Sabitlenmiş Tweet
Carlos Calva
4.9K posts


Carlos Calva
@carlosaddsub
Founder & CEO @ MidBrain Experience based learning for AI agents Prev: AI + Spatial Computing Researcher | XR + AI astronaut training and ops tools for NASA
Neural perception of "reality" Katılım Mart 2018
3.1K Takip Edilen1.8K Takipçiler



Carlos Calva retweetledi

The CEO of Take-Two, the company behind GTA, just said something the entire AI industry doesn't want to hear.
And he said it without being anti-AI.
Strauss Zelnick's argument is precise. AI is built on datasets. Datasets are backward-looking. Creativity is forward-looking. A model trained on everything that already exists cannot, by definition, produce something genuinely unexpected. And all hits, by their very nature, are unexpected.
Asset creation and hit creation are not the same thing. AI is getting very good at the first one. The second one is what actually makes money, builds franchises, and changes culture. Nobody has shown AI can do that yet.
The derivative property problem is real. You can clone GTA with existing technology. You could do it before AI. It would take 3 years and look identical. It still wouldn't sell. Because it isn't GTA. It's a clone of GTA.
And consumers, despite what the industry occasionally pretends, can feel the difference between something genuinely new and something assembled from the residue of things that already worked.
Thousands of mobile games ship every year. 0 to 5 hits get made. The same studios make them every time. The technology to make more games has been commoditized for years. It didn't democratize hit creation. It just flooded the market with more forgettable product.
The Silicon Valley thesis that AI unlocks game creation for everyone is true in the same way that cheap cameras unlocked filmmaking for everyone. They did. And the same 5 studios still make the movies everyone watches.
What Zelnick is saying, without quite saying it, is that the thing AI cannot replicate is taste. The instinct for what hasn't been done yet. The cultural antenna that detects the gap in the market before the data can see it.
Data tells you what people wanted. Hits tell people what they want next.
Those are different jobs.
Mario Nawfal@MarioNawfal
🇺🇸 Tucker lays out the deepest critique of AI yet, and it's not about jobs... His argument: writing produces thinking. You can't formulate a thought without first articulating it. If kids never write because AI writes for them, the quality of human thinking collapses. That's the surface problem. The deeper one is purpose: "The point of living is to create. That's the point of being a human being. It's necessary for joy. There is no joy without creation." If the machine creates everything and humans just consume, you don't get utopia. You get despair, mass unemployment, and eventually political revolution.
English
Carlos Calva retweetledi

imagine a software startup raising $800m before their first dollar of revenue. Can’t imagine it
the last two decades of software has been dominated by a simple theory: ship quickly, get customers early, generate revenue quickly to validate PMF, manage KPIs closely, etc. This became the dominant theory over all others
The next decade is going to have a long wave of hardware/robotics/deeptech/etc that will have a dramatically different profile. We’ll need a very different set of assumptions and theories soon
Chart credit: @atShruti

