
Took Claude up for a spin on the weekend and started a quick open-source self-hosted re-implementation Thinking Machines' Tinker API: github.com/calpt/open-tin…
English
Clifton Poth
93 posts
@clifapt
ML for Search @Cohere | Open source @AdapterHub | prev. @TUDarmstadt @UKPLab @clifapt.bsky.social
It’s available in two versions to meet your company’s specific search needs: Fast and Pro.


It’s available in two versions to meet your company’s specific search needs: Fast and Pro.






Introducing our latest AI search model: Rerank 3.5! Rerank 3.5 delivers state-of-the-art performance with improved reasoning and multilingual capabilities to precisely search complex enterprise data like long documents, emails, tables, and code. cohere.com/blog/rerank-3p…




🎉Adapters 1.0 is here!🚀 Our open-source library for modular and parameter-efficient fine-tuning got a major upgrade! v1.0 is packed with new features (ReFT, Adapter Merging, QLoRA, ...), new models & improvements! Blog: adapterhub.ml/blog/2024/08/a… Highlights in the thread! 🧵👇
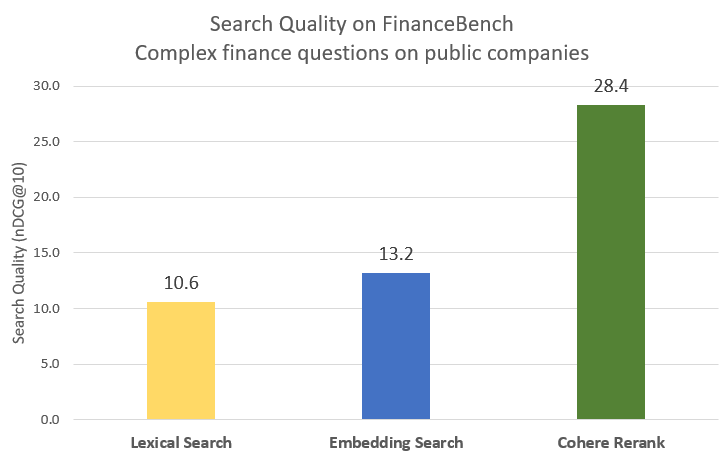

Today, we’re introducing Rerank 3 Nimble: the newest foundation model in our Cohere Rerank model series, built to enhance enterprise search and RAG systems, which is ~3x faster than Rerank 3 while maintaining a high level of accuracy. It’s available only on Amazon Sagemaker.

📢 New preprint 🎉 We introduce "M2QA: Multi-domain Multilingual Question Answering", a benchmark for evaluating joint language and domain transfer. We present 5 key findings - one of them: Current transfer methods are insufficient, even for LLMs! 📜arxiv.org/abs/2407.01091 🧵👇