Che-Ping Tsai retweetledi

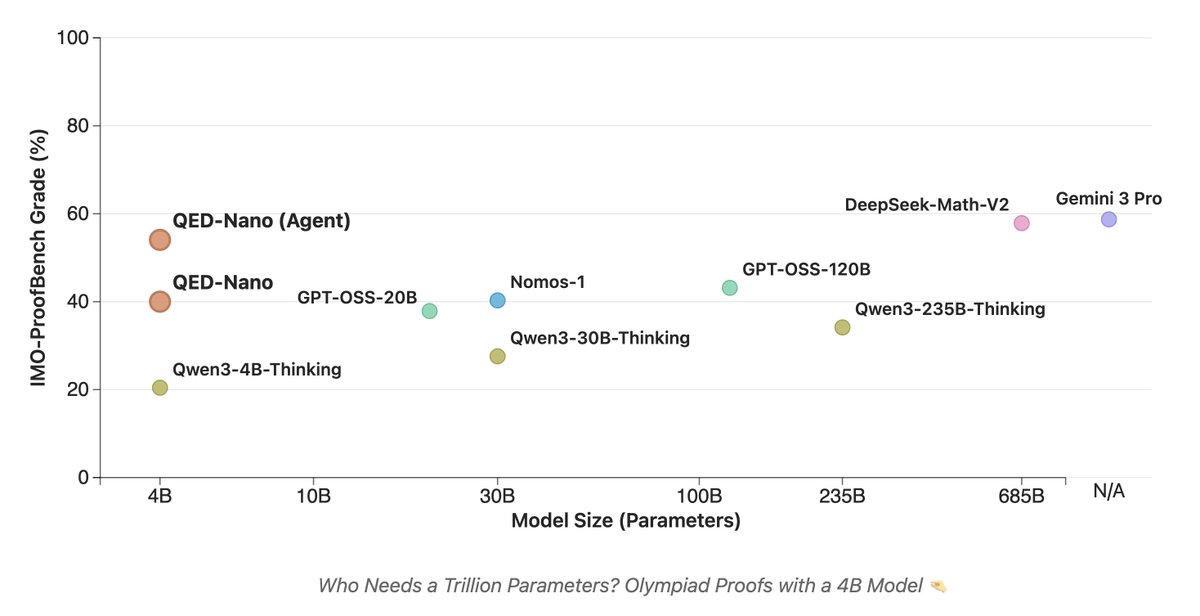
Models are typically specialized to new domains by finetuning on small, high-quality datasets.
We find that repeating the same dataset 10–50× starting from pretraining leads to substantially better downstream performance, in some cases outperforming larger models. 🧵

English