English
Carlos Calva retweetledi
Carlos Calva retweetledi

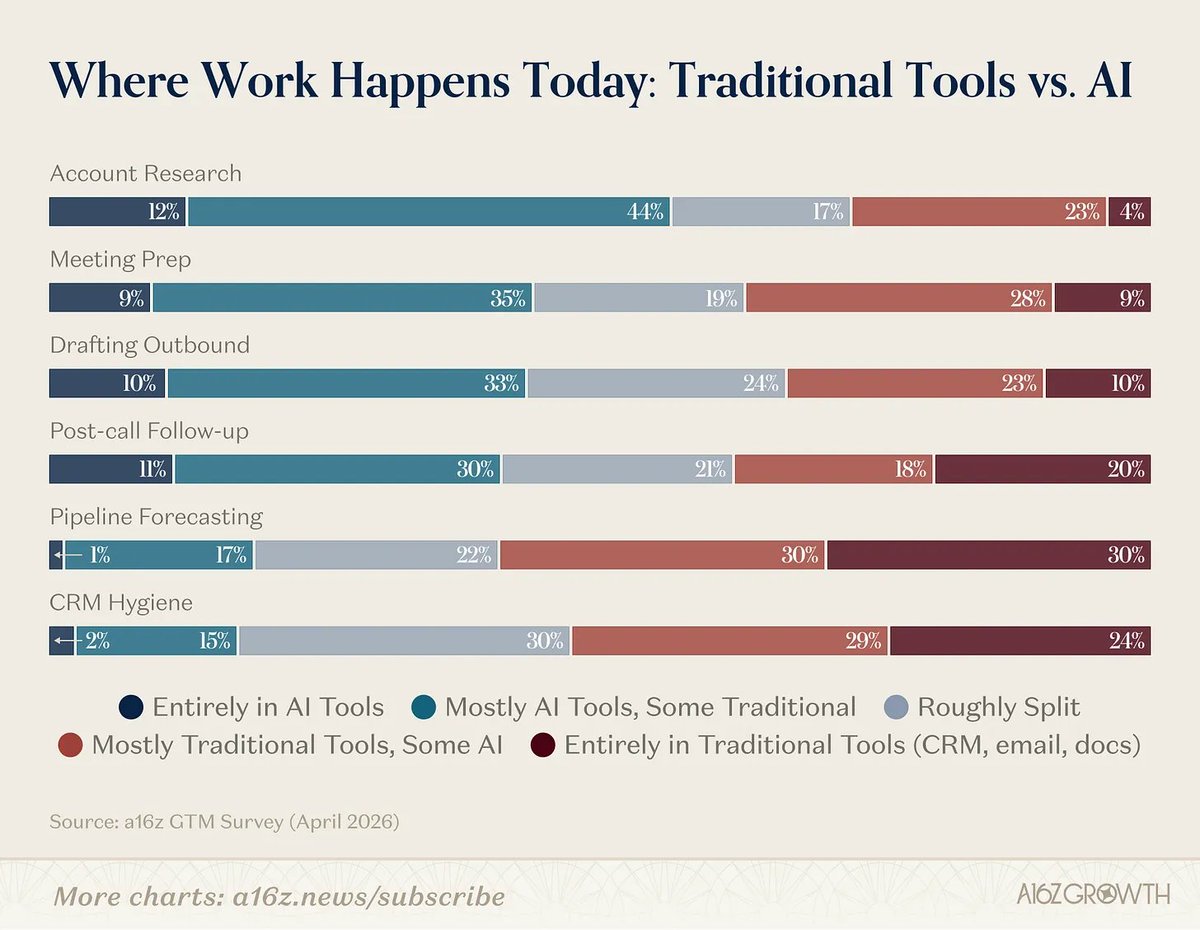
From "System of Record" to "System of Intelligence"
In the next decade, you want to own the system of intelligence that pulls from the system of record, becomes the user’s one-stop shop for gaining context and taking action, and turns the SoR into something that’s primarily consumed at the API layer.
The reasoning layer that sits above the database is where a new generation of companies is being built, and it’s where the majority of the next decade’s enterprise value of GTM software will end up.
Full piece from a16z's Gio Ahern, Steph Zhang, and Alex Immerman: a16z.news/p/from-system-…
Steph Zhang@steph_zhang
English
Carlos Calva retweetledi

