
Bruce21b ⓥ
16.3K posts


📢 Nevin Freeman’s Late March 2026 Core Team Update TL;DR for team $RSR
🔹 Core team moving fast on RToken development & governance upgrades
🔹 ABC & CC teams pushing hard on top priorities
🔹 New AI tools in development for DTF ideas, backtesting, parameter sweeps & analysis
Transparency boost needed: More activity in the forums, delegate votes & DRF contributions!
Major milestone:
Largest $RSR burn ever (16 million tokens) 🔥
Adoption accelerating with CoinMarketCap, Kraken & others.
The future is looking extremely bright!
What do you think ? What focus would you like to see next? 👀
#ReserveProtocol #RSR #DTF
Nevin Freeman@nnevvinn
English
Bruce21b ⓥ retweetledi

We see $PRL TGE happened yesterday and in such terrible market, the token performed so well!
Price went from 0.10881$ -> 0.244$, with total supply 10B, great work.
@PerleLabs built the sovereign intelligence layer for AI.
Raised 17.5$M from @hiFramework, @HashKey_Capital, @coinfund.
As part of the project, we performed data annotation tasks, captchas, farmed points.
Many sybils were disqualified during the registration stage.
Also you would need to scan your palm in the VeryAI app to be eligible.(smart move).
Team used vesting system: 20% immediately or 100% locked for a 6-month staking period.
I wish the team continued success, and I also plan to buy $PRL tokens to hold for an indefinite period.
Good luck to everyone — participating in @PerleLabs community campaign
#PerleAI #ToPerle
English
Bruce21b ⓥ retweetledi

Most people don’t understand how big what’s happening here is.
$PRL had a great launch. At a reasonable rate. They’re churning revenue (I know, I’m an advisor and investor since day 1) and have one of the most upstanding accomplished teams ever to hit crypto.
Outside of us, investors include @naval btw.
But never mind that @coinfund @framework @ExcelsiorVC are backing these chads. Never mind that Ahmed has led this company to strong, scaling strong repeatable, protectable revenues and that his investors love him. (Regular reports detailing everything going right AND wrong so we can help). Never mind that he can CODE AND SELL like a chad.
Google @scale_AI and our CEO @AhmedZRashad - almost every meaningful interview with Alex at Scale has Ahmed in it who was instrumental in building the +$29BN beast it has become.
Then ask yourself: where is this going… and if you can find something comparable outside of maybe the top 5-10 assets in crypto today.
👀
And around him, Ahmed has. Attracted a stellar team like @rthurding and @tiffylung
But most of all… I believe in Ahmed as an entrepreneur that does THE RIGHT thing. One day I will reveal, with his permission, the kind of high quality integrity decisions he made building this company in the early days.
CBInsights states that only 5 startups return on a fund out of 1089 seed stage investments.
I’m betting this is 5 in 1.
Perle Labs@PerleLabs
1% synthetic data in your training set is enough to break your model. Most pipelines don’t even realize they’ve already crossed that line. Here’s what’s actually happening inside AI training today: Every time a model trains on its own outputs, it loses something — rare knowledge, edge cases, the hard-to-capture signals that actually matter in the real world. Researchers call this model collapse, and the math is unambiguous. Most pipelines today are built on: • Data with no clear provenance • Black-box annotation workflows • Models training on synthetic outputs • Bias that compounds with every generation That’s not a data strategy. It’s a feedback loop with a predictable outcome. The fix isn’t more data. It’s better data. Human-verified training data: • Preserves long-tail and edge-case knowledge instead of compressing it • Provides verifiable, audit-ready data lineage • Routes tasks to credentialed experts, not the lowest-cost annotators • Reduces systemic bias through structured, diverse expert pools The models winning in high-stakes domains — medicine, law, finance — aren’t the ones trained on the most data. They’re the ones trained on the most trustworthy data. That’s what Perle is building.
English

@PerleLabs Whenever you post all I smell is scam I don’t even bother reading 🤮 @PerleLabs
English



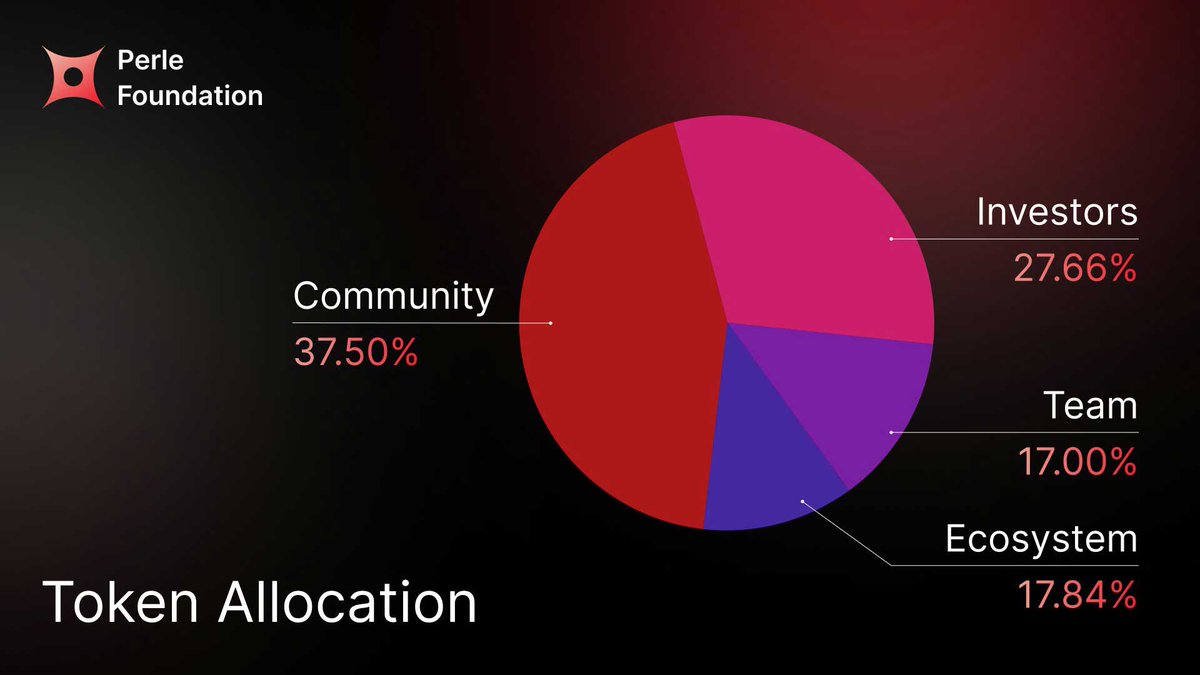
Perle Labs Tokenomics Announced!
So the tokenomics for the upcoming @PerleLabs token is now officially out. Here’s a quick breakdown:
- Token ticker: $PRL
- Total supply: 10B
- Chain: Solana
Token allocation:
- 37.5% to community
- 27.66% to investors
- 17.84% to ecosystem
- 17% to team
At TGE, 7.5% of the community allocation unlocks, and 10% from the ecosystem side also unlocks. Team and investor tokens have a 1-year cliff, then vest over 36 months.
Overall, the tokenomics looks pretty solid.
TGE date is yet to be announced.
English
@Crypto_Pranjal @PerleLabs Total supply is 1 billion, not 10 billion
English
@JesusMartinez @krakenfx You must be krakens new social media tech 🤡
English

