
无声
6.5K posts

@liaoping2020 墙外真的是灯塔吗,现在的理解和80年代的差距甚远。当中国即将跨入中等收入国家的行列,中国能走西方式的道路吗更进一部吗?在大争大变之世,个人自由和民族国家整体关系平衡全球都在内敛。没有这方面的愿景和共识,刻舟求剑的谈应该怎样更像是水中捞月。自保自强自立才能立不败之地。
中文

云的局:陈云的本色表演(结局篇)
(老茶深信终有一日,吾人会觉醒到:邓屠夫实乃国贼、全民公敌。其逆转中国国运之后果,也将渐次展开,逼得吾人最终不得不觉醒。)
习的底气从何而来?云早就准备好了一张底牌,这个可能有些耸人听闻,留到最后再说。
一般而言,云遗下的安邦治国之策简化起来就是两条——
云曾云:中国人好管,只要不饿死就不会起来造反。稳定民生的办法乃是“低工资、高就业、外加补贴”。
云又云:《新闻法》不能搞……蒋介石那个时代搞新闻法,而且搞得挺像样,被我们抓到了漏洞……我们党要管新闻才好!
此即云的两手,填饱肚子,捂住嘴巴,即能长治久安。
云的治国策中,却留有一个巨大的漏洞,就是墙国之内不都是韭菜,还有一帮姑且称为“红八旗”(此处借用苏晓康先生的提法)的群体。
邓在“六四”大开杀戒之后,已经对这个群体完全失去管束之力。你为维持权位都可以用坦克、机关枪、达姆弹血洗北京,我们这些小贪小腐又算得了什么呢。
“长者”深谙此道,一句“闷声大发财”引来“红八旗”全面狂欢,如痴如醉,廿年一觉扬州梦,不爱江山爱美元。
江记“闷声大发财”一语,就其影响力和持续性而言,以少少许胜多多许,完全秒杀在“文革”中的任何一条毛语录,可入吉尼斯世界纪录。
不单“红八旗”,那些绿油油的韭菜同样兴奋不已,赚钱买房买地娶妾,是千年不变的华夏梦,毛时代被压抑的本能从此决堤。
说老百姓痛恨官员腐败,已成笑料。韭菜痛恨的不是腐败、而是自己缺少机会参与腐败。
“六四”的悲剧说到底乃是全民的悲剧,只是各自付出的代价有别、创伤后遗症的表现形式不同而已。
所以,老茶深信终有一日,吾人会觉醒到:邓屠夫实乃国贼、全民公敌。其逆转中国国运之后果,也将渐次展开,逼得吾人最终不得不觉醒。
胡温十年,美其名曰“不折腾”,他们更像是看守政府的掌柜,击鼓传花,把财富和雷放在一个花篮里,留给东家。
习接过这个花篮之时,“红八旗”们更加高潮,他们痛恨那些伙计、掌柜们中饱私囊。他们来直接割韭菜岂不更好,能省掉多少中间费用。
“红八旗”这一群体大多已经肠肥脑满,被资本围猎,已经是国之大患。
习思考的两大难题即是如何处理被资本围猎的权力以及权力该如何去围猎资本。
正如胡面瘫所言:“困难关头,人们总是希望听到陈云同志的意见,他也总是能够不负众望,洞悉全局,抓住要害,及时拿出解决问题的有效办法。”
云不在了,习只好从其遗教中学习,首先考虑的是如何把“红八旗”关进云所说的“笼子”,切断其对最高权力的非分之想。
前面提过,云的“鸟笼”理论被坊间大大简化和污名化了。
“鸟”与“笼子”,云最早比喻的是市场与计划的关系,借以揭示搞活经济与宏观控制的要义。他说:“鸟不能捏在手里,捏在手里会死,要让它飞,但只能让它在笼子里飞。没有笼子,它就飞跑了。”
云后来发挥说:“不一定一个省就是一个‘笼子’,‘笼子’也可以大到跨省跨地区。”云要会见五届全国人大五次会议上海代表团,在审阅谈话稿时,又亲笔加了16个字,即“甚至不一定限于国内,也可以跨国跨洲”。(见朱佳木《陈云经济思想的几个要点》)
由此可见云的志向高远。
云的“笼”兼有宏观调控及经济活动范围之意,“笼”的涵义与时俱进。