What happens when AI starts building itself? techcrunch.com/2026/05/14/wha…
English
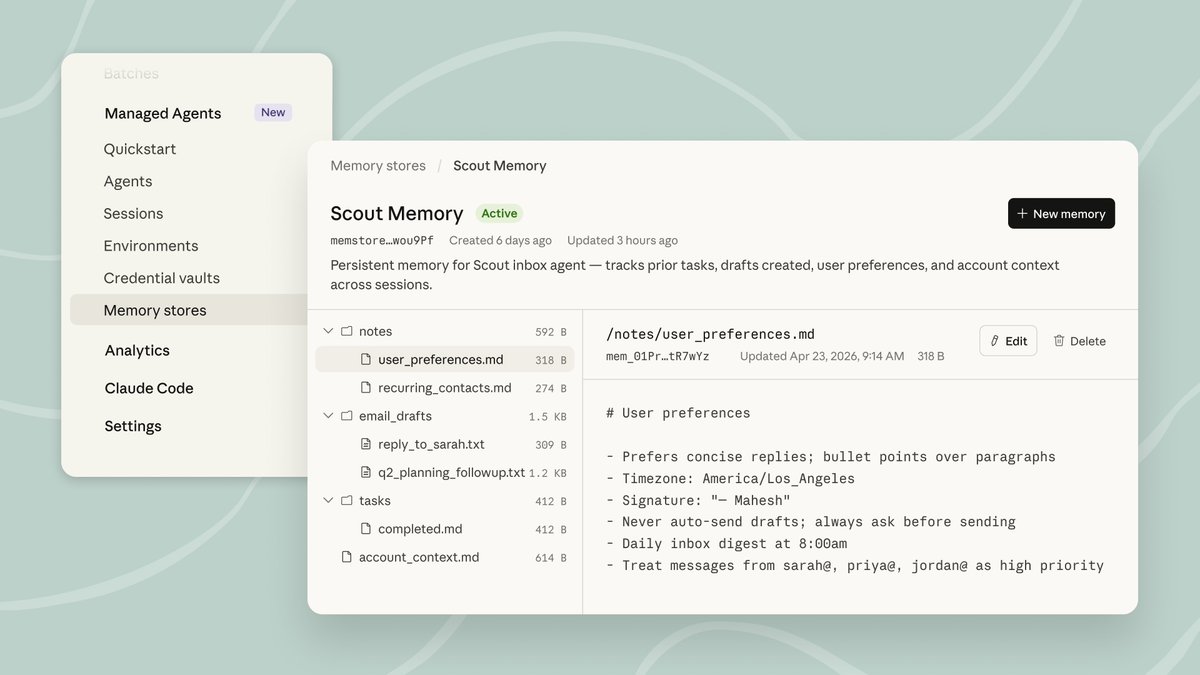
Memory stores facts. Experience changes behavior.
On our upcoming panel we’ll discuss the difference: memory systems retrieve information; experience systems store interactions, update internal state, and use that evolving context to change how agents behave proactively, contextually, and with less friction for users.
We’ll discuss implications for product design, evaluation, and real-world deployments: how to measure impact, avoid misleading benchmarks, and build agents that learn continually rather than just recall.
Join @CeciliaMTham @rryssf , @itzik009 and myself to hear examples, trade-offs, and actionable design approaches for making AI feel trustworthy over time.
May 14th at 1:20pm CST (2:20pm EST, 11:20am PST)
AI Skills Conf on May 14.
Register here: conf.cosprints.ai/?22

English

i’m actually impressed that twitter engagement farming has convinced some of you to become genuinely retarded.
couple clarifications.
nia by @nozomioai makes me 7 figures in recurring revenue, and we’re actively working on it with multiple releases planned.
folk by @nozomioai is a SIDE project i built in 2 days after finding a very unique insight about the market that doesn’t even apply to twitter, so i don’t really gaf about marketing it here. my team is just so goated that we can easily produce any kind of video any day.
folk is powered by nia’s API, so there’s a very clear way to experiment with how context can be applied across different domains. i didn’t expect it to make me more money in 6 days than nia did in its first 3 months, so why not experiment further?
so all the mfers saying i’m a scammer or that i pivoted to an openclaw wrapper can go fuck themselves 🤣🤣
oh and i signed another contract.

English
This is so true, I’ve been doing it for months and so has everyone at MidBrain.
It should almost be a default output. Specially for when the output goes beyond conversational. It’s so much easier to process information this way than a heavy block of text in a CLI/app.
More so you can fully personalize the output and create rules for different types of output (dashboards, presentations, decks etc)
Andrej Karpathy@karpathy
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status… There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
English
This is so true, I’ve been doing it for months and so has everyone at MidBrain.
It should almost be a default output. Specially for when the output goes beyond conversational. It’s so much easier to process information this way than a heavy block of text in a CLI/app.
More so you can fully personalize the output and create rules for different types of output (dashboards, presentations, decks etc)
Andrej Karpathy@karpathy
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc. More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage: 1) raw text (hard/effortful to read) 2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default 3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default ...4,5,6,... n) interactive neural videos/simulations Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status… There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen. TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
English
@karpathy Been doing this for about a month. It’s incredibly better than reading heavy text on CLI. This should be a default for over verbose or lengthy output. It does work incredibly well plus it’s easy to personalize.
English

This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral x.com/zan2434/status…
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
Thariq@trq212
English
Carlos Calva retweetledi

