Dave.Wang
39 posts


AI agent终于有专属的Slide框架了。
open-slide 直接把“prompt一下就出一整套精美幻灯片”变成了现实。
它不是简单生成Markdown,而是把每张幻灯片做成React组件,固定1920×1080画布,内置agent技能:
- /create-slide:一句话prompt就能生成完整deck
- /apply-comments:在浏览器里点元素留评论,agent一键应用所有修改
- 内置演示模式、演讲者笔记、定时器
- 一键导出HTML/PDF
- 支持Claude Code、Cursor、Codex等任意编码agent
最重要的是,它把agent从“聊天生成文字”升级成了“真正能输出可呈现成品”的生产力工具。
GitHub:github.com/1weiho/open-sl…
Demo:demo.open-slide.dev
这波操作,直接填补了agent和真实产出之间的最后一公里。
你觉得agent时代,Slide生成会不会成为标配技能?
Yiwei Ho@1weiho
Introducing open-slide - The slide framework built for agents. Prompt your agent, get a polished deck. $ npx @open-slide/cli init 👇
中文



If you keep notes in Obsidian, articles in Readwise, or research in NotebookLM, the full walkthrough is below.
decodingai.com/p/llm-knowledg…
English
Andrej Karpathy calls it an LLM Knowledge Base. I've been building one on my own notes for months without knowing that was the name for it.
I use Obsidian for notes, Readwise for reading, and NotebookLM for research. No AI reaches across all three. Generic tools like Perplexity and Gemini Deep Research only search the public web. Everyone gets the same sources. The real edge is your own curated thinking.
I built three Claude Code skills (/research_create, /research_search, /research_distill) running on the obsidian, readwise, and NotebookLM CLIs.
No vector database. No RAG pipeline. Just the filesystem, Markdown, YAML, and progressive disclosure via index.yaml.

English

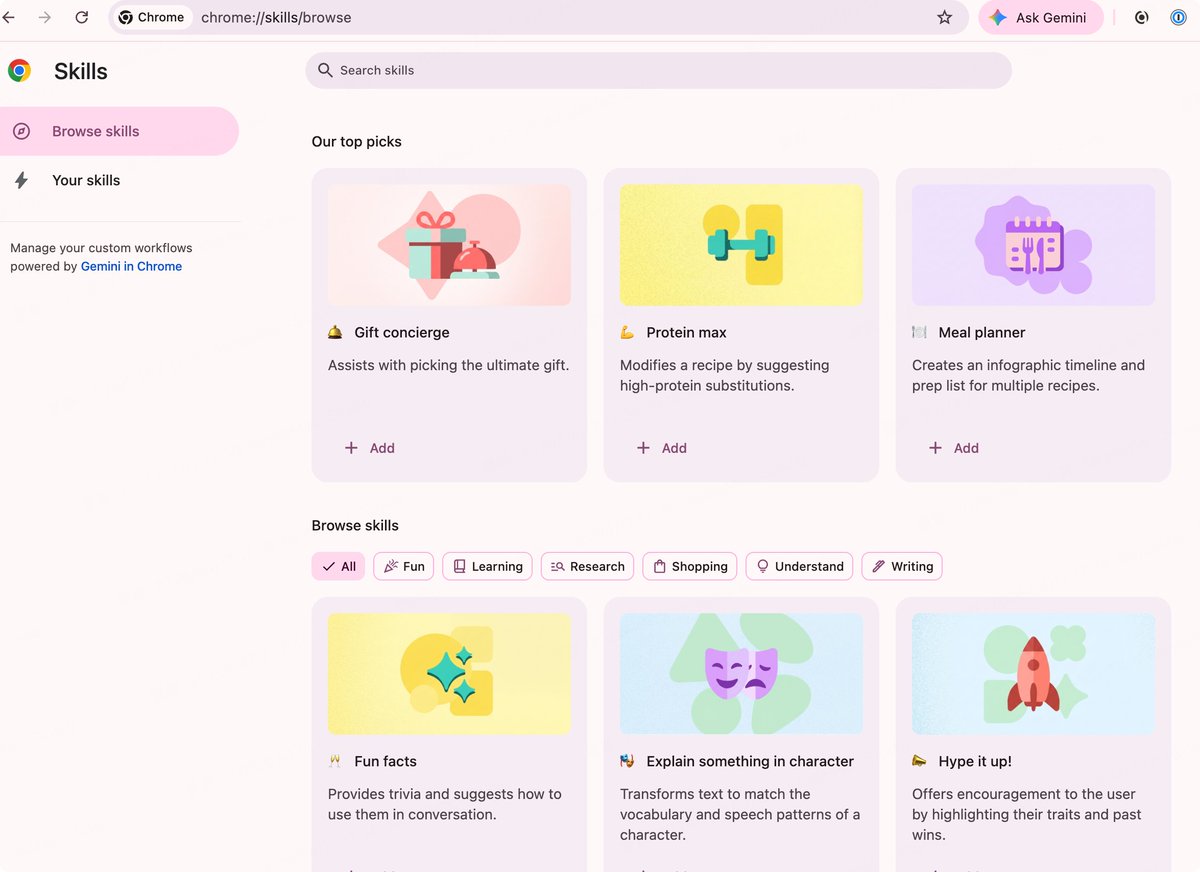
Chrome Gemini Skills 强制开启全攻略
━━━━━ 🧵 1/5 ━━━━━
🚀 第一步:常规设置
1️⃣ 检查更新:
地址栏输入 chrome://settings/help 更新后【完全重启】。
我目前的版本是 147
2️⃣ 切换美式英语(最关键):
前往 chrome://settings/languages
将 English (United States) 设为置顶。
3️⃣ 验证:
输入 chrome://skills/browse 尝试进入技能库。如果不显示,看下一步 👇
━━━━━ 🧵 2/5 ━━━━━
🛠 第二步:手动激活「实验性开关」
地址栏输入 chrome://flags 搜索关键词 「Glic」
将以下选项全部改为 【Enabled】:
🔹 Glic
🔹 Glic side panel
🔹 Glic actor
🔹 Enables Skills in Gemini
点最下方的「Relaunch」重启,这是成功开启的「捷径」。
━━━━━ 🧵 3/5 ━━━━━
🔥 第三步:终极绝招(非美区用户必看)
如果上述方法失效,需要强制修改本地配置文件:
1️⃣ 彻底退出 Chrome(确保后台进程全部关闭)。
2️⃣ 找到文件:
📂 Windows: AppData/Local/Google/Chrome/User Data
📂 Mac: ~/Library/Application Support/Google/Chrome/
3️⃣ 用记事本打开 Local State 文件,搜索并修改:
"is_glic_eligible": true,
"variations_country": "us",
"variations_permanent_consistency_country": "us"
4️⃣ 保存并重开 Chrome。
━━━━━ 🧵 4/5 ━━━━━
🎮 如何玩转你的新技能?
📌 快捷键 Ctrl + . (Mac 用 Cmd) 唤出侧边栏。
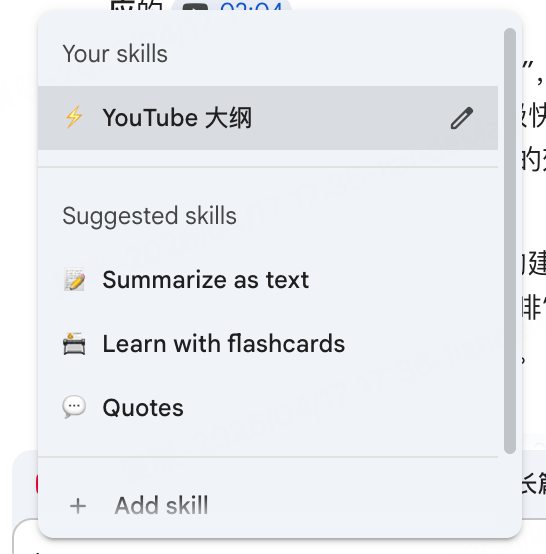
👉 输入 「/」 瞬间召唤你的技能包:
✅ 跨标签页自动比价
✅ 一键总结 YouTube 视频
✅ 专业级论文摘要提取
💡 看到官方库里好用的,直接点添加;看到聊天里神级的 Prompt,点「Save as Skill」永久珍藏。
━━━━━ 🧵 5/5 ━━━━━
⚠️ 特别提醒:
🔸 若还未生效,建议连接美国节点再重启。
🔸 目前仅限桌面版,移动端暂未推送。
一旦开启,你的浏览器就是最强的 AI 工作站!有什么具体的 Skill 想做?评论区告诉我。
#Chrome #Gemini
中文

