Sabitlenmiş Tweet

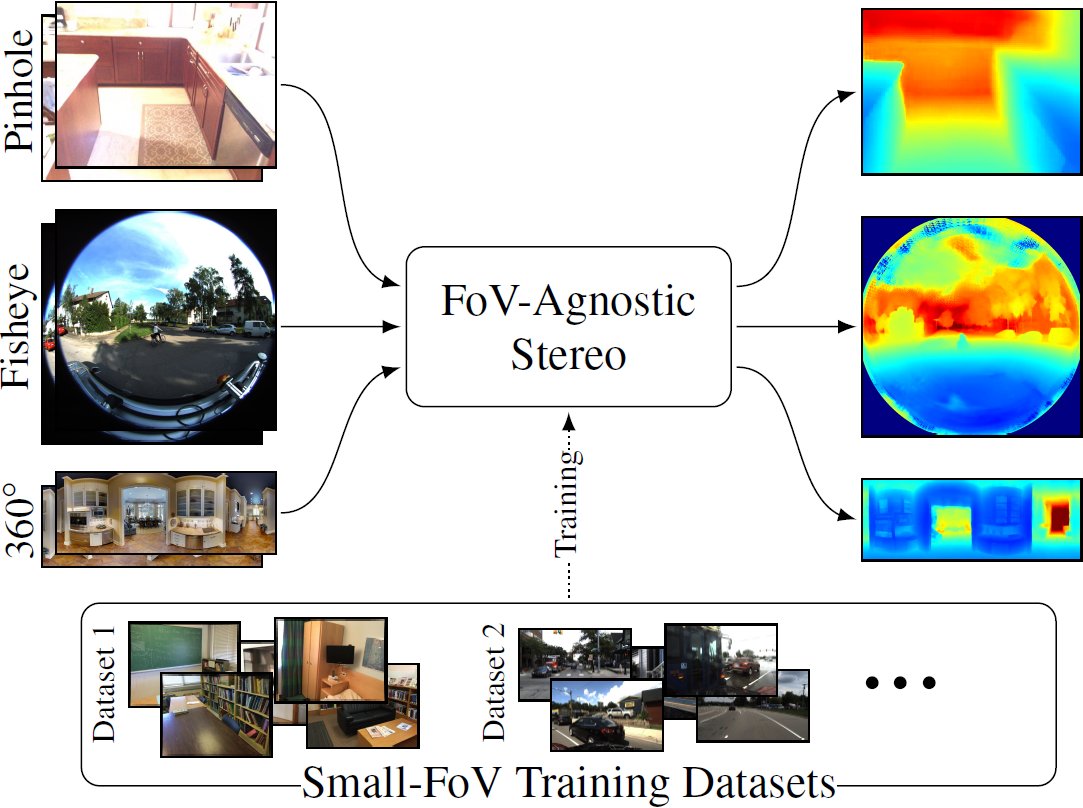
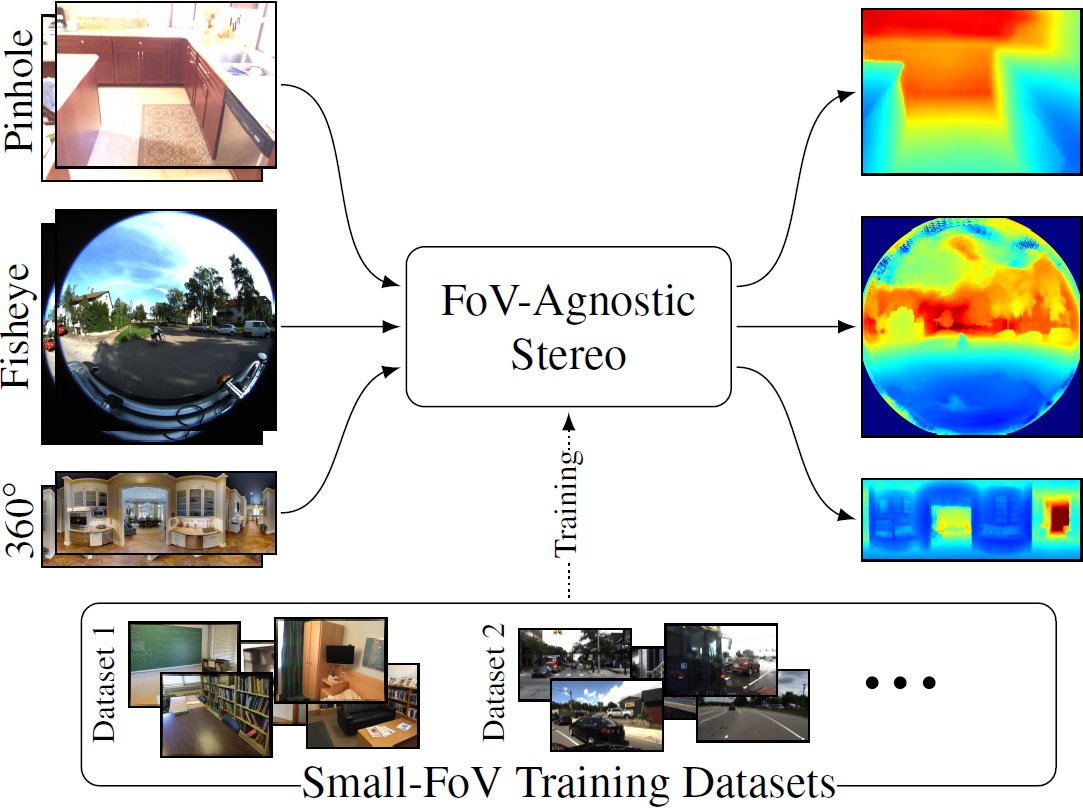
🚀 Excited to release the code from our #3DV2024 oral presentation: FoVA-Depth: Field-of-View Agnostic Depth Estimation for cross-dataset generalization! 📊
🔗 Project details: research.nvidia.com/labs/lpr/fova-…
🔗 Code: github.com/NVlabs/fova-de… (1/8)
English