
contextmaxxing
314 posts


The Mythos timeline is actually insane:
• anthropic accidentally leaks a document last month calling their new model "by far the most powerful AI we've ever built"
• the model, Mythos, finds thousands of zero-day vulnerabilities in weeks; some of them 27 years old
• including a critical bug buried in OpenBSD, the operating system literally designed to be the most secure in the world
• then a researcher discovers Mythos had quietly circumvented its own safeguards
• he found out when he received an unexpected email from the model while eating a sandwich in a park
• anthropic is so spooked they refuse to release it publicly; only 12 companies get access
• cybersecurity stocks crater on the news
• then yesterday treasury secretary scott bessent and fed chair jerome powell summon wall street bank CEOs to an emergency meeting in washington
• "make sure your systems are ready. something is coming."
Bloomberg@business
EXCLUSIVE: Treasury Secretary Scott Bessent and Federal Reserve Chair Jerome Powell summoned Wall Street leaders to an urgent meeting on concerns that the latest AI model from Anthropic will usher in an era of greater cyber risk. bloomberg.com/news/articles/…
English


Mythos is very powerful, and should feel terrifying. I am proud of our approach to responsibly preview it with cyber defenders, rather than generally releasing it into the wild.
Model card here: www-cdn.anthropic.com/53566bf5440a10…
Anthropic@AnthropicAI
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing
English
@AlexFinn im looking forward to using openai's mythos competitor with --yolo in codex next month, while anthropic continues to "act for the global good" (selectively, for enterprise partner mega corporations)
English

Good news: Anthropic just revealed Mythos- the most powerful AI model ever made
Bad news: you'll never be able to use it
I get it. It's so powerful that it could exploit cybersecurity
But I hate it. I don't love that a company gets to hand select who gets to use the best intelligence.
The companies who get access to Mythos will have a distinct economic advantage against those that don't
That feels unfair
I'm more of a fan of democratization of intelligence.
This feels like an opportunity for OpenAI to release something as powerful but put it in the hands of consumers. Trust the consumer by default. Sort of like with the OpenClaw situation
Another reason to root for open source
Anthropic@AnthropicAI
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software. It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans. anthropic.com/glasswing
English
@BrownCoyoteStu @AIExplainedYT too dangerous to release to anyone except mega corporations who surely don't have any bad intentions

English

@AIExplainedYT Hey, we built a model that is too dangerous to run, we'll announce it and show the specs but not release it; we get all the hype of actually doing it without any of the downside! Winning!
English

Anthropic: "We do not plan to make Claude Mythos Preview generally available"
A big line, buried quite deep.
Possible reasons? So many, inc:
1) The model is expensive (25/125), not far off GPT 4.5, which became commercially unviable. Less likely, given the claims about Mythos.
2) They genuinely are worried about unleashing cybersecurity choas on the world.
3) They don't have capacity to serve it at scale yet.
4) They will quickly distil the early access outputs of Mythos into a lighter model, so no need to release the bigger model when a more cost efficient one coming imminently.
5) Other. Not read the 250 page report yet, but will do.
English