我去,这效果确实牛逼,非常的上流!
探索出了一条用 Gemini 和 NanaBana2 配合来生成 logo 以及 logo 展示图的工作流。




歸藏(guizang.ai)@op7418
Gemini 真是做设计的一把好手,尤其是用 SVG 画 logo 只要给一些适当的引导就可以画的很好 给 Codepilot 的新 logo SVG 的部分也是他完成的,我自己在基础上精修
中文

今天给Obsidian微信读书插件release 了 1.0.0, 我在这个版本里增加了多年前一直想做的功能:书架主页,把本地笔记和远程书架打通,展示笔记的各种状态,也方便跳转本地笔记、跳转网页版, 在设置里增加了两种同步模式设置,方便过滤数据,更多信息参考 Github release: github.com/zhaohongxuan/o…


中文

@shtol1k @obsdmd Obsidian plugin. I just submitted it to the community plugins, but you can install it manually for now.
github.com/Railly/agentfi…
English


杨植麟、张鹏、罗福莉等齐聚一堂,他们关于OpenClaw的观点值得一听。
今天是2026中关村论坛的人工智能主题日。
我也定了个一早的闹钟准时起来看。
这个活动海淀已经办了第三年,但今年的议程密度确实有点夸张。
一上午塞进了开源联盟成立、主权大模型白皮书发布、北京市人工智能协会揭牌,外加两场圆桌。
大模型和具身智能各一场。嘉宾阵容从Eclipse基金会到智谱、小米MiMo、无问芯穹,再到一众具身智能公司的创始人,几乎把当下AI产业链上最活跃的角色都拉到了同一个舞台上。
在我看来,信息密度最高的,还是第一场小龙虾与AI开源圆桌。
这场圆桌由杨植麟主持,嘉宾是智谱的张鹏、无问芯穹的夏立雪、小米MiMo的罗福莉,还有港大的黄超。
从模型层到算力基础设施层再到Agent应用层,刚好覆盖了当下AI产业链的几个关键环节。
张鹏解释了智谱GLM5 Turbo提价的逻辑,模型从聊天转向干活,完成任务消耗的token量可能是简单问答的十倍甚至百倍,提价本质上是在回归商业价值。
罗福莉谈了中国团队在模型结构创新上的优势,尤其是长上下文架构和推理效率。
黄超拆解了Agent在planning、memory、skill三个维度上的技术痛点。
最后让每人用一个词总结未来12个月的趋势,黄超说的是生态,罗福莉说的是自进化,夏立雪说的是可持续token,而张鹏直接点了一个最朴素的问题:算力。
几位嘉宾的圆桌对话,干货含量极高,几乎没有什么客套和PR话术,聊的都是非常实在的问题。
所以,我也把这场圆桌的内容做了一个完整的文字整理,分享给大家。
【圆桌对话-人类校对版】
杨植麟(主持人):很荣幸今天能邀请到各位重磅的嘉宾,各位的背景覆盖了不同的层面,从模型层到底层的算力层,再到上面的Agent层。很高兴今天能和大家一起探讨,主要的关键词是开源和Agent。我们从第一个问题开始,这个问题是给所有人的。
现在OpenClaw是最流行的产品,大家在日常使用OpenClaw或类似产品的过程中,觉得最有想象力或者印象最深刻的是什么?从技术角度来看,如何看待今天OpenClaw和相关Agent的演进?我们先从张鹏这边开始。
张鹏 :好,首先感谢植麟的邀请,也感谢主办方给这次机会跟大家交流。其实我很早就开始自己玩这个东西了,当时还不叫OpenClaw,最早叫Clawdbot。
毕竟我是程序员出身,折腾这些东西有一些自己的体验。我觉得它带给大家最大的突破点,在于这件事情不再是程序员或者极客们的专利,普通人也可以比较方便地使用顶尖模型的能力,尤其是在编程和智能体方面。
所以到现在为止,我在跟大家交流的过程中,更愿意把OpenClaw这件事称作一个脚手架,它提供的是一种可能性。在模型的基础之上搭起一个牢固、方便又灵活的脚手架,大家可以按照自己的意愿去使用底层模型提供的很多新奇的东西。原来自己的一些想法,受限于不会写代码或者缺乏某些技能,今天终于可以通过很简单的交流就把它完成。这对我来说是一个非常大的冲击,让我重新认识了这件事情。
夏立雪 :我最开始用OpenClaw的时候其实不太适应,因为我习惯于和大模型聊天的那种交流方式,结果发现OpenClaw反应好像比较慢。但后来我意识到一个关键的不同,它不是一个聊天机器人,而是一个能够帮我完成大型任务的助手。当我开始给它提交更复杂的任务之后,发现它其实能做得很好。这件事给我一个很大的感触,就是AI从最开始按token聊天,到现在能够作为一个Agent帮你完成任务,对整个AI的想象力空间做了一个很大的提升。但与此同时,它对整个系统的能力要求也变得很高,这也是我一开始用会觉得卡顿的原因。
作为基础设施层的厂商,我看到OpenClaw为整个AI后续的大型系统和生态带来了更多机遇和挑战,因为现在所有能用到的资源,想要支撑起这样一个快速增长的时代是不够的。就拿我们公司来说,从一月底开始,基本上每两周token用量就翻一番,到现在已经翻了十倍。上次见到这种速度,还是当年3G时代手机流量增长的那种感觉。现在的token用量,就像当年每个月只有一百兆手机流量的那个时代一样,所有资源都需要更好的优化和整合,让每一个人都能把OpenClaw这样的AI能力用起来。所以作为基础设施领域的从业者,我对这个时代非常激动,认为其中有很多值得去探索和尝试的优化空间。
罗福莉 :我把OpenClaw视为Agent框架上一个非常革命性和颠覆性的事件。虽然我知道身边深度使用编程工具的人,第一选择可能还是Claude Code,但我相信只有用过OpenClaw的人才能独特地感受到,这个框架在设计上有很多地方是领先于Claude Code的,包括最近Claude Code的很多更新,其实都是在向OpenClaw靠近。对我自己来说,OpenClaw这个框架带来更多的是一种随时随地的想象力延伸。Claude Code可能最开始只能在桌面上延展创意,但在OpenClaw里我可以随时随地延展想法。
