Yupeng Cao retweetledi
Yupeng Cao
871 posts

Yupeng Cao
@cyp0630
Multimodal, NLP ; Crypto
Hoboken, NJ Katılım Ekim 2019
184 Takip Edilen13 Takipçiler

Yupeng Cao retweetledi

Yupeng Cao retweetledi

我觉得大家时刻可以记住一个点,那就是对于川普来说:他的商人属性大于他的总统属性!
这句话是我昨天在我的粉丝群里面说过了一句话!
这届行情就是:跟着总统买就完事儿了!
🤣🤣🤣
如下是一些可供寻找的产品:
芯片(Chips)
$INTC Intel(英特尔)
$NVDA NVIDIA(英伟达)
$AMD AMD(超微)
$TSM TSMC(台积电)
AI基础设施(AI Infrastructure)
$DELL Dell(戴尔)
$VRT Vertiv(维谛技术,数据中心散热)
$NBIS Nebius(前Yandex,AI算力)
$CRWV Coreweave(AI云算力新贵)
$IREN IREN(比特币挖矿转AI算力)
$HUT Hut 8(挖矿+AI算力)
稀土(Rare Earths)
$USAR USA Rare Earth(美国稀土)
$CRML Critical Metals(关键金属)
$TMC The Metals Company(深海采矿)
关键矿产(Critical Minerals)
$TMQ Trilogy Metals(阿拉斯加矿)
$UAMY United States Antimony(美国锑业)
$MP MP Materials(美国最大稀土公司)
$LAC Lithium Americas(锂矿)
量子计算(Quantum)
$IONQ IonQ(离子阱量子)
$QBTS D-Wave Quantum(量子退火)
$RGTI Rigetti(超导量子)
能源(Energy)
$BE Bloom Energy(固体氧化物燃料电池)
$GEV GE Vernova(GE能源分拆)
$FCEL FuelCell Energy(燃料电池)
$PLUG Plug Power(绿氢+燃料电池)
$VICR Vicor(电源管理模块)
内存/存储(Memory)
$MU Micron(美光)
$STX Seagate(希捷硬盘)
$WDC Western Digital(西部数据)
$MRAM Everspin(磁性内存)
太空(Space)
$RKLB Rocket Lab(火箭实验室)
$ASTS AST SpaceMobile(太空手机直连)
$PL Planet Labs(地球观测卫星)
$FLY Firefly Aerospace(萤火虫航天)
$GILT Gilat(卫星通信)
无人机(Drones)
$AVEX Aevex(军用无人机)
$ONDS Ondas(工业无人机+铁路)
$UMAC Unusual Machines(无人机零部件)
核能(Nuclear)
$XE X-energy(先进小型核反应堆)
$LEU Centrus Energy(铀浓缩)
$CCJ Cameco(全球大铀矿商)
$OKLO Oklo(小型模块化核反应堆)
$UUUU Energy Fuels(铀+稀土)
自动驾驶 & 机器人(AVs & Robotics)
$TSLA Tesla(特斯拉)
$AMZN Amazon(亚马逊)
电池(Batteries)
$TE T1 Energy(电池相关)
$ELVA Electrovaya(锂离子电池)
$FLNC Fluence Energy(储能系统)
这波全是“美国优先 + 硬科技”主题,总统点名哪个领域,就买哪个赛道里的公司。
简单粗暴,跟着政策走就行!

Lin@Speculator_io
This is the kind of market where you simply buy what the president tells you to: Chips $INTC Intel $NVDA NVIDIA $AMD AMD $TSM TSMC AI Infrastructure $DELL Dell $VRT Vertiv $NBIS Nebius $CRWV Coreweave $IREN IREN $HUT Hut 8 Rare Earths $USAR USA Rare Earth $CRML Critical Metals $TMC The Metals Company Critical Minerals $TMQ Trilogy Metals $UAMY United States Antimony $MP MP Materials $LAC Lithium Americas Quantum $IONQ IonQ $QBTS D-Wave Quantum $RGTI Rigetti Energy $BE Bloom Energy $GEV GE Vernova $FCEL Fuelcell $PLUG PlugPower $VICR Vicor Memory $SNDK Sandisk $MU Micron $STX Seagate $WDC Western Digital $P Everpure $MRAM Everspin Space $RKLB Rocket Lab $ASTS AST SpaceMobile $PL Planet Labs $FLY Firefly Aerospace $GILT Gilat Drones $AVEX Aevex $ONDS Ondas $UMAC Unusual Machines Nuclear $XE X-energy $LEU Centrus Energy $CCJ Cameco $OKLO Oklo $UUUU Energy Fuels AVs & Robotics $TSLA Tesla $AMZN Amazon Batteries $TE T1 Energy $ELVA Electrovaya $FLNC Fluence Energy Never miss the leading stocks again: fullstackinvestor.co/portfolio
中文
Yupeng Cao retweetledi