Carlos Calva retweetledi

most agent “memory” is a memo, not consolidation.
The next question the paper opens but doesn’t fully answer: what should the consolidation criterion be?
Frequency? Recency? Both have ceilings.
The version that compounds is outcome-conditioned: keep the writes that downstream task performance retroactively validated. The agent learns which memories were worth keeping, not just what to write.
Different category from an LLM extractor optimizing for fact fidelity.
DAIR.AI@dair_ai
// Contextual Agentic Memory is a Memo, not True Memory // Most agent memory today isn't memory. They are more like memos. A new paper argues that vector stores, RAG buffers, and scratchpads implement lookup, not consolidation. Agents accumulate notes indefinitely without ever turning them into expertise. The framing draws from neuroscience's Complementary Learning Systems theory: biological intelligence pairs fast hippocampal storage with slow neocortical consolidation. Current AI agents only implement the first half which includes fast write, similarity recall, no abstraction step. Why does it matter? The paper proves a generalization ceiling on compositionally novel tasks. As long as memory stays retrieval-only, your agent can't apply abstract rules to inputs that don't already look like something in the store. It also leaves the agent permanently exposed to memory poisoning. If you're building long-running agents and treating "memory" as a vector index, this paper provides a good discussion of what you're actually missing. Paper: arxiv.org/abs/2604.27707 Learn to build effective AI agents in our academy: academy.dair.ai
English
Carlos Calva retweetledi
Anthropic shouldn’t do this and doesn’t have to
Would be great if it stopped
Theo - t3.gg@theo
Fun fact - if you have a recent commit that mentions OpenClaw in a json blob, Claude Code will either refuse your request or bill you extra money. This is an empty repo, I'm just calling Claude Code directly. Insanity.
English
Carlos Calva retweetledi

@justic_hot @tylertracy321 @arankomatsuzaki Would love to learn more about the issues you’ve found open for a DM?
English

@tylertracy321 @arankomatsuzaki that catches what diffs cant, silent log deletion or env setup chains where each step looks fine alone. is the 23% mostly composition attacks, each action individually benign?
English

Redwood Research presents LinuxArena
- 20 live production environments for AI agents
- Frontier models achieve ~23% undetected sabotage vs. trusted monitors
- Useful work ≈ attack surface → sandboxing fails, monitoring is essential