我后来发现,OpenClaw核心价值在于两点:第一是它开源,开源对整个社区深度参与、持续改进Agent框架是一个非常重要的前置条件。第二,像OpenClaw这样的Agent框架,它很大的价值在于把国内水平接近但略逊于闭源模型的这一赛道上的模型上限拉得非常高,在绝大部分场景里任务完成度已经非常接近Claude最新的模型。同时它又通过Harness系统或者Skills体系等诸多设计,把下限保证得非常好。从基座大模型的角度来说,它保证了下限,同时也拉升了上限。此外,我认为它给整个社区带来的更大价值,是点燃了大家对模型之外的那一层的热情,让大家发现Agent这一层有非常多的想象力和空间可以发挥。这也让社区里越来越多除研究员以外的人参与到AGI的变革当中,更多人接触到更强的Agent框架,一定程度上在替代自己重复性的工作,释放时间去做更有想象力的事情。
黄超 :从交互模式上来讲,我觉得OpenClaw这次爆火,首先是因为给大家一种更有活人感的感觉。我们其实做Agent也有一两年了,但之前包括Cursor、Claude Code这些Agent,大家感受到的更多是一种工具感。OpenClaw第一次以IM软件嵌入的交互方式,让大家更有一种活人感,更接近于自己想象中的个人贾维斯那样的概念,这是交互模式上的突破。另外它给大家带来的一个启发是,Agent Loop这种非常简单但高效的框架,再次被证明是行之有效的。同时它也让我们重新思考,究竟是需要一个all-in-one的非常强大的智能体帮我们做很多事情,还是需要一个像轻量级操作系统或脚手架一样的小管家。OpenClaw的答案是,通过这样一个轻量级的操作系统生态,去撬动整个生态里所有的工具。随着Skills和Harness这些机制的普及,越来越多的人可以设计面向OpenClaw这类系统的应用,赋能各行各业。这与整个开源生态天然结合得非常紧密,我觉得这两点是它带给我们最大的启发。
杨植麟(主持人):顺着这个话题,刚才一直在讨论OpenClaw。想问一下张鹏,看到最近智谱也发布了新的GLM5 Turbo模型,我理解在Agent能力上也做了很大的增强,能不能给大家介绍一下这个新模型和其他模型的不同之处?另外我们也观察到有一个提价的策略,这反映了什么样的市场信号?
张鹏 :这是个很好的问题。前两天我们确实紧急做了一波更新,这其实是我们整个发展路线中的一个阶段,提前把它放出来了。这件事最主要的目的,是从原来简单的对话转向真正的干活。正如各位刚才说的,OpenClaw真的让大家觉得大模型不再只是聊天,而是能帮我干活。但干活背后对能力的要求是非常高的,它需要自主进行长程任务规划,不断压缩上下文、debug、处理多模态信息等等,这和传统面向对话的通用模型的要求有很大的不同。所以GLM5 Turbo在这方面做了专门的加强,尤其是长程任务如何能够持续自主loop而不中断,这里做了很多工作。
另外,大家也提到了token消耗的问题。让一个聪明的模型去完成复杂任务,token消耗量是非常巨大的,可能一般人体会不到,只会看到账单上的钱在不停地往下掉。所以我们在这方面也做了优化,面临复杂任务时用更高效的token效率来完成。模型架构上本质还是多任务协同的通用架构,只是在能力上做了一些偏向性的加强。至于提价这件事,其实也很顺畅地能跟大家解释。现在不再是简单的一问一答,背后的思考链路很长,还要通过写代码的方式跟底层基础设施打交道、随时debug和纠错。完成一个任务需要的token量,可能是原来回答一个简单问题的十倍甚至百倍。模型变得更大,推理成本相应提高,所以我们把价格回归到正常的商业价值上。长期靠低价竞争不利于整个行业发展,这样才能持续在商业化路径上形成良性闭环,不断优化模型能力,持续给大家提供更好的模型和相应的服务。
杨植麟(主持人):非常好的分享。现在开源模型和推理算力已经开始形成一个生态,各种开源模型可以在不同的推理算力上为用户提供更多价值。随着token量的报价变化,我们可能也正在从训练时代逐渐进入推理时代。想请教一下立雪,从infra的层面来看,推理时代对于无问芯穹意味着什么?
夏立雪 :我们是一家诞生在AI时代的基础设施厂商,现在在为Kimi、智谱提供服务,也在跟MiniMax合作,帮助大家更高效地用好我们这个token工厂。我们也在和很多高校、科研院所合作,所以一直都在思考一个问题:AGI时代所需要的基础设施,究竟应该是什么样的?我们怎么能够一步步地在这个过程中去实现它、推演它。
我们已经做好了充分的准备,也看清了短期、中期、长期不同阶段需要解决的问题。当前最紧迫的问题,就是像Claude这类模型带动的整个token量的暴增,对我们系统效率提出了更高的优化需求,价格的增长也是在这个需求压力下的一种应对方式。
我们一直以来都是从软硬件打通的方式来布局和解决这个问题。我们接入了几乎所有种类的计算芯片,把国内十几种芯片和几十个不同的算力集群统一连接起来。这样,当资源不足时,我们能做到两件事:第一,把能用的资源都用起来;第二,让每一个算力都用在刀刃上,发挥出最大的转化效率。所以当前阶段我们要解决的核心问题,就是如何打造一个更高效的token工厂。为此我们做了很多优化,包括让模型与硬件在显存等方面实现最优适配,也在探索在最新的模型结构和硬件结构下能否产生更深度的化学反应。
不过,解决当前的效率问题,我们只是打造了一个标准化的token工厂。面向Agent时代,这还远远不够。就像刚才说的,Agent更像一个人,你可以交给他一项任务。我坚定地认为,当前云计算时代的很多基础设施,是为服务程序、服务人类工程师而设计的,而不是为AI设计的。现在的状态有点像:我们搭了一套基础设施,上面留了一个为人类工程师设计的接口,然后在这上面再包一层去接入Agent。这种方式实际上是用人类操作的能力边界,限制了Agent的发挥空间。
举个例子,Agent能够在秒级甚至毫秒级思考并发起任务,但我们之前的底层K8S这些能力并没有为此做好准备,因为人类发起任务大概是分钟级别的。所以我们需要进一步构建我们称之为Agentic Infra的能力,打造一个更智慧化的算力投放工厂。这是无问芯穹现在正在做的事情。