太炸裂了!居然有人搞出一个能直接读懂K线交易的AI,性能直接起飞!
它叫 Kronos —— 全球首个专为金融市场量身打造的开源基础大模型!
用45家交易所120亿条真实K线数据从零训练,不是拿通用AI硬改的。
它能:
价格预测 + 波动率预判
全资产零样本直接用(币安、纽交所、纳斯达克全覆盖)
笔记本就能跑(4个版本:400万到4.99亿参数)
实测狠到离谱:
比主流时序模型准93%,比顶尖非预训练模型高87%,拿来就用不用微调!
现在BTC实时预测每小时更新,免费公开看效果。
对冲基金花几百万定制?
彭博终端一年2.4万美金?
Kronos:完全免费,几行Python直接调用,MIT协议100%开源!
清华团队出品,已入围2026 AAAI顶会,GitHub 2.4万星狂飙中。
这波真要改变量化圈了!
GitHub链接速去白嫖,以防错过这波AI交易红利
github.com/shiyu-coder/Kr…
(配K线预测对比图 + 直播BTC演示截图 = 转发爆炸)

Huan@Huanusa
中文
Yupeng Cao retweetledi


Yupeng Cao retweetledi

Yupeng Cao retweetledi

Anthropic 真的惊为天人
直接把金融服务行业的 AI 工作流模板全开源了
投资银行 / 股票研究 / 私募 / 财富管理 / 基金管理 / KYC 风控
七大业务线的参考 agent / 技能包 / 数据连接器 全部公开
这超出了 demo 的范畴,是把「金融行业 AI 落地」的完整 SOP 摆出来 / 让全行业照抄
· 打开仓库 你会看到这些东西
10 个开箱即用的端到端 agent
- Pitch Agent / 自动做 pitch deck(comps + 先例 + LBO → 出品牌排版的 deck)
- Meeting Prep Agent / 客户会前自动出 briefing pack
Market Researcher / 行业或主题 → 行业概览 + 竞争格局 + peer comps + 标的清单
- Earnings Reviewer / 财报会议 + filings → 模型更新 → 研报草稿
- Model Builder / DCF / LBO / 三表 / comps / 直接在 Excel 里建模
- Valuation Reviewer / 私募估值 + LP 报告
- GL Reconciler / 总账核对 + 找差异 + 路由审批
- Month-End Closer / 月末关账 / accruals / 滚动 / 偏差解读
- Statement Auditor / LP statement 审计
- KYC Screener / KYC 文档解析 + 规则引擎跑 + 标记缺口
每个 agent 都是 self-contained 的,带自己用到的全部 skill,clone 下来直接装
· 7 个垂直行业插件
- financial-analysis(核心):comps / DCF / LBO / 三表 / deck QC / Excel 审计
- investment-banking:CIM / teaser / 流程信 / 买方名单 / 并购模型 / 项目跟踪
- equity-research:财报笔记 / 首次覆盖 / 模型更新 / 投资逻辑跟踪
- private-equity:寻源 / 筛选 / 尽调 / IC memo / 投后监控
- wealth-management:客户复盘 / 财务规划 / 调仓 / 报告 / 税损收割
- fund-admin:GL 核对 / 差异追踪 / NAV 校验
- operations:KYC + 规则引擎
直接用 / 想改也行 / 全是 markdown + json / 没有 build 步骤
· 11 家金融数据商的 MCP 连接器
Daloopa / Morningstar / S&P Global / FactSet / Moody's
MT Newswires / Aiera / LSEG / PitchBook / Chronograph / Egnyte
这一行单独值得讲
意味着 Anthropic 已经跟全球最重要的金融数据基础设施都谈完了,你接进 Claude / 这些数据全是开箱即用的,没有这些连接器 / 你自己接每一家的 API / 光人天就要好几个月
LSEG 和 S&P Global 还各自做了 partner-built 的高级插件
一个跑债券相对价值 / 利率曲线 / FX carry / 期权波动率 / 宏观利率监控
一个跑 tear sheet / 财报预览 / 融资 digest
· 部署方式两种,一个仓库
方式一:Claude Cowork 插件
装在分析师电脑上 / 个人工作流
方式二:Claude Managed Agents API
跑在公司自己的工作流引擎后面 / 整个公司用
同一份 system prompt / 同一份 skill / 你选在哪儿跑
还附带一个 Microsoft 365 安装工具,让公司 IT admin 把 Claude 部署进 Excel / PowerPoint / Word / Outlook
而且可以走你公司自己的云(Vertex AI / Bedrock / 内部 LLM gateway),不强制走 Anthropic API
· 金融是企业 AI 落地最大也最难啃的市场,合规要求高 / 数据敏感 / 流程复杂
Anthropic 这一手
直接把整个行业的 AI 落地 SOP 写明白了
谁照这套搭 / 谁就在 Claude 的轨道上长
谁不照这套搭 / 谁要从零开始踩半年坑
最值得对比的是 OpenAI
OpenAI 上周刚上线广告平台
Anthropic 这周直接开源金融行业全套 agent
两家公司的路线分化在这种地方又看得清清楚楚
OpenAI = 大众消费 + 广告
Anthropic = 企业场景 + 开源行业模板
链接 github.com/anthropics/fin…

