dense IR. Work by @Nthakur20 @Nils_Reimers @abhesrivas
Nandan Thakur@beirmug
🚨New paper alert 🚨 🍻 BEIR: a heterogeneous benchmark for IR. 17 datasets, 9 tasks with diverse domains. 9 SOTA retrieval models evaluated in a zero-shot setup. w/ @Nils_Reimers @arueckle @abhesrivas, IG at @UKPLab pdf: arxiv.org/abs/2104.08663 More details, code 👇 #NLProc
English
SciGen is a *very* challenging dataset for table-to-text generation, which requires models to reason over scientific tables. Thanks to everyone who participated in the annotation process, your help was highly appreciated!
English
Check out our new paper where we broadly study how to select intermediate pre-training tasks for adapter-based transfer learning. The most complex methods are not always the best! Work with @clifapt @PfeiffJo
Clifton Poth@clifapt
In our new paper “What to Pre-Train on? Efficient Intermediate Task Selection” we investigate efficiently selecting the best intermediate training tasks for a target task in an adapter-based transfer setup. w. @PfeiffJo @arueckle tinyurl.com/WhatToPreTrain…
English
New paper w/ @GregorGeigle @Nils_Reimers where we study approaches to efficiently identify suitable QA agents specialized in different kinds of questions! In a simulated environment, TWEAC is not only effective but also scales well to hundreds of QA agents.
Gregor Geigle@GregorGeigle
Check out our new publication: “TWEAC: Transformer with Extendable QA Agent Classifiers” We propose a meta-QA to find the most fitting QA systems within a pool for a given question. w/ @Nils_Reimers @arueckle IGurevych arxiv.org/abs/2104.07081 Code & data released as well
English
Andreas Rücklé retweetledi

Recent Advances in Language Model Fine-tuning
New blog post that takes a closer look at fine-tuning, the most common way large pre-trained language models are used in practice.
ruder.io/recent-advance…
English
Andreas Rücklé retweetledi
Very cool new toolkit built on top of adapter-transformers
Viet Lai@laidacviet
We are happy to introduce our new Python toolkit - Trankit, a light-weight transformer-based toolkit for multilingual natural language processing that can process raw text and support fundamental NLP tasks for 56 languages. github.com/nlp-uoregon/tr….
English
Andreas Rücklé retweetledi

Check out our new paper:
"UNKs Everywhere: Adapting Multilingual Language Models to New Scripts"
We propose a series of methods that enable adaptation of pretrained multilingual models to low-resource languages
and unseen scripts.
\w @licwu IG @seb_ruder
tinyurl.com/UNKsev

English
Andreas Rücklé retweetledi

These tutorial slides on "High Perf NLP" are really impressive. Every slide is current to the minute. Amazing set of diagrams.
gabrielilharco.com/publications/E…
(@gabriel_ilharco @Tim_Dettmers @IuliaTurc @kentonctlee Felipe Ferreira Cesar Ilharco)

English