从更长远的未来来看,真正AGI时代到来的时候,我们认为连基础设施本身都应该是一个智能体,应该能够自我进化、自我迭代,形成一个自主的组织。相当于有一个CEO,这个CEO是一个Agent,比如一个Claude在管理整个基础设施,根据AI客户的需求自己提需求、迭代自己的基础设施。只有AI与AI之间才能更好地形成耦合。所以我们也在做一些让Agent与Agent之间更好通信的事情,比如cache to cache这样的复制能力。
我们一直认为,基础设施与AI的发展不应该是隔离的状态,而应该产生非常丰富的化学反应。这才是真正的软硬协同,真正的算法与基础设施协同。这也是无问芯穹一直想实现的使命。
杨植麟(主持人):接下来想问问福莉。小米最近发布了新的模型,也开源了一些背后的技术,我觉得对社区做出了很大的贡献。想请问一下,小米在做大模型方面有什么独特的优势?
罗福莉 :我想先把这个问题稍微拓展一下,不只聊小米的优势,而是聊聊中国做大模型的团队在这件事上的优势,我觉得这个话题有更广泛的价值。
大概两年前,我就观察到中国的基座大模型团队已经开始了一个非常好的突破。这个突破是:在有限算力的条件下,尤其是在互联带宽受限的情况下,如何突破这些低端算力的限制,并由此催生了一些看似是为效率妥协的模型结构创新,比如DeepSeek v2、v3系列的细粒度MoE等等。但我们后来能看到,这些创新引发的是一场变革,也就是在算力一定的条件下,如何发挥出最高的智能水平。我觉得DeepSeek给了国内所有技术大模型团队一份勇气和信心。
虽然今天我们自己的国产芯片,无论是推理芯片还是训练芯片,已经不再像以前那样受到严重限制,但我们能看到,正是那些限制催生了我们对更高训练效率、更低推理成本的模型结构的全新探索。比如最近出现的hybrid sparse或linear attention结构,有DSA、NSA,Kimi有KSA,小米也有面向下一代结构的high sparse架构。这区别于MiMo这一代结构,是我们面向Agent时代去思考的,如何在Agent时代做出更好的模型结构创新。
我为什么认为结构创新如此重要?因为我们刚才聊到了long context这个话题。如果大家真实地去用OpenClaw就会发现,越用越好用,越用越聪明。它的前提是推理的context足够长。long context是一个谈论了很久的话题,但真正能做到在超长context下表现强劲、推理成本足够低的模型,其实并不多。很多模型不是做不到百万甚至千万token的context,而是推理成本太高、速度太慢。只有当你能在百万甚至千万context下做到成本够低、速度够快,才会有真正高生产力价值的任务被交给这个模型,从而激发模型在long context场景下完成更高复杂度的任务。我们可能需要在这样千万甚至亿级context的规模下,才能实现模型的自迭代。所谓模型的自迭代,就是它可以在复杂的环境里依靠超长context完成对自我的进化,这个进化可能是对Agent框架本身的,也可能是对模型参数本身的,因为我们认为long context本身就是对参数的一种进化。
所以,怎么实现long context efficient的架构,以及在推理侧做到long context efficient,是一个全方位的竞争。这是我们大约一年前就开始探索的问题。而如今,怎么在真实的长程任务上实现稳定性和高上限的效果,是我们现在在持续迭代的创新方向。我们在思考如何构造更有效的学习算法,如何采集到真实的、在百万乃至千万上下文里具有长距依赖的文本,以及结合复杂环境产生的trajectory,这是我们正在经历的事情。
但我能看到更长期的事情是,大模型本身在飞速进步,加上Agent框架的加持,推理需求已经在过去一段时间内增长了近十倍。那今年整个token的增长会不会达到百倍?这又将我们带入另一个维度的竞争,那就是算力,推理芯片,乃至往下到能源层面。这是我对这个问题的判断,也期待从大家身上学到更多。
杨植麟(主持人):非常有insight的分享。下面想问一下黄超,因为你也开发了一些非常有影响力的agent项目,包括nano bot,在社区里也有很多粉丝。想问一下,从agent的harness或者说应用层面,接下来你觉得有哪些技术方向是比较重要、大家需要去关注的?
黄超 :感谢。我觉得首先可以从agent的几个关键技术模块来拆解,包括planning、memory和tool use。
从planning来讲,现在面向长链路任务或者非常复杂上下文的场景,比如说五百步甚至更长的任务,很多模型不一定能做好planning,我觉得本质上是模型不具备这方面的隐性知识,尤其是在一些复杂垂直领域。未来可能需要把各类复杂任务的知识固化到模型里,这是一个方向。当然,skill和harness这种机制,在一定程度上也是在缓解planning层面的错误,因为它提供了比较高质量的skill,本质上是在帮助模型去完成一些较难的task。
关于memory,我的感受是它永远存在信息压缩不准确、召回不准的问题。当整个长链路任务和复杂场景展开时,memory会急剧膨胀,这对整个memory架构造成很大压力。目前包括各类agent框架基本上都采用最简单的文件系统、Markdown格式来做memory,通过文件共享来协作。我觉得未来memory应该走向分层设计,并且需要解决通用性的问题,因为coding场景、deep research场景、多媒体场景的数据模态差异很大,如何对这些memory做好检索索引、提升效率,这永远是一个trade off。
另外,现在agent框架让大家创建agent的门槛大幅降低,未来可能不止一个agent,我也看到有些产品推出了Agent Swarm这样的机制,相当于每个人会拥有一群龙虾。一群龙虾相比一个龙虾,上下文的暴增是可以想象的,这对memory带来的压力非常大。如何管理一群龙虾带来的上下文,目前还没有很好的机制,尤其是在复杂coding、科研发现这类场景下,对模型和整个agent架构都是不小的挑战。