1984年夏天,云又提出“对外开放不一定都是人家到我们这里来,我们也可以到人家那里去。”“我国富矿很少,如果能从国外进口或合资开采矿山,当然很好。”他同意利用美国“加勒比海发展计划”的有利时机,向该地区投资办厂。云的笼子里什么都装得下,如同如来佛的“袖里乾坤”或东来佛祖的“乾坤袋”。
云的“鸟”又是个什么鸟?似有两重义,既指自由市场,亦指市场中的各种经济主体,自由地在两者间切换。
朱佳木在上文中说:“今天,我们已经不实行计划经济了,但仍然有国民经济发展的五年计划、十年规划,还有宏观调控的目标,有各种法律法规……这些不是也像‘笼子’一样起着限制经济微观运行盲目发展的作用吗?如果没有这样的‘笼子’,岂不真的会让各种经济主体像‘鸟’一样脱离国家宏观控制而‘飞跑’,造成经济失控、比例失调,甚至国有资产流失、使私人资产向国外转移。”
这看似鼓吹云,其实是在向今上献策,我们得扎好篱笆,可以在笼子里搞内循环。
习的史观主体是“二百年痛史”,他大概知道,1840年全世界总人口约12亿。而现在笼子的人矿超过了当年世界的总人数,即便是习活到150岁,也取之不绝用之不尽。
笼子不是铁门,鸟笼理论不是完全的闭关锁国。但进可攻,退有守。
这就是习的底气,不是那些临时工们能有的。
这也是云留下的一张底牌,中国最暗黑的前景。
墙内诸君思之,如何破解云布下的局。
茶先生@liaoping2020
云的遗产或遗毒:陈云的本色表演(6) 孟浩然诗云: “人事有代谢,往来成古今。 江山留胜迹,我辈复登临。” 2012年秋,落英缤纷、人事代谢后,习身登绝顶,极目四望,当作何感慨? 他感激毛?他心想要是前朝任何一朝,他爹地出生入死,杀人无数,怎么也天经地义换到一个世袭罔替的铁帽子王吧,而在毛时代,却成了幻想,习家和习本人遭了多少罪? 他感激邓?自己遭了那么多罪后,好不容易熬成了耿飚秘书。耿却很快被邓排挤,丢掉军委秘书长及防长职位。习家因此得从头再来,为习重新谋画出路…… 习会感激谁呢? 谢苍天,谢大地,其最为感恩的或许就是历史,他能登上大位,仿佛出于历史深处的某种神秘的“补偿机制”: 父辈多少次出生入死的付出总算有了回报; 自己多少年卧薪尝胆的努力终于赢得江山! 而,何谓“江山”呢? 坊间传说,云有这样一句实话:红色江山是两千万人牺牲得来的,你们想要,拿人头来换! 红色江山的“红”字,云的语系里,不仅是指意识形态,更多了血统论色调。 习亦称:“江山就是人民,人民就是江山。”潜台词中,人民大约也等于人头。云和习说的或许完全就是一回事,是密不外传的家法,是最大的政治。 习上演的戏码,不是云爱听的“闯王进京”,而是“王子复仇记”。 小王子们一开始也亢奋,纷纷加入或跃跃欲试,以为这是一曲群舞的《天鹅湖》。 张又侠的倒台,它们才后知后觉,上演的是一个人的独舞,是《天鹅之死》。 能有反抗之力者要么死了要么进去了。留下来的是白雪公主和六个小矮人。 所谓红色江山最后褪色为习家家山! 回到这一戏剧的序曲。1981年春夏之交,云在杭听评弹,忽有所感,写下《提拔培养中青年干部是当务之急》,分送邓、耀邦和宋任穷,并问“可否在六中全会时议论一下青年干部的问题”。 邓沉默,再催问,邓说:“老干部方面的问题还没有处理得好。” 云反复和邓交流,取得邓的支持,于是有了“第三梯队”。 李锐及阎淮都是建立第三梯队的具体操盘手,《李锐日记》和《进出中组部》里都有大量干货,揭示云如何操控“第三梯队”的构成。 20余年后,包括习在内几乎所有17届及18届中共政治局常委均出自这个“第三梯队”。 这可谓云创造的奇迹!