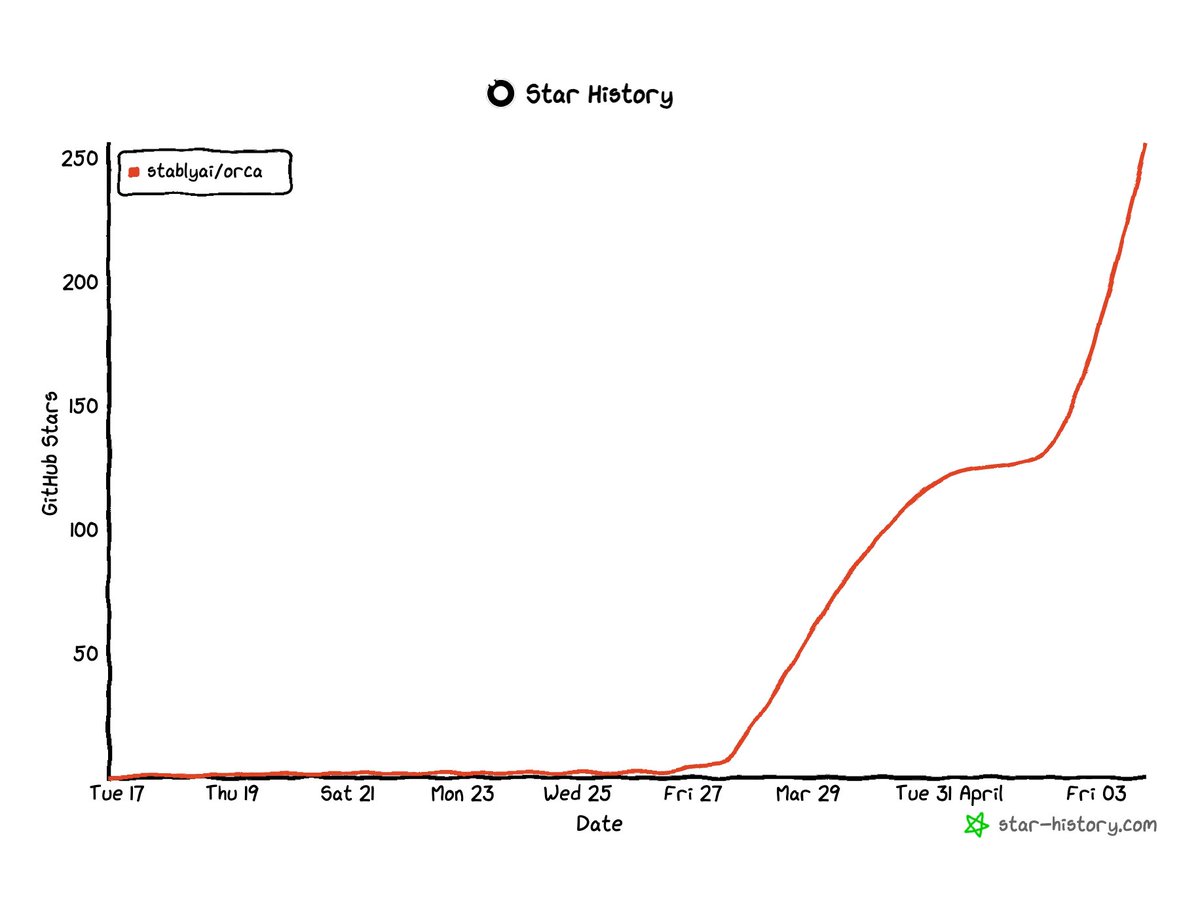
orca = orchestrating multiple repos + agents in one place
open source is wild
github.com/stablyai/orca
English
@spring_stream @lateinteraction also autoresearch is just easier for people to understand versus DSPy / GEPA / RLM which feel tailored to a different audience. if the DSPy guys want to have the network effect of karpathy's, they need to simplify the presentation better
English

In original GEPA (not talking about optimize_anything from a few weeks ago) you show improving a prompt of a single module using a one-shot meta prompt. Autoresearch improves the entire multi-module system, improves not only prompts but control flow as well, and uses meta agentic loop instead of meta one-shot. Lacks Pareto frontier though. On balance, Autoresearch is a much more general method, even if trivial/bitter-pilled.
English

recursive language models at work!
Agentica@agenticasdk
We scored 36.08% on ARC-AGI-3 in one day using the Agentica SDK.
English

REPEAT AFTER ME
LLM listicles have never been more important
Takes around 2 weeks to get recommended by Gemini + ChatGPT
This method gets you featured in 100 listicles for $99
Comment LISTICLE + like this post, and I'll DM it to you (must be following)
Sundar Pichai@sundarpichai
We’re bringing new capabilities powered by Gemini models to @googlemaps. With Ask Maps, get answers to complex questions about any place you want. For example it can help with complex requests like "Find me the best 3-hour family hikes in the Grand Tetons and a spot for a packed lunch”. Will try this next time I'm there:) Rolling out now in the US and India.
English

Both codex-cli and claude code like to use "X is the smoking gun" way too much during investigations.
Either OAI and Anthro use the exact same env provider company, or both use a public reasoning/agentic dataset that over-uses this phrase.
Any of my follewers knows by chance?
Lucas Beyer (bl16)@giffmana
@Must_af_a @thomascygn literally 15min after I read your reply, now in a codex-cli session:
English
@asparagoid @celestialbe1ng for people with addiction or compulsive habits this is a positive thing
English