关于tool use,当年MCP存在的问题,比如质量没有保障、存在安全隐患,现在在skill里依然存在。目前看似有很多skill,但高质量的skill其实比较少,低质量的skill会严重影响agent完成任务的完成度。另外skill也存在恶意注入的风险。所以我觉得tool use这块可能需要整个社区共同努力,把skill生态发展得更好,甚至探索如何在执行过程中进化出新的skill。以上这些,是我认为当下agent在planning、memory、skill三个维度上存在的痛点,以及未来潜在的方向。
杨植麟(主持人):可以看到刚才两位嘉宾从不同视角讨论了同一个问题,随着任务复杂度增加,上下文会急剧膨胀。从模型层面可以去提升原生的上下文处理能力,从agent harness层面,则是通过planning、memory,包括multi-agent的harness,在模型能力一定的情况下支持更复杂的任务。我觉得这两个方向接下来会有更多的化学反应,共同提升完成复杂任务的能力上限。
那最后我们来一个开放式展望,请各位用一个词来描述接下来十二个月大模型发展的趋势以及你的期望。这次我们先从黄超开始。
黄超 :十二个月在AI领域看起来好遥远,真的不知道十二个月之后会发展成什么样子。
杨植麟(主持人):这里原来写的是五年,我给改成十二个月了。
黄超 :对,我这边的关键词应该是生态。未来agent要真正从个人助手转化为打工人,这一步很重要。现在大家玩agent很多时候还停留在新鲜感阶段,觉得好玩,但未来真正要让agent沉淀下来,成为大家真正的搬砖工具,或者说真正的co-worker。这需要整个生态的共同努力,把所有相关的技术探索和模型技术都开源出来,不管是模型迭代、skill平台迭代还是各类工具,都需要面向agent打造更好的生态。
从我自己的感受来说,未来的很多软件可能不再是面向人类的。人类需要GUI,但很多软件可能会是面向agent原生设计的,人类只会去使用让自己快乐的GUI,其他的交给agent。所以现在整个生态从GUI、MCP又转向了CLI这样的模式。我觉得需要整个生态把不管是软件系统、数据还是各种技术,都变成Agent Native的模式,这样才能让整个agent的发展更加丰富。
罗福莉 :我觉得把这个问题缩小到一年非常有意义,因为五年这个时间跨度,从我心目中对AGI的定义来看,我觉得已经实现了。所以如果要用一个词来描述接下来一年AGI历程里最关键的事情,我认为会是自进化。这个词虽然听起来有点玄幻,过去一年大家也多次提到,但我最近才对它有了更深的体会,也对如何具体落地这件事有了更务实可行的方案。
借助非常强大的模型,我们在过去chat范式下其实根本没有发挥出预训练模型的上限,而这个上限现在被agent框架激活了。我们现在触到了一个现象,当模型执行更长时间的任务时,它可以自己去学习和进化。一个很简单的尝试是,在现有的agent框架里叠加一个可以verify的条件约束,再设置一个loop,让模型持续迭代优化目标,我们就能发现模型会持续拿出更好的方案。这种自进化现在已经能跑一两天了,国内的模型基本上能支撑,当然和任务难度有关。我们发现在一些科学研究上,比如去探索更好的模型结构,因为有评估标准,比如更低的PPL,在这类目标明确的任务上,模型已经能自主运行和执行两三天了。
从我的角度看,自进化是唯一能创造出新东西的地方,它不是去替代我们人类现有的生产力,而是像顶尖科学家一样去探索这个世界上还没有的东西。一年前我会觉得这个时间历程需要三到五年,但就在最近,我觉得这个时间线应该缩短到一两年,大模型叠加一个非常强的自进化agent框架,至少能实现对科学研究的指数级加速。我们组内做大模型研究的同学,workflow高度不确定且需要大量创造力,但借助顶尖模型,基本上已经能把我们自己的研究效率加速近十倍了。我很期待这样的范式辐射到更广泛的学科和领域。
夏立雪 :我的关键词叫可持续token。我看到整个AI的发展仍然处于长期持续的过程中,我们也希望它能有长久的生命力。从基础设施的视角来看,我们面临的一个很大问题是资源终究是有限的,就像当年我们讲可持续发展一样。我们作为一个token工厂,能否给大家提供持续稳定、大规模可用的token,让顶尖的模型真正能够继续服务更多的下游,是我们看到的一个非常重要的问题。
所以我们现在需要把视角放宽到整个生态,从最早的能源到算力,再到token,最终转换成GDP,让这条链路能够进行持续的经济化迭代。我们不只是把国内的算力用起来,也在把这些能力输出到海外,让全球的资源能够打通整合。所以我认为可持续这个词,也包含了我们想把中国特色的token经济学做起来的愿望。过去那个时代叫Made in China,我们把低价的制造能力转化成好的商品输出到全球。现在我们想做的有点像AI Made in China,把中国在能源上的优势,通过token工厂可持续地转化为优质的token输出到全球,成为世界的token工厂。这是我希望在今年看到的,中国为世界人工智能带来的价值。
张鹏 :我就简短一点,大家都在仰望星空,我就落地一点。未来十二个月面临的最大问题,我觉得可能就是算力。刚才也说了,所有的技术,包括智能体框架,让很多人创造力爆发、效率提升十倍,但前提条件是大家用得起、用得起来。不能因为算力不够,一个问题提出去让它思考半天都得不到答案,这肯定不行。也正是因为这样的原因,我们很多研究进展和想要做的事情其实都受阻了。前两年记得中关村论坛有人提过这么一句话,叫没卡没感情,谈卡伤感情。今天又回到了这个处境,但情况又不一样了,我们现在转向推理阶段,是因为需求真的在爆发,十倍百倍地爆发。刚才也说到过去增长了十倍,背后其实是一百倍的需求,还有大量的需求没有被满足,这需要大家一起来想办法。
杨植麟(主持人):好,感谢各位的精彩分享,谢谢大家。
最后,这两天海淀五道口的AI原点社区也在举办原点Party Nights活动,有兴趣的可以去玩玩,说不定咱们还能一起面个基🫣。

