Sabitlenmiş Tweet

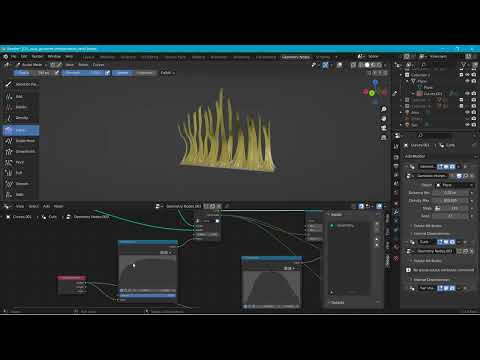
The future of Blender Hair + Node workflow?😉 Been playing around with geometry nodes to get some hair interpolation, clumping and curls going!
Watch the full length demo: youtu.be/2M8F8PvWiA4
#b3d #geometrynodes
YouTube
English
Bert Van den Bosch
711 posts

@bertvdbosch5
CS grad @KULeuven | Engine- & Graphics-Engineer @Cyborn3D




Alpha clip timings (6K res): G-buffer: Discard in main shader: 2.67ms Two shader variants: 1.86ms (70%) Binned (discard last): 1.44ms (54%) Shadows: 2 variants: 0.17ms, 0.10ms, 0.29ms, 0.22ms Binned: 0.10ms, 0.07ms, 0.27ms, 0.07ms (65%) Thread...







Wrote a blog post about the Single Pass Downsampler I implemented for my depth pyramid. Code included. syllogi-graphikon.vercel.app/posts/metal-si…



"I am the bottleneck now" Few more thoughts


Be honest, who still actually listens to music from the 1960s through the 1980s in 2025?

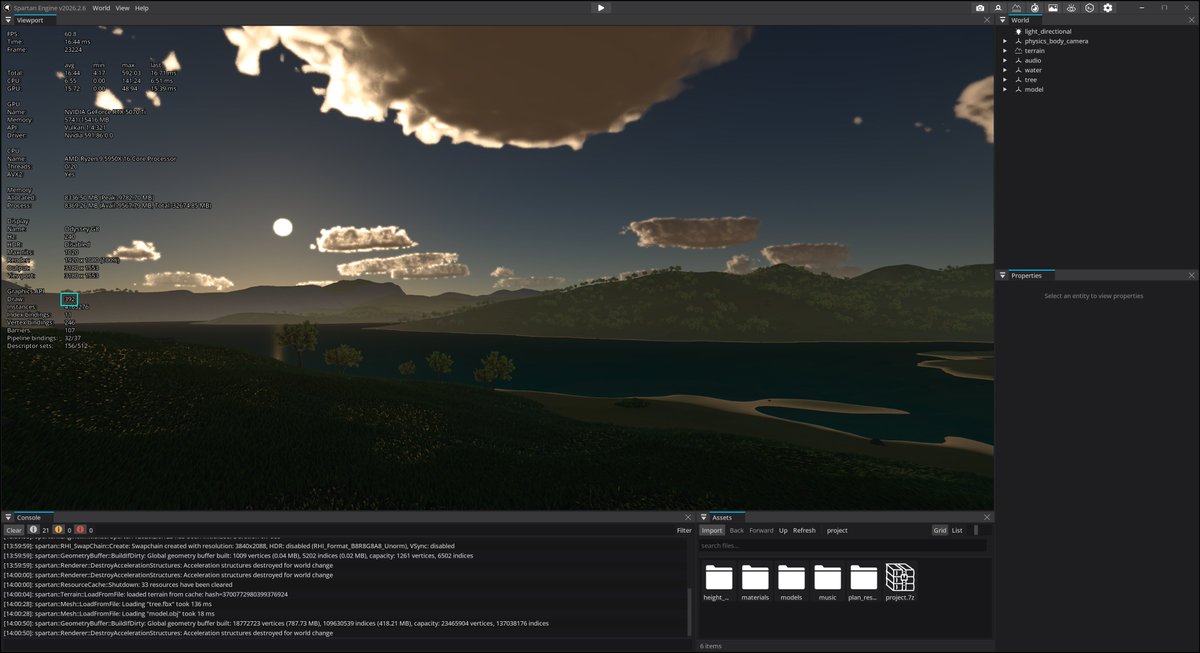
I switched from per mesh vertex and index buffers to a single global geometry buffer that holds everything. This is the same idea id Software used in id Tech for Doom, and you can see the vertex and index binding counts drop, which opens the road for easier GPU driven rendering.

Factions Map running in Uncharted 3 update: I have spawn/respawn locations implemented. Making entire matches possible. Gotta get a friend over for LAN.