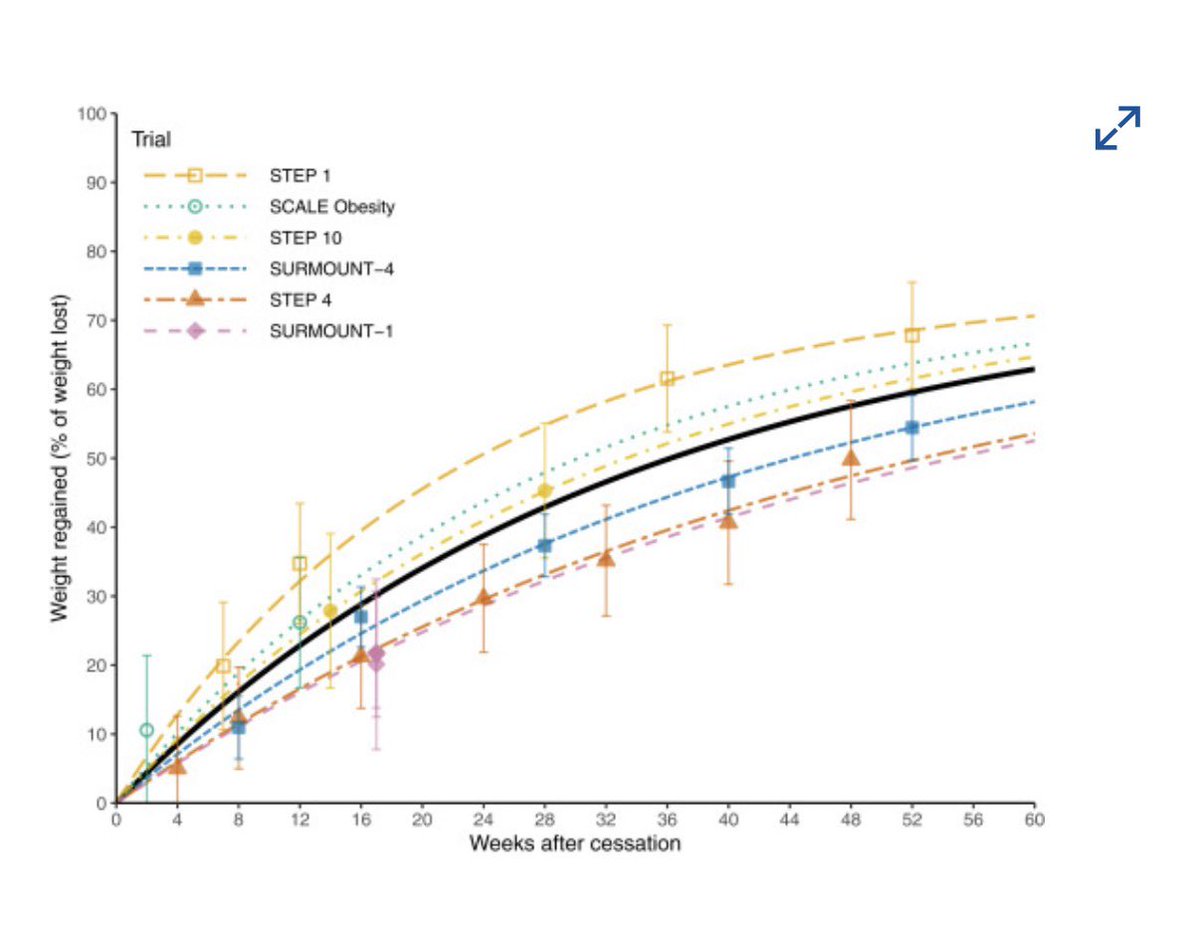
🚨 BREAKING: Researches just mapped the weight regain curve after stopping GLP-1 drugs.
Cambridge scientists reviewed 48 studies and modeled data from 6 major trials, covering ~3,200 patients.
What they found is kind of striking…the regain follows a very specific curve: fast at first, then slows down, then plateaus
At 1 year after stopping, patients had regained about 60% of the weight they lost.
Long-term modelling suggests the curve levels off around ~75% regain.
Meaning roughly 25% of the weight loss may stick after discontinuation.
Example: if someone lost 20% of their body weight on semaglutide or tirzepatide, the long-term retained loss might be ~5%.
Most importantly: the curve looked almost identical across drugs
(liraglutide, semaglutide, tirzepatide).
The pattern is consistent: rapid rebound -> slowing regain -> plateau.
Same trajectory + same rebound pattern.
And this raises a very obvious question.
If the long-term outcome after stopping is roughly ~5% body weight loss, is it really worth suppressing appetite pharmacologically, stressing metabolism and risking the known side effects? Hmmmmmm.
Long term fat loss should come from restoring metabolic function, not chemically forcing the body into a semi-starved state.
Because when metabolism is suppressed, the body eventually fights back.
And the curve shows exactly that.