中文


Anthropic刚推出了Claude认证架构师考试,免费。
很久没考试了,准备挑战一下,考试内容:
Agentic架构与多Agent编排(27%)
Claude Code配置与工作流(20%)
Prompt工程与结构化输出(20%)
工具设计与MCP集成(18%)
上下文管理与可靠性(15%)
不是入门科普,是生产级应用开发能力认证。
AI工具迭代太快,很多人看着别人在用Agent交付项目,自己还不知道从哪里开始。
这个认证是一个起点,而且是免费的。
报名:anthropic.com

中文


天涯神贴:社会的本质是什么?
1、当你有朝一日达到一定的社会地位后,便会明白一个道理:中国社会的内核,始终是“君子自强不息”。不论身处哪个阶层,即便拥有再优越的背景、出身、天赋或机遇,都必须始终保持积极向上的心态。唯此,才能承载得住命运所赋予的一切。
2、多读历史书(注意,并非中学课本那种)。已有之事,后必再有;已行之事,后必再行。日光之下,并无新事——这是所罗门王的智慧。
3、有钱时,无论做什么,旁人都觉得有模有样;贫穷时,即便做的是有价值之事,也常被视作无聊、幼稚甚至可笑。人性本“贱”,不经世事打磨,何以看透人间百态。我笑红尘,红尘亦笑我。
4、渴望被认可,就容易成为他人的奴隶。生活中,有一种简单却有效的驯服方式,就是指责或表现出厌恶。定力不足者,往往会第一时间反思自己哪里做错,并试图做得更多以讨好对方。实则一切都是徒劳——讨厌你的人,你做什么他都讨厌;欺负你的人,你做得再好他仍会欺负你。有时,你的存在本身便是“原罪”。因此,不必纠结。
5、务必记住:任何东西即将到手时,总会有人看你不顺眼。拿到第一名,便已得罪了许多人。最美的花最先被摘,最直的树最先被砍,最有才的人最先受挫,这是世间常态。所以,人上不傲,人下不卑,人前不炫,方为顶级的自律。可惜,多数人难以做到。
6、曾听过一个故事:一次搬家,朋友们都说要来帮忙。我盘算着请搬家公司要五百多,正好省下。可朋友们不专业,磕坏了价值五千多的沙发。我苦笑着说“没事”,最后还请八个人吃饭花了一千二,嘴上还豪爽道:“以后有事尽管说!”回家后越想越不对劲:原本五百能解决的事,最终修沙发、请客,反而多花了一千。不久,两个朋友找我借钱,一个说要结婚,一个说父母住院。人情债难还,借出去的钱也打了水漂。很喜欢一句话:任何事情都没有表面那么简单。免费的东西,往往最贵。
7、能跳至高维视角观察世界的人,往往在引领这个世界。所有的领袖与王者皆如此。高维的智慧,必定源于自身。人需在自己身上发现那个“可以为师”的我,从而自我引领。有人称之为“信仰”,有人称之为“高我”,也有人称之为“内在光明”或“以身合道”——合道,则万事可成。
8、观察身边真正的有钱人,会发现他们有一个共同特点:即便明知某人不行,也不提醒、不指点、不好为人师。哪怕自己的认知与经验远超对方,也不会轻易给出建议。为什么?因为任何指点、说教,都需要消耗能量。情商最低的行为,就是不停地讲道理。智者慎言,愚者才热衷于指点江山。能说服一个人的,从来不是道理,而是南墙;能点醒一个人的,从来不是说教,而是磨难。
9、我很喜欢一个词:不破不立。有些东西必须摧毁,必须放弃,才能迎来新生。无论是消耗你的人,令你恐惧焦虑的事,还是那个脆弱敏感的自己——只有打破它们,才能重获新生。人都害怕变动,包括曾经的我:怕未知的恐惧,怕陌生的环境,怕不认识的人。但现在我明白,变动才意味着进步。
10、真正高明之人,每逢挫折都能保持镇定。其秘诀在于:得意时不过早欢喜,失意时不急于下结论。因为局势每时每刻都在变化,且非人力所能完全操控,而是天道规律在背后运行。
11、事以密成,言以泄败。身弱之人尤其要注意(普通人也适用):自身能量不足,容易承受不住他人的嫉妒与非议,气场易受干扰。所以,决定要做的事,在做成之前,不要对任何人透露。
12、成人世界的第一项技能:藏话。想尽办法掩藏自己的真实信息,因为他人永远不缺乏整你的动机,只缺害你的手段。而了解你的详细信息,正是对付你的第一步——家住哪里、老家何处、父母职业、婚姻状况、学历经历、人脉圈子……有了这些,便能描画出你的社会肖像,计算整你的成本与收益,确定你在“背锅”序列中的位置。所以,若你有实力,尽量低调;若你势单力薄,则不妨虚实结合,真假难辨,以提高在成人世界生存的几率。
13、多想无益,拒绝内耗。身弱之人往往思虑过重、敏感多疑,做事容易瞻前顾后、犹豫不决,从而错过时机,导致一事无成。事情应从细微处着手,集中精力先做成一件,而非终日空想却无一落实。
14、不可有炫耀之心。身弱之人经不起炫耀,甚至承受不住过多赞誉。若因一时称赞而飘飘然,多半很快便会遭遇现实打击。如同某些一夜成名者,根基不稳,终难持久。人需沉得住气,不露锋芒,光而不耀,静水深流,抱朴守拙,方能行稳致远。
15、没有钱的时候,谈不上格局与理想。只有当收入提升,格局自然随之打开。做一个尊重市场规则、相信等价交换的人,才是务实之道。
16、看破不说破。正如那个偷电动车的小子所言:“里面的人个个说话都好听。”只因在里面,人们才敢讲真话。到了外面,没人会轻易吐露真言。聪明人都明白,讲真话容易惹祸,甚至可能连累家人。
17、原生家庭对一个人的影响,远比想象中深远。无论是性格塑造还是消费习惯,每个人身上都带着父母的影子——无论好坏。
中文