换言之,多少年后,共产演员云的阴魂依然不散,还在继续演出。 云铺好的组织管道中,习亦步亦趋、从不越雷池一步,从无一个自选动作,以匍匐前进的憨厚姿式,到达权力的顶端。 “君子豹变”,习登极之后的种种表演,让王子们瞠目结舌。 对此,毛、邓、云的阴魂们又会分别作何等感慨呢? 习和这些阴魂,有着何种剪不断理还乱的关联呢? 前文提到,吴国光教授@guoguang_wu 对此一句精到的总结:“毛泽东的根子,邓小平的藤蔓,结出了习近平这个毒瓜”。其中一以贯之的逻辑是坚持“一党专政”。 吴先生还在其他地方谈到,三人一以贯之的还有:“枪指挥党”,把持军权牢牢不放。 这都是不刊之论,老茶“举双手、举双脚赞成”(此处调侃邓)。 此大前提下,是不是可以进一步讨论三人共有的“一党专政”、“枪指挥党”,具体到人,其专政方式和指挥方法上的细微不同呢? 毛“和尚打伞☔️,无法无天”,不赘言。 邓祭出四根绳子,当年“理论务虚会”一片非毛声中,其提出“四项基本原则”,一锤定音。 今日回看,这四根绳子却并没把人捆得过死,还留有不少活动空间,否则不能解释八十年代的“黄金十年”。 举一个有趣的例。 秦晖先生曾这样自述往事: “1989年5月23日陕西省委发表了支持戒严的效忠电,同时通过党组织系统要求党员人人表态。本来我也许还会选择沉默的,但不许我沉默。我总不能昧着良心表态吧? 于是我就写了与其他几个党员教师贴出‘5.24声明’,这个声明当时仍然是基于党员身份写的,言词不‘激进’,除了指5.19决定与5.20撤赵违反党章、申述党员民主权利外,还把‘四项基本原则’用于反专制而不是反‘自由化’: 声明要求‘坚持党的领导,反对个人独裁;坚持社会主义,反对封建主义;坚持马克思主义,反对中世纪神学与异端审判;坚持人民民主专政,反对专人民民主的政。’ 就这样我卷入了当时已经明显要失败的运动。这个声明当时在西安颇有影响,我这样‘坚持四项基本原则’的后果也可想而知了。”(见Perry Anderson《知青九年—秦晖访谈录》 坚持“四项基本原则”尚可用来反对邓李杨发动军事政变,可能是邓制定四项原则时完全没有预料到的。 习单靠“四项基本原则”根本无法堵住众人悠悠之口,甫一上台,2013年1月在中央党校抛出“两个三十年互不否定”,3月首访俄罗斯(这也改变了中共总书记首访朝鲜的惯例),感叹苏联人民在危机中“竟无一人是男儿”…… 胡耀邦之子胡德华对此百思不得其解,在《炎黄春秋》杂志2013年4月餐会上做了长篇发言,提出尖锐批评,这篇发言网上还在,chinadigitaltimes.net/chinese/299658… 当年即被广传。 然而,胡德华得到的回应是,4月下旬,习抛出了“七不讲”: “普世价值/新闻自由/公民社会/ 公民权利/中国共产党的历史错误 /权贵资产阶级/司法独立不要讲。” 习冒天下之大不韪的底气从何而来? (待续)
中文
@hankinbeijing Why dont u put Jassen's video on post-Moore Law? Maybe u think Ms He is not qualified to benchmark Jassen. Before yesterday do u remember Ms Huang's speech? Did Ms Huang bring up any actual products, any roadmap, any tech details? U r messing up Jobs with Von Neumann.
English