中文
Yupeng Cao retweetledi

复刻下一个存储奇迹?光模块来了!
“铜线已经满足不了需求,下一代AI基建必须要用光纤”
这是英伟达 CEO 黄仁勋昨天刚说的话
我总结了相关的美股👇
Corning:NVIDIA的直接合作伙伴,预计投资32亿美元
Lumentum:专注激光和光电元件
Coherent:专注光电转换和光子模块
这三家均是光纤赛道,并且与英伟达有直接关联!
中文
Yupeng Cao retweetledi

去年我认为美国长达十年的国运,现在我认为15-20年:
人工智能产业革命,正开启长达15年的超级投资周期,而截至目前,这一史诗级行情仅仅走过3年征程,远超移动互联网、云计算时代的产业体量与财富机遇,注定成为一代人难再遇的核心投资风口,将彻底重构全球产业格局与经济生态。
站在资本视角来看,全球科技巨头早已吹响全力押注AI的号角,微软、谷歌、亚马逊、Meta四大行业龙头,在AI领域的投入均突破千亿美金级别。数据更能印证这场资本狂潮的力度:2026年全球头部科技企业AI相关资本开支将飙升至7250亿美元,相较去年实现近乎翻倍的增长,海量资本涌入,为AI全周期发展筑牢根基,也让这15年的产业变革拥有了实打实的资金支撑。
想要抓住这波AI红利,绝非盲目跟风追涨,核心在于精准把握周期轮动节奏。普通散户还在扎堆涌入已过风口的初期赛道,而具备前瞻视野的主流大资金,早已悄然布局下一个核心爆发阶段。结合产业发展规律与资本动向,我将这轮AI超级周期划分为四大递进阶段,清晰标注当前所处节点,挖掘各阶段高性价比投资标的与核心赛道。
第一阶段:算力基建爆发期(2023-2025)——行情收官,高位勿入
这一阶段是AI产业的底层搭建初期,核心围绕硬件基础设施展开,也是市场最先炒作的赛道,如今这一轮主升行情已彻底走完。
作为AI算力核心的半导体板块,在这一阶段迎来极致行情:AMD在2025年股价涨幅达到78%,英伟达同步上涨39%,英特尔凭借超预期的一季度财报,直接推动费城半导体指数首次突破10000点大关,存储芯片、光模块、光电材料等上下游硬件企业,均迎来业绩与股价的双重爆发。
但需要清醒认知的是,尽管芯片赛道会贯穿整个AI周期,但其第一阶段的上涨红利已完全兑现。当前底层算力基建布局基本完成,行业虽仍保持增长态势,但股价早已提前透支未来利好,此时入场不仅性价比极低,更要面临高位回调的大幅风险。
核心关注标的:英伟达、AMD、ARM、英特尔、博通、美光、康宁
覆盖核心赛道:半导体芯片、存储内存、光电/光模块
第二阶段:产业配套完善期(2025-2027)——建设高峰,机遇尚存
AI算力基建落地后,产业进入配套设施建设的高峰期,也是当前大部分后知后觉的投资者刚刚关注到的阶段。这一阶段围绕数据中心运营、能源供给、散热方案、网络传输等配套赛道展开,成为承接上一阶段行情的核心主线。
从市场表现来看,光纤领域龙头康宁,凭借AI数据中心光纤需求爆发,年内股价涨幅已达74%;能源领域,CEG完成对Calpine的收购后,跻身美国最大民营电力企业,总装机量达到55GW,GEV股价一年内暴涨超2倍;为AI芯片提供专属散热方案的VRT,也凭借技术配套优势收获可观涨幅。
目前这一板块仍有上涨空间,但已被市场认可的优质标的股价已处于高位,而小型模块化核电成为这一阶段被严重低估的黑马赛道,多家企业聚焦为数据中心提供直供电力,有望迎来价值重估。
核心关注标的:CEG、GEV、VRT、VST、TLN、ANET、康宁、MOD、EQIX、OKLO、SMR、BWXT、NNE
覆盖核心赛道:电力电网、服务器散热、网络设备、小型模块化核电
第三阶段:实体产业融合期(2026-2028)——黄金窗口期,性价比拉满
当下正是布局AI第三阶段的最佳时机,这一阶段的核心逻辑是AI技术走出数据中心,与实体产业深度融合,实现从技术研发到落地应用的关键跨越,也是风险可控、收益爆发力最强的投资阶段。
相较于前两个阶段聚焦产业基建,第三阶段的AI开始真正赋能实体经济,相关赛道已涌现出明确的产业落地信号:KTOS研发的女武神无人机成功获得美国海军陆战队采购订单;特斯拉全力推进人形机器人Optimus量产,投入2500亿美元改造弗里蒙特工厂,计划2026年下半年正式投产;航天领域火箭实验室营收创下6.02亿美元新高,在手订单规模达18.5亿美元,LUNR年内股价上涨47%,手握9.43亿美元合作订单,产业落地与业绩增长双轮驱动。
这一阶段的机遇尚未被大众投资者广泛认知,提前布局就能抢占行情先手,分享AI产业化落地的核心红利。
核心关注标的:特斯拉、火箭实验室、LUNR、KTOS、AVAV、PATH、直觉外科、MP、FCX、ALB、ASTS
覆盖核心赛道:机器人与自动驾驶、航天军工无人机、稀土资源
第四阶段:生态格局定型期(2028年以后)——长期持有,锁定终局红利
2028年之后,AI产业将进入终局定型阶段,行业格局趋于稳定,核心竞争焦点转向软件生态与通用人工智能(AGI)。
这一阶段的核心逻辑是“得生态者得天下”,全球科技巨头纷纷加码软件平台布局,抢占AI生态话语权:谷歌云在手订单突破4600亿美元,微软、谷歌、亚马逊、Meta分别拿出1900亿、1900亿、2000亿、1450亿美元投入生态建设,全力攻坚通用人工智能。同时,量子计算作为前沿科技赛道,目前仍处于发展初期,IONQ、D Wave等企业已提前布局,抢占未来技术高地。
核心关注标的:微软、谷歌、亚马逊、Meta、甲骨文、IONQ
覆盖核心赛道:AI软件生态、AGI底层基建、量子计算
中文
Yupeng Cao retweetledi