Obsidian 在 AI 时代成了我们的“第二大脑”,现在Obsidian CLI对所有人开放了。
只需要将Obsidian更新最新版,然后在设置中打开CLI页面。
AI 终于能真正理解你的知识结构、笔记间的关系、知识结构,而不只是读到一堆文本,这才真正发挥Obsidan的全部实力。
就比如,以前让 AI 分析我的知识库,它要打开每一个文件。上千个文件一个个读,token 烧得飞起,还只能看到纯文本。
现在用 CLI,查询用的是 Obsidian 预建的索引,速度比文件系统扫描快几十倍:
- obsidian orphans 找出所有孤岛笔记
- obsidian backlinks 看到谁链接了谁
- obsidian tags counts 统计标签使用频率
- obsidian search 全文搜索,0.3 秒出结果
Obsidian在 AI 时代的地位又一次稳固了,还没玩起来Obsidian的朋友也快用起来~
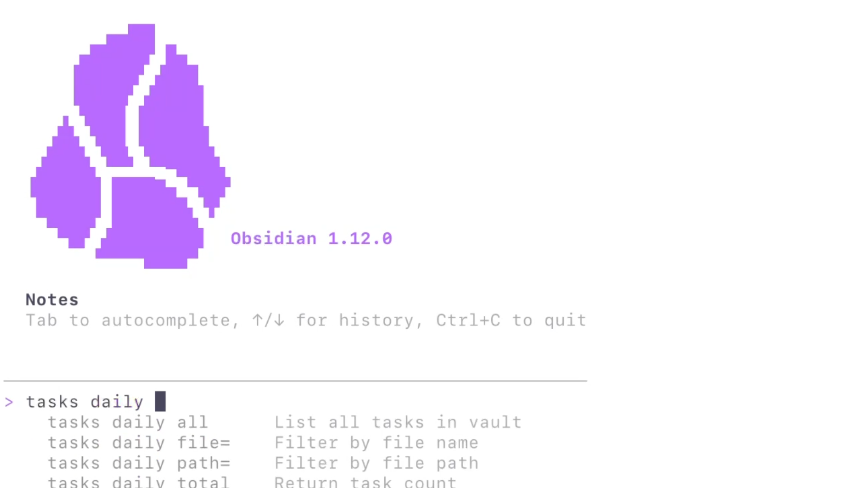
Obsidian@obsdmd
Obsidian 1.12 is now available to everyone! - Obsidian CLI - Bases search - Image resizing - Automatically clean up unused images - Better copy/paste into rich text apps like Google Docs - Native iOS share sheet
中文

Anthropic 研究人员刚刚证实,利用 AI 学习新技能会导致掌握程度下降 17%。但实际情况绝不是你想象的。
论文标题是《AI 如何影响技能养成》。这是一项随机实验,涉及 52 名专业开发人员。任务是使用他们从未接触过的 Python 库进行真实的编程。一半人配备了 AI 助手,另一半则没有。
AI 组在技能评估中的得分低了 17%。p 值为 0.010。所以这个差异是有统计学意义的。
更扎心的是:AI 组的速度甚至没有变得更快。他们学到的东西更少,而且并未节省时间。但是,如果你因此开始在网上传播“AI 不利于学习”这一论调,你就错失了论文中真正的重点。
研究人员查看了每一位参与者的屏幕录像。他们发现人们在学习新事物时使用 AI 的 6 种不同模式。其中 3 种模式有助于保持学习效果,另外 3 种则会破坏学习效果。两者之间的差距是巨大的。只向 AI 询问概念性问题的参与者,在评估中得分高达 86%。
而把一切都甩给 AI 的参与者,得分仅为 24%。
同样的工具,同样的任务,同样的时间限制。区别在于认知参与度。得分最高的 AI 用户实际上表现得比无 AI 组还要好。他们问的是“为什么这样行得通”,而不是“替我写这段代码”。他们生成代码后会追问以便理解。他们将 AI 视为思考伙伴,而非思考的替代品。
得分最低的一组做的是:粘贴提示词,复制输出结果,然后继续下一步。他们完成得最快。但他们几乎什么也没学到。
还有一个发现值得每一位工程经理的警惕:得分差距最大的是调试类问题。当你监管 AI 最需要的那项技能,恰恰也是当你让 AI 代劳时退化得最快的技能。
不用AI的对照组在任务执行过程中犯了更多错误。他们遇到了各种 bug。但这番挣扎,恰恰构建了他们的理解。错误并非学习的障碍。错误本身就是学习。用 AI 消除错误,也就消除了建立能力的机制。
AI 组的参与者在事后坦言,希望自己当时能“更用心一点”,并觉得自己的做法很“懒惰”。其中一人写道:“我的理解还有很多漏洞。” 他们能感受到那种完成了任务却不知其所以然的空虚感。这不是生产力的胜利,而是技术债。
这篇论文并非反对使用 AI,而是反对无意识地使用 AI。实际的结论很简单:如果你在学习新东西,请用 AI 来提问,而不是用它来逃避工作。
那份挣扎,才是成果所在。