@yuyue_chris 以前只有一条独木桥而且被卡死,现在有发现另外一条路,同时攻克独木桥也没有放弃。现在为止,A股的芯片都是在喝美国AI剩下的汤,谁入英伟达的供应链,就炒谁。但话语权,指挥棒不在手里。华为的路线是先锋引领作用,产业链,资本,政府都准备列队冲锋了。这个的涟漪效应不可小觑。
中文


The fundamental reason that Defense Ministry Dong Jun does not come to Shangri-La is that it is an open forum where he cannot dodge hard questions about Chinese militarism and its aggression against Taiwan and in the South China Sea.
Philip Shetler-Jones@shetlerjones
Why China’s defence chief may skip the Shangri-La Dialogue again straitstimes.com/opinion/why-be…
English
@zephyr_z9 Their biz model is more like Apple rather than other mobile phone manufacturer. Is SMIC cheaper than TSMC? And their smartphone SRP is only next to Apple in China and No 1 in mkt share.
English


@HeQinglian 中国当老二蛮好的。只要平起平坐第一第二不就是个虚名吗。但有好事之徒,天天看着中国不顺眼,要这要那,要搞中国。感觉,现在是美国例外主义,中国想要的是中美例外主义。当然中国会含蓄点身段会更软,同时有分寸感,谁是老大还是拎的清的。
中文

其实,自川普访华之后,我一直有句话想问:中国做好当世界一哥的准备没有?自己的家底自己最清楚。
美国为维持一哥地位,长期不惜血本为世界提供秩序这一公共品,本国人民的福利不如欧洲。欧洲上大学免费,美国人得借学贷;欧洲人医疗免费,美国人还得付昂贵的医保,种类差点的还得自付一些药费。美国的基础设施落后,不少人去中国看后自惭形秽。
一句话,大哥不是白当的,得花真金实银购买追随。哪天不花了,徒惹他国怨恨。中国人愿意这样么?
中文

@fi56622380 邪修也能成正果啊,估计光刻机那条路也没闲着。只要能走通,成本不是大问题,TSMC NVIDIA利润这么高,华为少赚点国家补贴点,算的回来。感觉迄今为止是中国在喝美国AI的红利的汤。有可能真正的军备竞赛快到了。
中文

据消息人士透露,中国最高军事官员预计将连续第二年缺席亚洲规模最大的防务论坛,从而将开展公开防务外交的机会拱手让给美国及其盟友。
—————
这是新加坡举办的“香格里拉论坛”,中国去年就没去,今年也预计缺席。不过秋季应该有“北京香山论坛”,有事来北京吧。
Bloomberg@business
China’s top military official is expected to skip Asia’s biggest defense forum for a second year in a row, sources say, ceding to the US and its allies an opportunity for public defense diplomacy bloomberg.com/news/articles/…
中文