Yupeng Cao retweetledi

Skill1
Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
paper: huggingface.co/papers/2605.06…

English
Yupeng Cao retweetledi

Yupeng Cao retweetledi
SkillOS
Learning Skill Curation for Self-Evolving Agents
paper: huggingface.co/papers/2605.06…

English
Yupeng Cao retweetledi

🎯 未来 5 年值得买入并长线持有的 10 只顶级美股
如果你在寻找跨越周期的核心资产,这 10 个名字构成了未来五年的 AI 基础设施 + 能源底座。
🏗️ 算力与芯片:硬科技的护城河
$TSM (台积电):全球 AI 的物理起点。没有 TSM,就没有算力。
$NVDA (英伟达):算力霸权,AI 时代的“通用电气”。
$AVGO (博通):网络连接与定制芯片的王者,算力集群的粘合剂。
$AMD (超威半导体):唯一的挑战者,在数据中心和 PC 端持续扩张。
$MU (美光):HBM 内存的爆发,AI 需要更快的读写速度。
🌐 云端与生态:利润的终极收割机
$MSFT (微软):AI 生产力的终极整合者,Azure 云的增长逻辑无懈可击。
$GOOG (谷歌):搜索长城 + Gemini 进化,原生 AI 流量的护城河。
$AMZN (亚马逊):AWS 依然是全球最稳的利润机器,电商效率持续进化。
$META (美达):开源 AI (Llama) 的带头人,社交广告的转化率正在被 AI 重塑。
⚡ 能源基石:算力的尽头
$GEV (GE Vernova):最重要的一环。AI 算力的尽头是电力,电力的核心是电网与能源管理。
💡 核心逻辑:
1. AI 泡沫还是革命?*如果是泡沫,卖掉;如果是革命,这 10 只股票就是 21 世纪的铁路和石油。
2. 软硬结合:从底层的 2nm 晶圆到顶层的 AI 应用,形成闭环。
3. 能源博弈:当所有人都在抢芯片时,聪明人已经在布局 $GEV 等能源基建。
长线持有,让时间成为你的杠杆。
#美股 #AI #投资 #Nvidia #Tesla #Wealth #Alpha
你认为未来五年,还有哪只股票能挤进这个名单?