中文


how to use obsidian + claude code to build a 24/7 personal operating system and build your startup:
1. write everything in markdown (daily notes, projects, beliefs, people, meetings)
2. link your notes together so they mirror how your brain actually thinks.
3. install obsidian cli so claude code can read your entire vault + the relationships.
4. stop reexplaining projects every session. use reference files instead.
5. build custom slash commands:
/context → load your full life + work state
/trace → see how an idea evolved over months
/connect → bridge two domains you’ve been circling
/ideas → generate startup ideas from your vault
/graduate → promote daily thoughts into real assets
6. keep a strict rule: human writes the vault. agents read it, suggest, execute.
7. let claude aka clode surface patterns you’ve been unconsciously circling for years.
8. delegate from inside your notes. one sentence in obsidian → agent handles the rest.
9. treat writing as leverage.the more you write, the more context your agents have.
10. understand this:markdown files are the oxygen of llms.
i really enjoyed seeing how to use obsidian thanks to @internetvin
vin uses ai like a thinking partner wired into his life’s work.
99.99% of people won’t do this because it requires reflection + setup.
but once the vault exists, the agent stops being generic.
it starts thinking in your voice.
episode is live on @startupideaspod (more there)
this one is different. send this tweet to a friend.
im still processing how game changer obsidian + claude code is, maybe you too
watch
English

42 万粉丝的 AI 创业者 Alex Finn 提炼了 11 条使用 OpenClaw 的干货建议,看完才知道自己用错了。
大部分人拿到 OpenClaw 就当高级 ChatGPT 用,只用到 了它 1% 的价值。
以下是他浓缩总结了 11 个让 OpenClaw 从「没用」变成「AGI」的实战技巧:
1. 用 Opus 做大脑,不同模型做不同的肌肉
Codex 写代码,Minimax 2.5 做研究,Qwen 3.5 搞创意。省钱,还能并行处理,速度翻倍。
就像公司里不同岗位用不同的人,写代码找程序员,做研究找分析师。
OpenClaw 可以同时调用多个模型,各司其职,效率更高。
2. 部署在本地设备,别用 VPS
这就类比与员工在你办公室工作和在地球另一端工作的区别。
本地部署可以快速 AirDrop 文件,自动化工作流更高效。
最大的好处是你可以直接访问你电脑上的文件。比如你手机拍了张照片,AirDrop 到电脑,OpenClaw 立刻就能处理,不用上传下载。
3. 快速消息用 Telegram,深度工作用 Discord
Telegram 最快,Discord 可以设置多频道工作流,让 agent 在不同频道启动 subagent,效率翻倍。
Telegram 其实就像发短信,随时随地可以快速沟通。
而 Discord 就像个工作室,可以开多个房间,让不同的 AI 助手在不同房间同时干活。
4. 反向提示
别告诉它做什么,问它应该做什么。
比如:「根据你对我和我目标的了解,下一步最好做什么?」效果会好很多。
传统方式是你下命令,AI 执行。
反向提示是让 AI 主动思考,给你建议。
就像问顾问「你觉得我该怎么做」,比直接说「帮我做这个」效果好得多。
5. 用 OpenClaw 来 vibe code
不直接用 Codex 或 Claude Code,而是告诉 OpenClaw 要构建什么,让它自己用 Codex CLI 去 vibe code。
你只需要说「我要做个博客网站」,OpenClaw 会自己调用 Codex 写代码、调试、部署。
你不用管技术细节,只管提需求。
6. 构建你自己的任务控制中心
用 NextJS 搭建一个 Mission Control,让 OpenClaw 构建 3 个它认为能改善工作流的工具。
这就好比你给你自己搭了个工具箱,把常用的功能都放进去,比如一键生成周报、自动整理笔记、批量处理图片。
7. 电脑上做的每件事,都先问问 OpenClaw
写文档、构建项目,先问它怎么做更好,这是最好的练习。
养成习惯,做任何事之前先问一句「有没有更快的方法」。
很多时候你手动要做 1 小时的事,OpenClaw 可能 5 分钟就搞定。
8. 从便宜的旧笔记本开始
不用一开始就投入太多,先用手头的设备试试,等摸清高级工作流再升级硬件。
别被硬件劝退。
家里吃灰的旧电脑就能跑 OpenClaw,先玩起来,确定有用再考虑升级。
9. 别给它邮箱访问权限
这是一个很大的提示注入攻击向量。
邮件里可能有恶意内容,骗 OpenClaw 执行危险操作。
就像不要随便点陌生人发的链接一样。
10. 别给它独立的 X 账号
X 正在严厉打击机器人,连 API 使用都在限制。
X 现在对机器人管得很严,给 OpenClaw 开账号容易被封。
需要发推的话,让它帮你写好内容,你自己发。
11. 享受乐趣,大胆实验
别管那些说「没人靠这个赚钱」的人。
玩转这个时代最伟大的技术,本身就是一种享受。
学新技术不一定要马上变现。
就像小时候玩电脑,先享受折腾的过程,能力提升了,机会自然会来。
Alex Finn@AlexFinn
中文

我花了一周时间,把主流AI的Pro版全买了一遍,说说我的真实感受。
1. Gemini:图片处理和网络信息整合最强,Deep Research比其他家都好用,配合Google Drive几乎无缝
2. Claude:Cowork功能让AI真正变成了"代理"而不是聊天机器人,我用它拉财务数据、做Excel预测模型,效率很高
3. Grok:实时数据和新闻是它的护城河,能直接调用X上的帖子作为信息源,这个差异化很难被复制
4. ChatGPT:记忆功能是目前最好的,它会记住你说过的事,下次对话直接接上,聊起来最像真人,但很遗憾这玩意我不可能继续
没有一个全能冠军,选哪个取决于你主要用来干什么。但是事实上,除了ChatGPT剩下三个都是我的主力
中文