English
@SakanaAILabs @hardmaru One word: FINALLY!
Excited to try it out
English

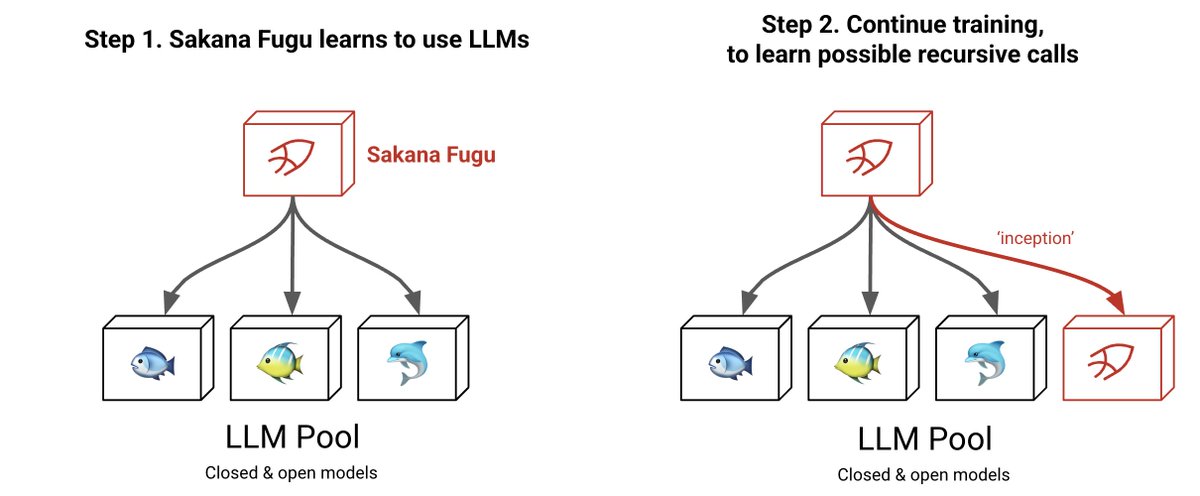
Sakana AIは新しい商用AIプロダクトとして、マルチエージェント・オーケストレーションシステム「Sakana Fugu」のβテストを開始します🐡
ブログ: #Japanese" target="_blank" rel="nofollow noopener">sakana.ai/fugu-beta/#Jap…
複数のフロンティア基盤モデルを動的に協調させ、タスクごとに最適なエージェントの組み合わせと役割分担を自律的に選び出す システムです。SWE-Pro、GPQA-D、ALE-Benchなどで新たなSOTAを達成し、これまで社内の研究者・エンジニアが活用してきました。
OpenAI互換APIとして、既存のワークフローをほとんど変えずに導入いただけます。
🐟 Fugu Mini: レイテンシ重視の高速オーケストレーション
🐡 Fugu Ultra: 深い推論向けのフルモデルプール活用
ベータテスト応募はこちら:forms.gle/BtKkhc2CfLKk1d…
Sakana AI@SakanaAILabs
We’re launching the beta for our new commercial AI product: Sakana Fugu 🐡, a multi-agent orchestration system! Blog: sakana.ai/fugu-beta Fugu hits SOTA on SWE-Pro, GPQA-D, and ALE-Bench, and has been our internal secret weapon. It dynamically coordinates frontier models, autonomously selecting the optimal agent combinations and roles for each task. Available as an OpenAI-compatible API, you can seamlessly integrate Fugu into your existing workflows with minimal changes. 🐟 Fugu Mini: High-speed orchestration optimized for latency 🐡 Fugu Ultra: Full model pool utilization for deep, complex reasoning Apply for the beta test here: forms.gle/BtKkhc2CfLKk1d…
日本語
You’re right.
Everyone is full of shit beyond belief. The “AI folks” you refer to are just the people that hype up everything they’ve barely read the title off and then reshare with “URGENT” “MUST READ” or whatever stupid label is best bating that week.
Then everyone backpedals when they start to see the actual AI folks say it’s just bullshit.
Clearest late example: @karpathy wiki
Great idea, sounds simple, compelling and powerful
All the hype “AI folks” went at it like bees to hon… flies to a shit pile, then regurgitate it.
The the real AI folks start testing it and realize a) it is indeed great and very useful, b) hard to maintain not the promised solves everything idea everyone is peddling and c) not everyone has the GPUs Karpathy has access to (more about his auto research report than the wiki)
The key learning: prune your account from who you follow. There’s still good AI folks to get true signal.
A few hype AI folks are always needed to see what’s the “latest and greatest” BUT this should be eclipsed by having a counterweight with people who actually build, implement and are imparcial.
Much like anything in the age of AI: curation is king in this situation.
English

Talking to smarter folks than me, I'm convinced many of the AI folks in my timeline are full of shit.
Nobody is "running 20 agents over night" and building stuff for actual users. Maybe some are building internal tools or disposable software. Maybe.
But building software people like using? That doesn't get hacked on day one or blow up after the 3rd user? Nope.
I don't even understand what that's supposed to look like. Do you work out a 57 pages document that perfectly describes what you want to build and then summon 14 agents and have them run wild for 6 hours? And what comes out on the other end isn't a broken pile of shit?
Nope. Not buying it.
PS: it may also be that I have an IQ of 82 and can't figure it out.
English
Carlos Calva retweetledi

🧠Introducing OmniMouse: One of the largest datasets in neuroscience ever assembled along with a systematic study of scaling properties of brain models
Co-led with🤩@pollytur1 @alexrgil14
3M neurons, >150B tokens from @AToliasLab @stanford, @alxecker @sinzlab @uniGoettingen
🧵
English
Carlos Calva retweetledi

Every big model lab is racing to ship "agent memory" right now.
Anthropic. OpenAI. Google.
None of it is built to make your agent smarter.
All of it is built to keep your agent stuck inside their stack. 🚫 Don't fall for it! 👇
English
English
@DougAillm @claudeai append is clean, rank is still the hard part. 6mo-old 'how we handle auth' reads correct until you remember the refactor. recency alone loses if the stale one has more references
English