
-‘
657 posts

You spent months engineering around context collapse. Better prompts. Smarter chunking. Careful retrieval.
I've seen this before.
Teams doing a lot of work, just so that one update later, all of that work gets obsolete. This is one such update.
Sub-quadratic sparse-attention architecture, thats a mouthful, but 12 million token context window!?
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English

This is the biggest LLM breakthrough in years.
SubQ IS the first frontier model with a fully sub-quadratic sparse-attention architecture (SSA) + a 12 MILLION token context window.
The numbers are insane:
→ 52x faster than FlashAttention at 1M tokens
→ Less than 5% the cost of Opus
→ Nearly 1,000x less compute by ignoring the 99% of token relationships that don’t matter
No more quadratic waste. No more context hacks.
Early access is open right now (plus their new coding agent SubQ Code).
This is how LLMs actually scale next.
Get it → subq.ai
Alexander Whedon@alex_whedon
Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.
English




People understand that LLMs aren't actually "thinking," right?
Drexel-Alvernon, AZ 🇺🇸 English
@andrewchen Haha WHAT to build is decided by someone who has money and not by somenone who flips states in jira tickets
English

bullish on the PM role quietly becoming the most important role in tech again
when anyone can build, the person who decides WHAT to build becomes the bottleneck
English
@DeepakNesss I would be more afraid of mossad which already has all your data than Chinese
English

Genuine question:
If I use the DeepSeek V4 Pro API via OpenCode, what data could the Chinese mine from me at worst? My entire codebase? Basic info about my computer?
Just trying to understand how exposed I am in terms of privacy and security.
English
@RobertJBye Y but even small model can do this! Whats the advantage then of using opus giga max
English

This use case demo is 🔥
CAD has so many repetitive processes, so using Claude for these will be incredible!
Claude@claudeai
With the Autodesk Fusion connector, designers and engineers can create and modify 3D models through conversation.
English

Super to see Accenture roll out 740,000+ M365 Copilot seats—our largest deployment to date!
news.microsoft.com/source/feature…
English
-‘ retweetledi

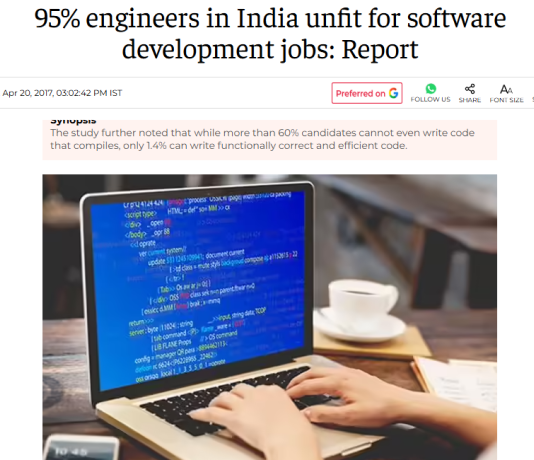
36,000 engineering students from IT programs were tested in India.
95% were determined to be unfit for actually working in the field. Only 1.4% could write functionally correct and efficient code.
India has a massive issue with cheating and scams in education. Fake degrees
English

English



🚨 son dakika : GODSPECTIVE uygulaması tüm dünya’ya sızdırıldı.
Artık tüm dünyada neler olup bittiğini canlı canlı yukarıdan izleyebiliyorsun.
github.com/koala73/worldm…
quanqiuchongtu.com
Türkçe

@claudeai To be honest it looks like its generating themes from themeforest.net
English

Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
English
@petergyang We tried locally 35B for coding. To be honest, its unfortunately useless
English

What is the sweet spot in open source model size? Are 35B models enough for local agentic workflows?
Trying to decide how much RAM I need in a new computer.
Qwen@Alibaba_Qwen
⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀 A sparse MoE model, 35B total params, 3B active. Apache 2.0 license. 🔥 Agentic coding on par with models 10x its active size 📷 Strong multimodal perception and reasoning ability 🧠 Multimodal thinking + non-thinking modes Efficient. Powerful. Versatile. Try it now👇 Blog:qwen.ai/blog?id=qwen3.… Qwen Studio:chat.qwen.ai HuggingFace:huggingface.co/Qwen/Qwen3.6-3… ModelScope:modelscope.cn/models/Qwen/Qw… API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned
English

visits the pope → pope dies
leads Iran negotiations → talks collapse
flies to Hungary to prop up Orbán → Orbán loses in a landslide
Man’s got a streak.

English
@gfodor @kenwheeler Tell that to the guys who wrote attention is all you need paper…
English

@kenwheeler Nobody knows how AI works, anyone who says they do is an idiot
English

i deeply and i mean deeply dislike this man. with every fiber of my heart. and i don’t believe this for a second.
English




As long as the UAE is not in Islamabad, JD Vance and the Islamic regime in Iran will fail in Pakistan. The UAE does not, and will not, accept the Islamic regime in Iran controlling access to the Strait of Hormuz, nor possessing nuclear weapons, ballistic missiles, drones, or any capabilities that threaten regional security. This regime must issue a formal apology to the UAE for its aggression, acknowledge its actions, provide full compensation for any harm caused to individuals and institutions, and guarantee non-repetition. Otherwise, what comes next will be devastating for this terrorist regime.
English