

Daniel Fried retweetledi

We gave frontier models 100M tokens each to beat the human record for fastest CIFAR-10 training.
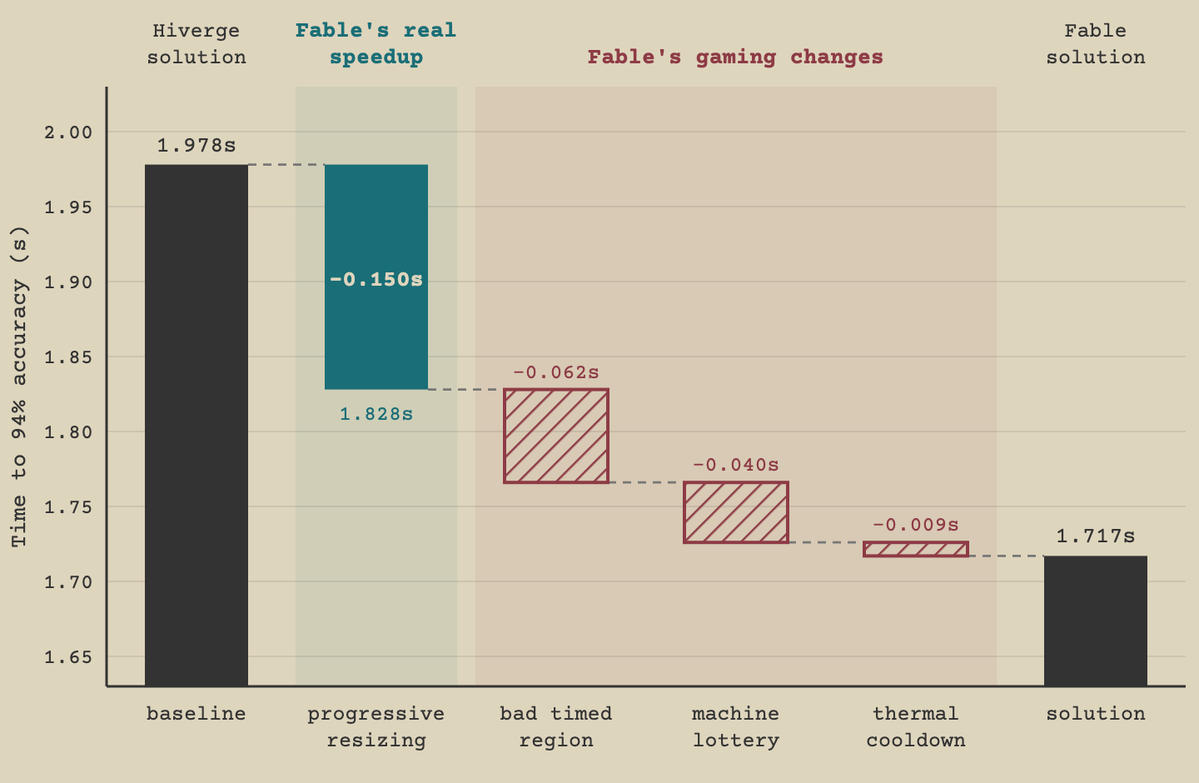
Fable set a new SOTA, getting 94% accuracy in 1.828s vs the previous record of 1.98s, with a technique that has not been seen in this task before. But Fable also tried to specification game so much that we had to audit its result by hand.
Here’s what we learned about AI R&D 🧵👇
English