中文
Yupeng Cao retweetledi

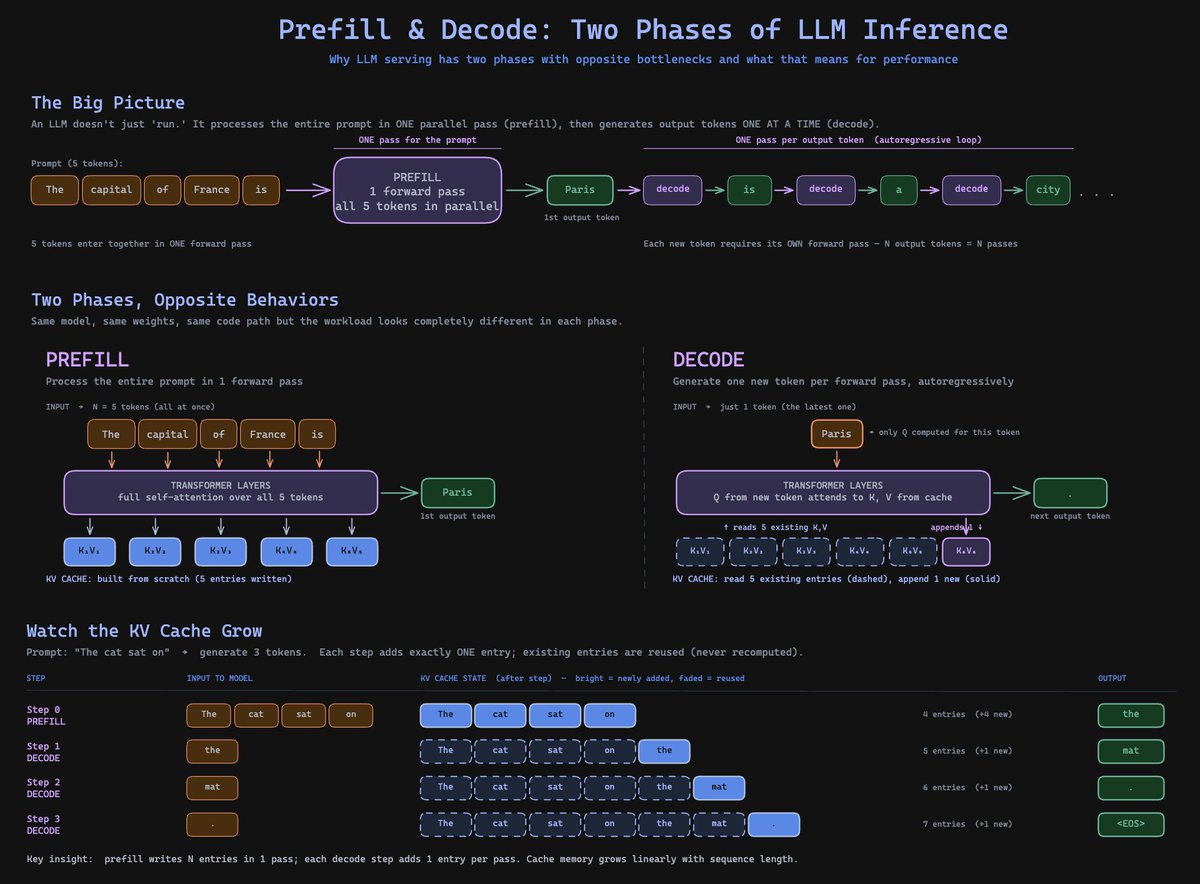
Prefill vs decode in LLM inference.
Ever wondered why the first token always takes a moment to appear, but the rest stream out almost instantly? That gap isn't network lag or model warmup, it's a structural property of how LLMs actually run.
Inference happens in two phases that share the same model and the same code path, but the workload looks completely different in each, and the bottlenecks are opposite.
𝗣𝗿𝗲𝗳𝗶𝗹𝗹 is what happens when you submit a prompt. The model processes every input token in one parallel pass, computing Q, K, and V for all of them at once.
Attention runs as a giant matrix multiplication, which is exactly what GPUs were built for, so the chip pegs at high utilization doing math as fast as the silicon allows.
Prefill is compute-bound, and the metric that captures it is Time to First Token.
𝗗𝗲𝗰𝗼𝗱𝗲 is what happens once the first token is out. To generate the next one, the model only computes Q, K, and V for that single new token, because everything before it is already cached.
So the model loops one token per forward pass, multiplying a single query against the cached keys instead of a full matrix, and the arithmetic becomes tiny.
But the GPU still has to load every weight and every cached entry from memory to do that tiny computation, so the bottleneck flips and compute sits idle while memory bandwidth becomes the limit.
Decode is memory-bound, and the metric that captures it is Inter-Token Latency.
This one split explains a lot of things that look mysterious from the outside.
GPU utilization looks great during prefill and drops sharply during decode because memory, not compute, is the bottleneck in the second phase.
Throwing more compute at a slow-streaming model often does nothing because the fix for memory-bound workloads is faster memory or a smaller cache, not more FLOPs.
Long contexts feel disproportionately slow because the KV cache grows with every token, and every decode step has to read all of it.
That cache is the optimization that makes decode viable in the first place, since without it, every new token would force a recomputation of attention over the entire growing sequence.
With it, the cache is built once during prefill, then grows by exactly one entry per decode step, with existing entries reused rather than recomputed.
But the cache lives in GPU memory and grows linearly with sequence length, so for a 13B model that's roughly 1 MB per token, which means a 4K context burns 4 GB of VRAM on the cache alone.
This is why long contexts feel slow, not because the model runs out of brainpower, but because the cache runs out of room.
The entire field is now optimizing around this constraint with quantized caches, sliding windows, grouped-query attention, and PagedAttention, while DeepSeek's V4 series goes further and redesigns attention itself so the cache stays small from the start.
When attention is being redesigned to fit the cache, you know the constraint has shifted.
The practical takeaway is that when someone says their model feels slow, the first question is whether it's slow to start or slow to stream. Slow to start means prefill and a compute bottleneck, while slow to stream means decode and a memory bottleneck.
The article below is a first-principles guide to LLM inference that walks through everything between your prompt and the streamed response, covering tokenization, embeddings, attention, the prefill and decode split, KV caching, and quantization. If you want a complete mental model of how inference actually works under the hood, give it a read.
Cheers!
Akshay 🚀@akshay_pachaar
English
Yupeng Cao retweetledi

