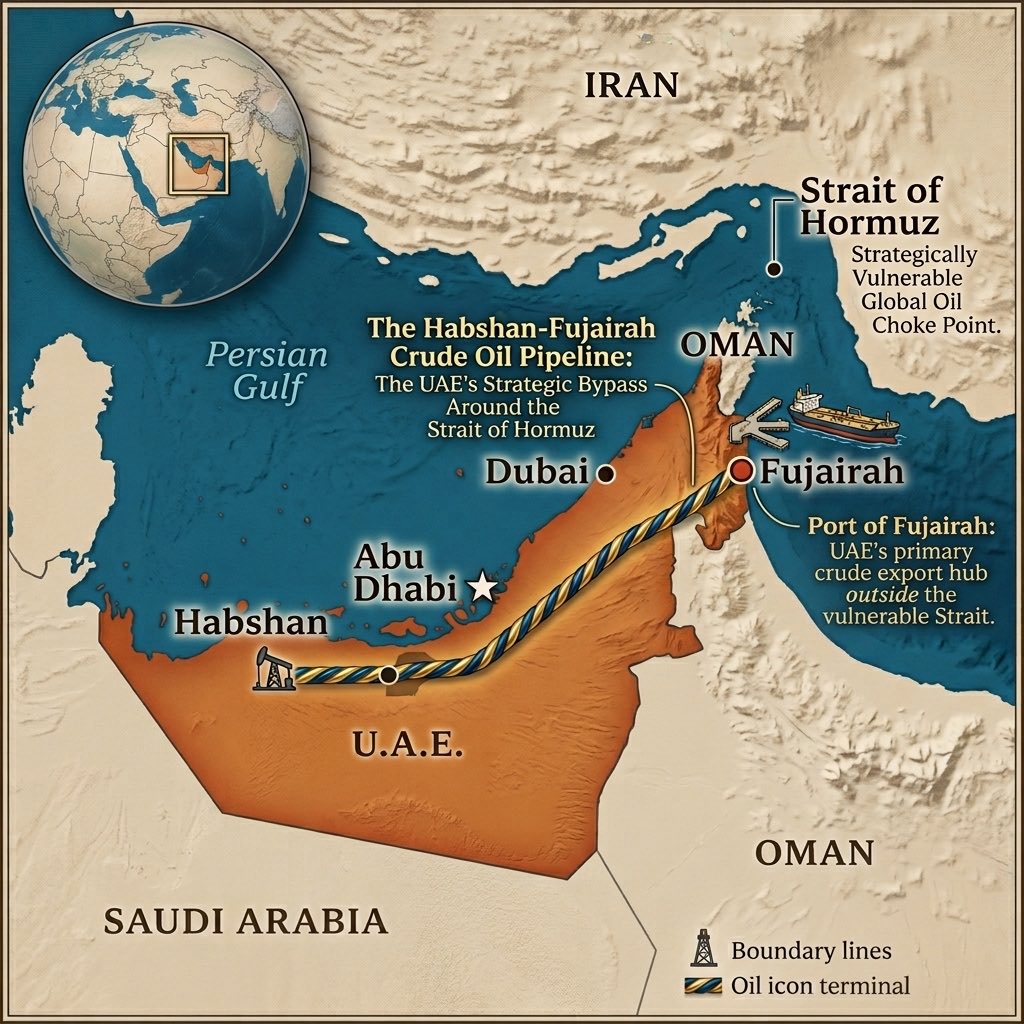
crypto_1984 retweetledi

🚨BREAKING: Anthropic just published a study mapping exactly which jobs its own AI is replacing right now.
The workers most at risk are not who anyone expected. They are older. They are more educated. They earn 47% more than average. And they are nearly four times more likely to hold a graduate degree than the workers AI is not touching.
The argument is straightforward. Anthropic built a new metric called "observed exposure." Not what AI could theoretically do. What it is actually doing right now in professional settings, measured against millions of real Claude conversations from enterprise users.
For computer and math workers, AI is theoretically capable of handling 94% of their tasks. It is currently handling 33% of them. For office and administrative roles, theoretical capability is 90%. Current observed usage is 40%. The gap between what AI can do and what it is already doing is enormous. The researchers are explicit about what comes next. As capabilities improve and adoption deepens, the red area grows to fill the blue.
The demographic finding is what makes the paper uncomfortable. The most AI-exposed workers earn 47% more on average than the least exposed group. They are more likely to be female. They are more likely to be college educated. This is not a story about warehouse workers or truck drivers. It is a story about lawyers, financial analysts, market researchers, and software developers. The exact group whose education was supposed to insulate them.
Computer programmers showed the highest observed AI exposure at 74.5%. Customer service representatives at 70.1%. Data entry keyers at 67.1%. Medical record specialists at 66.7%. Market research analysts and marketing specialists at 64.8%. These are not predictions. These are measurements of work that is already happening on AI platforms right now.
Then there is the pipeline finding nobody is talking about loudly enough.
Anthropic's researchers found a 14% decline in the job-finding rate for workers aged 22 to 25 in highly exposed occupations since ChatGPT launched. No comparable effect for workers over 25. Entry-level roles were never just jobs. They were the training ground where junior analysts became senior analysts, where junior lawyers learned how arguments hold together. If that layer disappears, nobody has answered the question of where the next generation of senior professionals comes from.
The detail buried in the paper that most coverage missed: 30% of American workers have zero AI exposure at all. Cooks. Mechanics. Bartenders. Dishwashers. The technology reshaping professional careers is completely irrelevant to roughly a third of the workforce. The divide is no longer between high skill and low skill. It is between presence and absence.
The company publishing this study is the same company selling the AI doing the replacing. Anthropic had every commercial incentive to soften these findings. They published them anyway.
If you spent four years and $200,000 on a degree to land a white collar career, the company that builds Claude just confirmed your job is more exposed than the bartender pouring drinks at your graduation party.
Source: Anthropic, "Labor market impacts of AI: A new measure and early evidence"
PDF: anthropic.com/research/labor…

English