I left Coinbase for @krakenfx.
Not because of one thing. Because of everything.
Here's what most people don't realize about Kraken in 2026.
They're not just a crypto exchange anymore.
11,000+ US stocks. 560+ cryptos. Gold. Oil. Futures. All in one account.
Zero commission on stocks.
And if you're just holding cash as a stablecoin, you're earning 2 to 4% APR automatically. Your bank gives you 0.5%.
Some key things that made me switch:
• @krakenpro fees start at 0.25% maker. Lower than most competitors at base level.
• Instant USD withdrawals. 365 days a year. Try getting that from your bank.
• USDG earns yield the moment it hits your account. No lockups. Paid weekly.
• They've never been hacked. Never lost customer funds. Since 2011.
• Wyoming SPDI charter. 100% reserve requirement on cash deposits.
And then this happened.
Nasdaq announced a partnership with Kraken on March 9.
They're building tokenized versions of listed stocks together. Full governance rights. Voting. Dividends.
The biggest tech stock exchange in the world chose Kraken.
Oh and if you hold HBAR, Kraken is running a trading challenge right now.
300,000 HBAR reward pool. Trade the HBAR perp on Kraken Pro, compete based on volume. First 2,000 clients. Runs through March 23.
For international users it gets even crazier. xStocks give you tokenized US equities trading 24/7 with up to 20x leverage in 110+ countries.
Crypto exchanges are becoming the new brokerages.
And Kraken is leading the charge.


English

Which vitamin has made the most difference for your health?
English
@LeddyLLC Its magic for me...helped sleep, mood, anxiety, energy levels and blood pressure
English
English

How many shares outstanding does Ripple have? A 50 billion dollar valuation, with an estimated 170 million shares outstanding, gives you a price of $294/share. This is quite the jump to the last buyback, which was $165/share.
Ripple is on fire! Eventually, this will transition over to $XRP...watch and learn BTC Maxis.
English

📈BUYBACK: @RIPPLE LAUNCHES $750M SHARE BUYBACK
Per @business, Ripple has launched a $750 million share buyback program, offering to repurchase equity from early investors at a valuation of about $50 billion.
The move gives long-time shareholders and employees a chance to sell part of their stake while the company remains privately held
The development could carry indirect implications for $XRP. The $50 billion valuation reinforces Ripple’s positioning as a large fintech infrastructure provider
English
@brian_armstrong Its inflation proof for early adopters. But tell that to the guy who bought at $100k...your balance just took a 40 percent hit. Its not the perfect money or inflation proof
English

The 20 millionth Bitcoin was mined yesterday. Now there are only one million new Bitcoins to be mined, which will take over 100 years.
Decentralized, inflation-proof, global money.
English



You don’t need 20 supplements.
You need the 3 that actually move the needle:
- Magnesium Glycinate (calm, sleep, recovery)
- Omega-3 (inflammation, cognition, metabolism)
- Vitamin D3 + K2 (energy, immunity, hormone support)
Everything else is window dressing until these are locked.
English
QME

71% of $SKR's circulating supply (4.2B out of 5.9B) is staked.
That means 7 out of every 10 tokens could be sold.
But holders are choosing to lock them up instead.
This isn't short-term gambling.
This is SKR believers betting big on the future.
Massive conviction. 🔥


English
@JakeGagain Sold that trash years ago. Solana is the next big thing and Seeker is second
English

@dr_ericberg Magnesium. Take 900 mg and energy and sleep levels are way up
English
Which supplement has made the biggest difference in your energy levels?
English
@coinbase I like it. Along with the coinbase one card I earn rewards every day
English

How to earn more Bitcoin:
1) Hold USDC
2) Flip the switch
3) Earn rewards in BTC every week
Earn unlimited 3.5% rewards, paid in BTC, with Coinbase One. Rolling out now.
GIF
English

So #Vechain launches a new staking model which requires you to lock your crypto for a certain period of time… a week or two after that launch, the price starts to dramatically drop.
Sounds to me like they lured in exit liquidity to lock in so they wouldn’t be able to sell.
English