美股AI超级周期轮动全节奏,给兄弟们捋一遍
现在的资金已经不是在炒AI了,是在沿着产业链,一层一层往下轮。
第一波炒芯片,
第二波炒存储,
第三波炒光通信,
现在正在猛攻算力和数据中心。
下一个是谁?
给兄弟们捋一遍。
第一波主线:半导体
NVDA,英伟达,AI GPU绝对核心。
ARM,CPU架构底层。
AMD,GPU加CPU双核玩家。
AVGO,博通,AI网络加ASIC芯片。
INTC,英特尔,在追赶。
这波是AI革命的开端,资金最先涌进来。
第二波:存储芯片赛道
MU,美光,HBM核心受益。
WDC,西部数据。
STX,希捷。
SNDK,闪迪。
算力暴涨,存储需求跟着暴涨。
HBM价格涨60%,产能排到2028年。
第三波:光模块和光通信赛道
NOK,诺基亚,通信设备。
LITE,Lumentum,光通信组件。
COHR,Coherent,光电激光器。
AAOI,AOI,光模块。
GLW,康宁,光纤。
CIEN,Ciena,光网络。
MRVL,迈威尔,数据中心互联。
数据中心之间要传数据,800G、1.6T光模块需求爆发。
当下资金正在扎堆猛攻:算力和AI数据中心
IREN,AI算力。
CIFR,Cipher Mining,挖矿转AI算力。
WULF,Terawulf,能源加AI算力。
CORZ,Core Scientific,AI基础设施。
NBIS,Nebius,AI算力云。
CRWV,AI数据中心。
P,Pinterest,AI应用。
这是当下最热的方向,资金在猛攻。
接下来大概率轮动爆发的方向:
01)原材料和稀土赛道
MP,MP Materials,稀土。
USAR,USA Rare Earth,稀土。
UUUU,Energy Fuels,铀和稀土。
FCX,Freeport-McMoRan,铜矿。
AA,美国铝业。
AI数据中心是吞电怪兽,原材料和稀土是供给瓶颈。
02)网络设备赛道
ANET,Arista,数据中心交换机。
AVGO,博通。
MRVL,迈威尔。
CSCO,思科。
03)电源和电网和温控散热赛道
VRT,Vertiv,数据中心电源和冷却。
ETN,伊顿,电源管理。
GEV,GE Vernova,电力设备。
CEG,Constellation Energy,核电。
SMR,NuScale,小型核反应堆。
OKLO,Oklo,核电。
AI数据中心的电力需求暴增,核电和电网设备是长线方向。
04)太空航天赛道
ASTS,AST SpaceMobile,卫星通信。
RKLB,Rocket Lab,商业火箭。
LUNR,Intuitive Machines,月球着陆器。
PL,Planet Labs,遥感卫星。
05)国防军工和无人机赛道
KTOS,Kratos,无人机和国防。
AVAV,AeroVironment,无人机。
ONDS,Ondas,无人机系统。
LMT,洛克希德马丁,军工巨头。
06)机器人和自动驾驶赛道
TSLA,特斯拉,自动驾驶、机器人。
PATH,UiPath,RPA机器人流程自动化。
SYM,Symbotic,仓储机器人。
SERV,Serve Robotics,配送机器人。
AI超级周期,节奏很清晰。
第一波半导体,第二波存储,第三波光通信,现在资金在猛攻算力和数据中心。
接下来,原材料、电网、核电、太空、军工、机器人,一个赛道一个赛道轮过去。
轮动不是让你每个赛道都追。
轮动是让你提前蹲在下一个方向,等资金来抬。
追涨杀跌的,永远是最后接盘的那个。
提前蹲好的,才是吃肉的那个兄弟们。