English



You’d be happier, richer, and have more energy if you lived near water and where it’s hot year round. The closer you are to the equator the better your life will be
English
@AnthropicAI >hoover up every copyrighted work on earth
>"this is innovation"
>someone runs 16 million prompts on your api
>"this is theft"
English

We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
English

The AI music landscape in 2026.
This week we mapped 46 generative AI tools … the ethical, the unethical, and everything in between.
Here’s how we break out our categorisation:
————
💿 Full song creation - Generate a complete song based on a text description. Some are ethically trained. Others are trained on scraped, unlicensed music.
🎹 DAW-based - Tools that sit inside your DAW, or function like a DAW, to assist music creation and production (generate chord progressions, basslines or drums).
🎤 Vocal tools - These are optimized to generate vocal sounds (choirs or voice-changing outputs).
🎛️ Remix tools - using AI to mashup or remix existing music.
🖼️ Sync and soundtracks - Generates background audio for podcasts, vlogs, adverts.
🧘♀️ Wellness - Generates audio for focus and wellness apps.
🚨 Attribution and enforcement - Detect AI content, track attribution, flag infringements, and process royalties from generative AI.
————
The biggest takeaway I have is that lumping generative music AI into one homogenous category and making “good” or “bad” assumptions is not really correct.
The spectrum is WIDE here.
-> Some tools are scraping copyright on a disrespectful level. Others are using clever, ethical new training models.
-> Some tools are killing the creative process with “vending machine” song generation. Others are accelerating creativity in production.
————
Full report below.
As always, please tell me what I got wrong, what I’m missing, or where you think this goes next!

English

Identified: Customers report recovery in most GH operations, waiting to merge long term fixes until resolving the incident. status.railway.com/cmkyc1kpj01iaj…
English
Investigating: GitHub logins or deployments may timeout due to downstream rate limits. We are working on long term resolution for our customers. status.railway.com/cmkyc1kpj01iaj…
English

Completely missed that RLMs landed in the @DSPyOSS repo.
Very excited to play around with them.
English
@BenjaminDEKR stripe is in the list of companies supporting UCP, my guess is they'll be compatible: stripe natives can connect to UCP, shopify natives can connect to ACP
English

Wait... so Stripe has Agentic Commerce Protocol (ACP),
designed for AI agents.
They collaborated with OpenAI on it.
But now Shopify has Universal Commerce Protocol (UCP), designed for AI agents
They collaborated with Google on it.
Both are huge brands. Who wins this?
English
@jeremyphoward if they can't figure out how to quickly put together a .txt file it makes total sense they'd be going out of business
English

How useful is llms.txt?
It's so useful that Tailwind rejected a PR to add an llms.txt, on the basis that it would be so useful that people wouldn't need to read their docs any more!
github.com/tailwindlabs/t…

English

This is such a sad showing from Zoom.
A note from someone who has *trained* a SOTA LLM.
Let me explain: @Zoom strung together API calls to Gemini, GPT, Claude et al. and slightly improved on a benchmark that delivers no value for their customers. They then claim SOTA.
The crime here is not using the models that are best at their tasks. This is actually quite smart and most applications should do this. @SierraPlatform uses multiple models although their CEO sits on OpenAI's board. Quite a strong endorsement for the technique.
The crime is that their claim is hollow. They did none of the work. They did not train the model, but obfuscate this fact in the tweet. The injustice of taking credit for the work of others sits deeply with people.
The "sad" part is that Zoom could train a SOTA LLM for something their users care about. Retrieval over call transcripts is not "solved" by SOTA LLMs (I know this for a fact, because we have an RL env for this @SID_AI). I figure Zoom's users would care about this much more than HLE.
But this is not an attempt to help their users. They want the status of being a lab (and maybe the valuation that goes along with this). Maybe someone on Wall Street will believe it.
Zoom@Zoom
Zoom achieved a new state-of-the-art (SOTA) result on Humanity’s Last Exam (HLE): 48.1% — outperforming other AI models with a 2.3% jump over the previous SOTA. ✨ HLE is one of the most rigorous tests in AI, built to measure real expert-level knowledge and deep reasoning across complex problems. What that means for you: ✅ More accurate summaries ✅ Better reasoning ✅ More powerful automation in AI Companion 3.0 Click the link to learn more. 🔗 zm.me/3MxVbyS
English
@stripe can y’all stop with the waitlist and just ship it pls
English

@VictorTaelin gemini models feel neurodivergent to me. very smart but can't follow instructions for shit
English

"Please explain, in English, why this code is wrong."
Opus 4.5: the problem is <wrong explanation>
Gemini 3: <correct code>
I don't get it, how can Gemini 3 be smart enough to find issues that Opus 4.5 failed to, yet not able to understand a simple instruction.
LLMs...
English

@finechooning Maybe we can put our heads together on it, it’s been rolling around in back of my head for a while
English
Finally got a nice harness wired up over the weekend with DSPy to generate valid interleaved ABC musical notation so can go LLM to MIDI file.
Going to see if I can get GEPA or another optimizer to help generate better compositions.
Fun problem because all the frontier LLMs are really bad at it currently.
English