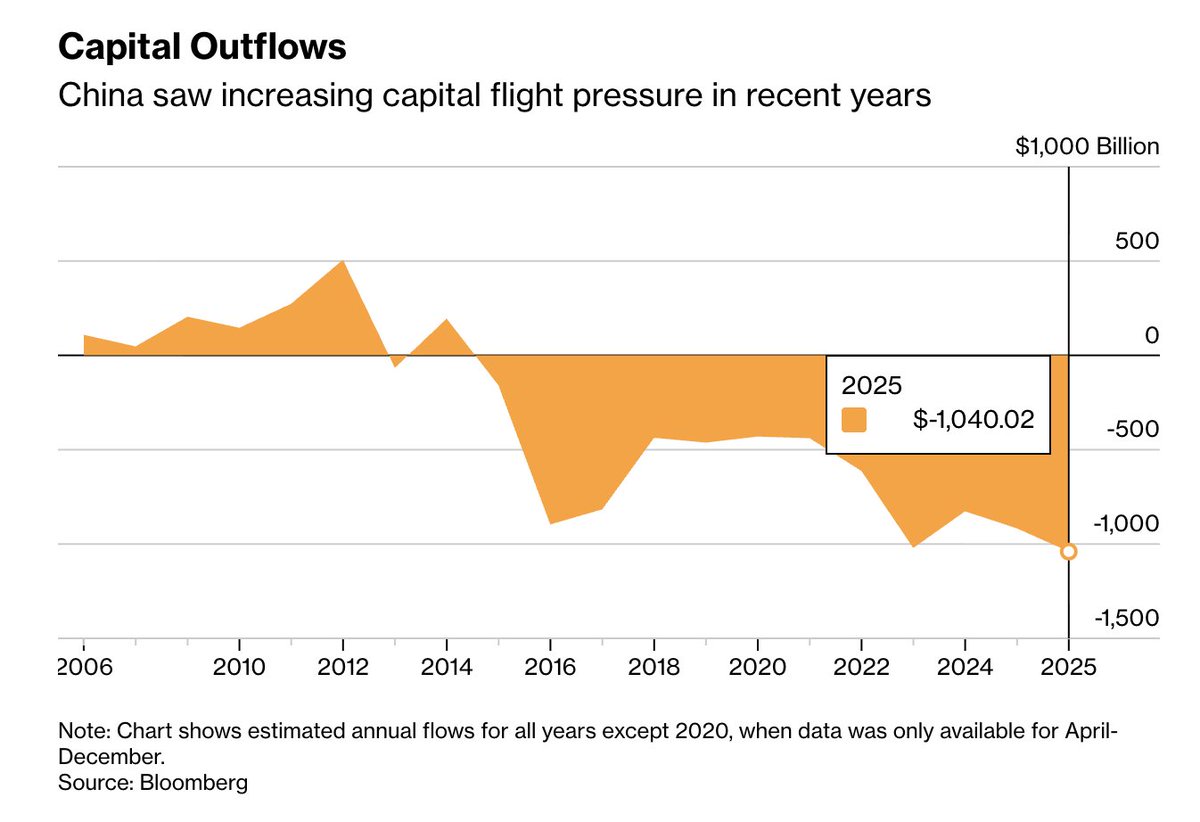
根据Bloomberg的数据统计,中国2025年资本外流已经超过1万亿美金;这些年趋势不断恶化
这些“热钱”是如何流出海外的?具体到居民端:
--包括通过地下钱庄,由经纪人通过“互换协议”(在海外交易美金,国内交易人民币);
--或者就是利用每年5万美金的额度,来进行境外投资;
--还有就是通过人民币购买境外保单,再在境外退保,套现外币(美金/港币等)的方式实现资金变相出境
根据中信证券估计,目前内地投资人在富途和老虎证券的投资规模总计约2000-2500亿港币左右;港股日均成交额约2600亿美金;(因此,证监会等八部委联合打击活动对整体市场的流动性影响可控)
........................
但这次八部委联合打击证券/期货/基金非法经营活动,本质上还是因为中国的资本外流趋势太严重;要知道中国的外汇储备总规模不过3.4万亿美金; 而过去这些年,外资在中国的经营利润总额合计大约在1-1.5万亿美金左右,这些钱如果要求换汇,汇出中国,理论上中国政府是不能拒绝的;所以,中国政府正真能动用的外汇大约就是在2-2.5万亿美金左右
所以越来越严重的资本外逃风险,令中国的金融安全和国家安全受到影响;中国整体上还是一个大量资源品,农产品等需要进口的国家,所以对外汇储备有底限要求
这次打击可以说是全方位,立体式,且毫不手软;没有转圜空间。未来内地居民想要投资海外,就只能通过港股通,QDII,合法理财渠道了.
金融汪@yuyy614893671
重罚22亿,证监会等八部委重拳出击,打击非法跨境券商!富途, 老虎暴跌!中概股暴跌!怎么了?为什么?怎么办? 境外券商|境外股票投资 |中国投... youtu.be/l3gOdEF9Gro?si… via @YouTube
中文