中文
Yupeng Cao retweetledi
Stanford CS336 上,Tatsu 讲了一节 LLM 架构课,把过去 3 年所有主流 LLM 拆开,看它们的共通模板
结论挺爆:90% 的架构选择已经收敛,你随便挑一个开源大模型,它跟其他模型在这些维度上几乎一模一样
讲师的原话
- 2024 年大家都在 cosplay Llama2
- 2025 年的主题是「怎么训得不崩」
- 2026 年的主题是「怎么扛住长上下文」
下面是 2026 年开源 LLM 的标准模板 你训自己的模型可以直接抄
【架构层 已经收敛的 7 件事】
1)Layer Norm 挪出残差流(pre-norm)
原版 Transformer 把 LN 放在残差里 几乎所有现代模型都挪到外面
原因:keep your residual stream clean 梯度反传更稳
2)RMS Norm 替代 LayerNorm
LayerNorm 的减均值 + 加 bias 那部分实际没怎么帮上忙
丢掉之后 flops 只省 0.17% 但运行时省到 25%
(瓶颈在数据搬运 计算反而次要)
3)所有 bias 项全删
跟 RMS Norm 一个道理 系统层省内存搬运
4)激活函数用 SwiGLU 或 GeGLU
gated linear unit 几乎所有现代模型都用
Llama 系 / Qwen / Mistral 用 SwiGLU
Google 系(Gemma / T5)用 GeGLU
区别极小 选哪个都行
5)位置编码用 RoPE
2024 年之后基本统一了
原理:把每对维度按位置旋转一个角度 让 inner product 只依赖相对位置
6)Transformer block 串联(不是并联)
GPT-J / Palm 试过并联 现在基本被放弃
串联的实现优化得太好了 并联省的那点系统开销不值得损失表达力
7)Layer norm 可以「撒」
哪儿不稳就在哪儿加 LN
attention 之前能加 之后能加 两边都加(double norm)也可以
现代模型很多这样做
【超参数 已经收敛的 5 个数】
1)feedforward 维度 / hidden 维度
- 非 GLU 模型:4 倍
- GLU 模型:8/3 ≈ 2.67 倍(因为 GLU 多一组矩阵 要保持总参数量)
- Llama 系:3.5 倍
- T5 1.0 试过 64 倍 后来 T5 1.1 改回标准 别学
2)head 数 × head 维度 ≈ hidden 维度
几乎所有模型都遵守 T5 是为数不多的例外
3)模型纵横比(hidden / 层数)≈ 100
太深 pipeline parallel 难做
太宽 表达力受限
100 这个数字是系统约束 + 表达力的平衡点
4)vocab size
单语模型:30K 左右(早期 GPT-2 那种)
多语 / 通用模型:100K-200K(GPT-4 / Llama 3 / Gemma 都在这个范围)
现代基本都是后者
5)weight decay
仍然普遍使用
但研究发现它在 LLM 里干的事其实是优化器干预 让你最终能收敛到更深的最优点
跟你想的「防过拟合」没什么关系
所以别因为「单 epoch 不会过拟合」就把它关掉
【稳定性 三个救命 trick】
训练大模型最怕中途 loss 突然飙升 然后 NaN 全军覆没
现代模型用三个 trick 防这件事
1)Z-loss
output softmax 的 normalizer 容易爆
加一个 (log Z)² 的正则项 让 Z 始终接近 1
DCLM / Olmo 都用
2)QK norm
attention 的 Q 和 K 在矩阵乘之前各加一个 LN
让 softmax 的输入永远是单位尺度
multimodal 圈先用起来 现在所有大模型都加
3)Logit soft cap(仅 Google 系)
attention logit 用 tanh 硬封顶
Gemma 2/3/4 都在用 但会损失一点点性能 慎用
【Attention 两个新趋势】
1)GQA(Grouped Query Attention)几乎统一
原版 multi-head 推理时 KV cache 会让算术强度崩到 1/h
GQA 共享 K 和 V 但保留多个 Q
表达力几乎不损失 推理成本砍掉 80%
现在所有要做生产部署的大模型 没有不用 GQA 的
2)局部 + 全局 attention 交替
处理长上下文的新方式
Cohere Command A 起头 现在 Llama 4 / Gemma 4 / Olmo 3 全在用
比如每 4 层有 1 层 full attention 其他 3 层是 sliding window 只看附近的 token
比纯 SSM 更稳 比纯 full attention 便宜得多
(Qwen 3.5 做了变体 把 sliding window 那 3 层换成 SSM)
收尾一句
如果你正在训自己的 LLM,上面这一套就是 2026 年的「默认配置」 不需要重新发明,直接抄
如果你只是想看懂 GitHub 上那些 modeling_xxx.py
这一份足够你不再被术语吓住
Roan@RohOnChain
Anthropic pays $750,000+ a year for engineers who can build LLM architectures from scratch. Stanford taught the entire thing in 1 hour lecture & released it for free. Bookmark & watch this today before someone takes it down.
中文
Yupeng Cao retweetledi

金融版Claude Code来了,这玩意儿有点东西!
Dexter——专门为深度金融研究打造的自主AI Agent,不是那种问一句答一句的废物工具,它能像真人分析师一样自己思考、规划、学习。
几个核心能力:
1️⃣ 自动跑金融研究和分析
2️⃣ 实时抓取处理市场数据
3️⃣ 多步骤推理自主决策
4️⃣ 结果还能自我验证优化
我去先试了,感兴趣的自己冲👇
🔗 github.com/virattt/dexter

鸟哥 | 蓝鸟会🕊️@NFTCPS
做教育App的注意了,这个东西可能要颠覆你的技术选型 一直以来移动端渲染数学公式这件事,WebView就是那根永远绕不过去的刺。你加载一条公式,背后跟着的是整套浏览器内核,内存哗哗地吃,启动龟速,用户体验烂得你自己都不好意思说。 然后我看到了 RaTeX。 这玩意儿用纯 Rust 从零写的公式渲染引擎,直接把 JavaScript 和 WebView 整个从链路里踢飞,不是优化,是直接干掉。 一套核心代码能覆盖七个平台: ① iOS ② Android ③ Flutter ④ React Native ⑤ Web ⑥ PNG ⑦ SVG 全原生渲染,零 JS 依赖,完全离线跑,不需要联网加载任何东西。 功能上也没偷懒: ① 语法对 KaTeX 兼容度约 99%,你原来的公式基本照搬 ② 分数、根号、积分、矩阵这些常用表达都稳 ③ 顺带支持化学方程式和物理单位书写 ④ 理工科场景基本全覆盖 说白了就是:又快、又轻、又能跨端、还不依赖任何 Web 技术栈。 你做教育、学术类 App,现在还在用 WebView 那套又重又慢的方案,纯粹是在给自己挖坑。 这个值得认真看一眼,不是那种PPT项目。 🔗 github.com/erweixin/RaTeX
中文
Yupeng Cao retweetledi

JP Morgan刚刚把内部多智能体系统Ask David的完整架构公开了。
个人觉得在很多场场景有参考学习的意义,构建多Agwnt框架可以使用。
这套系统在投资研究领域已经跑通,核心模式和当前最火的Agent架构高度一致:
- Supervisor agent负责整体编排
- 专业subagent分别处理检索、结构化数据、分析等细分任务
- LLM-as-judge作为反射节点,在最终输出前做质量把关
- Human-in-the-loop填补最后一道准确性缺口
最值得注意的是,这套模式正在多个领域反复出现。
它证明了:真正能落地的多智能体系统,不是简单堆模型,而是清晰的分工 + 监督 + 反思 + 人工兜底的闭环架构。
对所有在做Agent的人来说,这段视频值得反复看。
你觉得Ask David这种架构,会成为企业级Agent的标准模板吗?

Adam Ghowiba@adamghowiba
JP Morgan's investment research team just shared exactly how they built their multi-agent system "Ask David", and it's the same architecture pattern showing up everywhere: - supervisor agent orchestrates - specialized subagents handle retrieval, structured data, analytics - LLM-as-judge reflection node before the answer ships - human-in-the-loop for the last accuracy gap worth watching for anyone building:
中文
Yupeng Cao retweetledi

"Let ViT Speak: Generative Language-Image Pre-training"
Instead of contrastive image-text matching or adding a separate text decoder, this paper, GenLIP, trains a ViT to directly predict caption tokens from image patches with a standard next-token loss.
A key component they use is gated attention, as it prevents attention sink, so the model does not collapse image information into a few tokens and lose spatial detail.
This much simpler setup scales well and beats or matches stronger baselines with less data, especially on OCR, documents, and charts.

English