中文

韬定律: 拳打阿斯麦,脚踢台积电?
我,
绕过EUV,
在成熟制成上大突破,
2031年对标1.4nm。
我,
拳打阿斯麦,
脚踢台积电,
掀翻SYNOPSYS,
我,
三分靠技术,
七分靠故事,
我是💎级营销大师,
我为自己带盐。
事实是什么呢?
LogicFolding,在学术圈不是新词。
Temporal logic folding作为术语,至少可以追溯到 2014 年的 monolithic 3D IC 论文(普林斯顿等机构在 RRAM + FPGA 异构架构里就用过)。
Intel 的 Foveros、TSMC 的 SoIC、三星的 X-Cube 走的都是 3D 堆叠这条路。
所以,XX做的是工程实现 + 命名权抢夺,不是物理定律突破。
摩尔定律是经验观察加自实现预言,韬定律本质是一个跨层PPA优化方法论,也即把τ(时间常数)作为从晶体管、电路、芯片到系统的统一优化变量。
把方法论包装成定律,在中文语境下传播力极强,但放到IEEE这种学术场合里,更像是提出一个framework而不是发现一个定律。
最该当心的话术是2031年达到1.4nm等效密度这种情绪话术,这是density-equivalent,不是 process-node-equivalent,更不是性能等效。
事实上,台积电A14在2028年量产时,单管性能、漏电、能效仍然是XX这条路在物理层面追不上的。
那些赢麻了,赢上加赢的媒体和自媒体,硬核制约他们是一个都不提。
比如,散热是3D堆叠的死穴,垂直堆叠后单位体积功率密度暴增,2.5D/3D已经普遍要靠 DVFS throttling 才能稳定运行。Kirin 是 SoC 功耗几瓦级别,问题还能管理;上到 Ascend 数据中心 GPU(几百瓦到 kW 级),热阻问题指数级放大。论文自己也承认τ 是 law of time, not law of joules。
再比如Hybrid bonding 的良率和成本约束,行业共识是 hybrid bonding 在 HBM 上的大规模采用要到 HBM4E(2026-2027)才到拐点。Adeia/Besi 等设备方都说核心问题不是物理上限,而是yield and backend process control”。XX说做到接近100% 良率靠 redundancy 修复,但成本能不能扛得住,压根不会披露,因为这是他的死穴。
再比如EDA 工具链的约束,韬定律全栈实现需要把多层堆叠当成一个连续设计实体,传统 2D EDA(Cadence/Synopsys/Siemens)都没准备好。论文里说XX有初步内部工具,但这条短板非常长。
EUV 能绕开吗?抱歉,依然要 DUV 多重曝光,5nm 等效靠 DUV multi-patterning,掩模数从 60-70 层涨到 80+,单 wafer 成本和良率都被压,SMIC 现有产能不可能短时间扩到能覆盖麒麟 + 昇腾全系列。
还有381 颗芯片的水分,六年量产 381 款,听上去碉堡了,但大部分是低端 ASIC、汽车控制、通信类,能用上 logic folding 高阶版本的就麒麟 + 昇腾两条线。这是传说中的以量取胜?
中文
@kaiwangyu @Compute_King 文明首先要有尊严,平等,公平。有人命令你做啥,不听就私刑,要饿死你。把人按亲属远近分三六九等底层永远是底层,如果这是文明那不要也罢。西方文明是山巅之城加一片荒原,你找着西方的药方做也进不了山巅之城,因为没地方了。
中文

@caiming @Compute_King 举国体制,牺牲掉了多少百姓的利益,你是能自由买卖华为股票,享受红利?还是国家放弃了资本管制,自由汇率,让你买美股?文明不应该如此
中文

笔者真诚地认为,华为是中国最重要的科技企业之一
因为谈到21世纪最惊心动魄的中美科技博弈,就绕不开华为。它已经不再只是一个科技公司,更是这场博弈中的核心承压者。。。
1987年9月,任正非老爷子拿着东拼西凑的2.1万元注册资本,在深圳的一栋破旧居民楼里创立华为时,大概率不会想到,自己其实已经踏上了一段伟大的科技进程。。。
39年后的今天,华为和中国稀土产业一样,已经成为支撑中国科技防线,成为未来反守为攻积蓄力量的重要支柱之一。
当然,再好的企业,再大的成绩,网上也会有很多人冷嘲热讽。而且很有意思的是,这类声音很多恰恰来自中文圈(简中为主,繁中为辅)。不过这其实也正常,再好的事情,也总会有人看不顺眼。
毕竟,想要你好,又怕你开路虎。而世界本来就是多元的。。。
但无论外界如何评价,笔者依然真诚地认为:华为已经在科技历史上留下了自己的位置!

Compute King@Compute_King
论文里更多的思考: AI算力集群大量消耗电力,而且其中80%的电力和70%的成本并没有用于计算,而是被“Data Move”和数据的“Load/Save”消耗掉了 。 为了在宏观尺度压缩这些开销,华为在论文里面提到了三样东西: 1,Unified Bus(统一总线):这个我们之前好好地聊过,UB放弃了传统的复杂堆叠协议(PCIe, NVLink, 以太网等),采用内存语义的底层直接互联。这让端到端的远程访问延迟从数十微秒骤降至约100ns(指数级缩减),在多机柜甚至机房的规模上实现了“系统即芯片” 。 2,Hi-ONE(近封装光引擎):这种光学I/O单模块可提供8 Tb/s的带宽,将传统电SerDes的传输距离需求从100厘米骤降到约5厘米,同时将机柜间的互联距离扩展到100米,在物理层面保障了高密度计算 。 3,3D Folding:传统意义上的2.5D封装中,算力随芯片大小增长,但也受限于芯片大小。还记得之前的Cowos-S和给GB300用的Cowos-L? 华为的3D Folding强行将供电(背面供电网络),高速内存和光I/O从芯片的“边缘”转移到了垂直“表面”,这就有点意思了,大家都具备了3D的扩张能力,可以彻底让带宽与算力实现了同频共振 。。。
中文

@hankinbeijing 华为越先进,中国就越封闭。The more advanced Huawei becomes, the more closed China becomes.
中文

True. China's domestic sentiments towards Huawei - def not unitary - really need to be translated into English more often than they have been. Not every person likes Huawei, particularly if you are in the semiconductor or telecom biz - either as competitors or gov watchdogs.
Lei Gong@gonglei89
@hankinbeijing I think unfortunately people who aren’t plugged into China’s internal discourse would be very confused why a Chinese person who favors their country might still have some apathy towards Huawei 😅
English

【#老马股市评论】今天 #A股 #半导体 大涨,盘后各种小作文满天飞,其中最吸引眼球的是所谓华为的“ #韬定律”。
尽管我认为半导体还处于景气上行期,但短线我倒要泼冷水了:追高要谨慎。如果成本低而且准备长持,可不管;如果想冲进去捞钱,小心。
下面我们来看看华为的“韬定律”究竟是个什么东西:
华为提出的“韬定律”在工程实践中是有效的,但在全半导体行业作为“通用公理”仍有待时间检验。
这一定律的核心逻辑是:在由于外部限制导致“先进制程几何缩微”受阻时,通过“时间缩微”来替代。
即不再一味追求晶体管尺寸变小,而是通过“逻辑折叠”(将电路从平面单层变为多层立体堆叠)、系统级总线重构和全栈软硬协同,持续压缩数据信号的传播时延,从而在较粗的制程上换取等效于更先进制程的系统级性能与晶体管集成密度。
对其有效性可以从以下两个对立面进行客观评估:
为什么说它“真有效”(技术与成果支撑)
证据1:量产结果佐证:
华为海思在过去 6 年时间里,基于这套全栈协同与时延优化体系,已经成功设计并量产了 381 款芯片,广泛覆盖了通信、计算(昇腾)及汽车等垂直赛道。
证据2:麒麟芯片实现突破:
最新的行业实测数据显示,应用了“逻辑折叠”等技术的最新款麒麟芯片,其晶体管密度相较于此前大幅提升了 53.5%(达到 2.38 亿每平方毫米),核心能效提升了 41%。
这证明在不依赖极高精尖光刻工艺的情况下,依靠设计复杂度确实大幅缩窄了与台积电 3nm 等工艺的系统级差距。
证据3:长远蓝图清晰:
华为官方公开预计,到 2031 年,基于“韬定律”的高端芯片通过多层级体系缩微,其系统级晶体管密度将能达到 1.4 纳米制程的同等水平。
它的局限性与挑战(为什么不能盲目神话)
等效不等于物理等同:
这种系统级性能的提升,本质上是“用设计和封装的复杂度去弥补工艺差距”。
在手机 SoC 这种对功耗、散热以及芯片面积(寸土寸金)极度敏感的设备中,“折叠”和复杂封装可能会带来更大的芯片面积(Die Size)和更高的散热压力。
生态护城河难以轻易复制:
“韬定律”需要极高门槛的“芯片-架构-软件-系统”四层级全栈调优。华为能玩转是因为其拥有“海思芯片设计 + 鸿蒙系统 + 方舟编译器 + 昇腾/鲲鹏生态”的闭环。
对于绝大多数缺乏这种全栈掌控能力的普通芯片设计企业(Fabless)而言,根本不具备跟进和落地的能力。
尚未成为全行业共识的“通用定律”:
当年的摩尔定律之所以伟大,是因为它绑架了全球代工厂、EDA、IP提供商的步调。
而华为的“韬定律”目前更多属于华为自己的工程哲学和解题思路。
要让全球产业链重新对齐它的度量框架,至少需要 5 到 10 年的市场说服周期。
💡 总结
华为的“韬定律”在技术手段上完全真实有效,是当下中国半导体行业在面临外部工艺限制时,成功蹚出的一条极其卓越的“系统工程突围路线”。但它并非无痛的魔法,其背后需要付出巨大的设计成本与极强的软硬件闭环能力作为代价。

老马投资研究@LMDFinance
中文