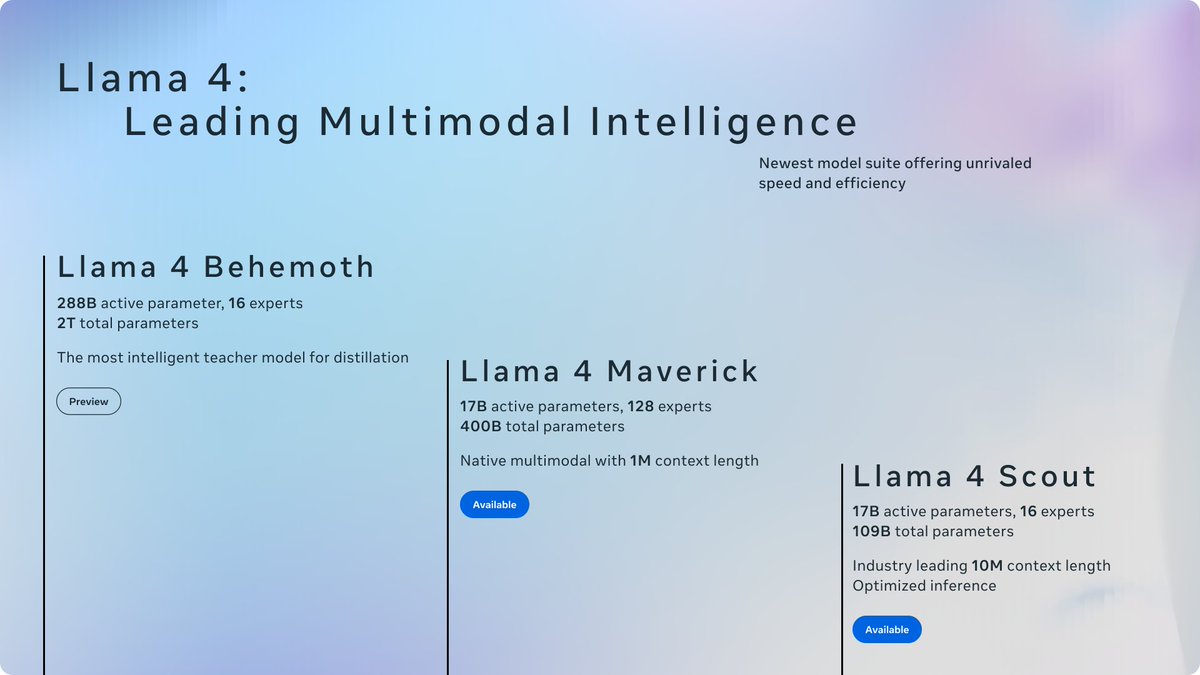
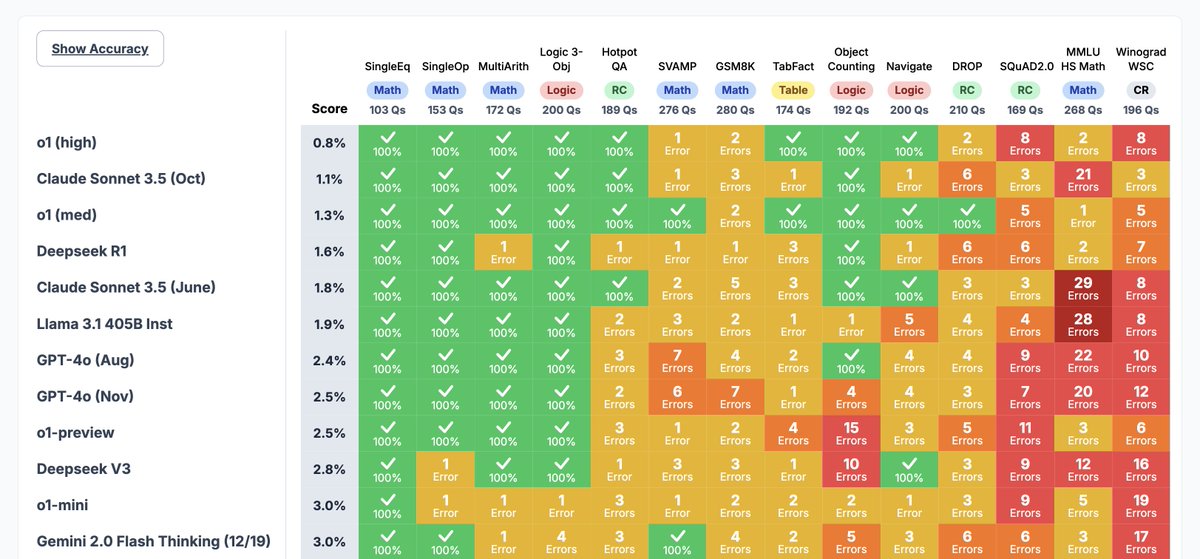
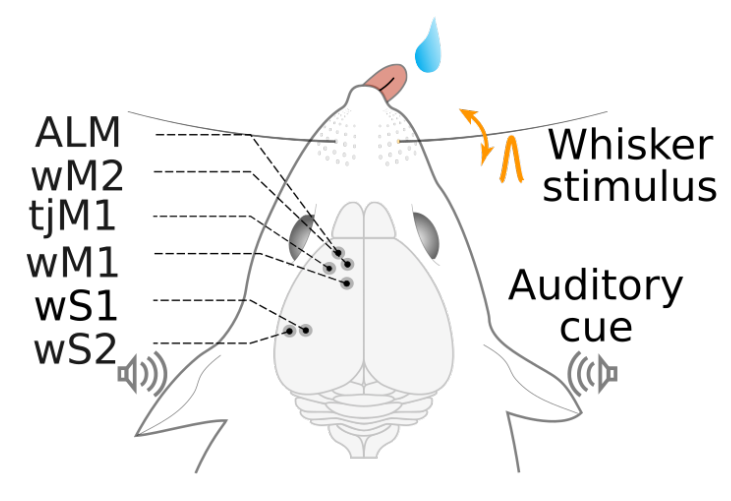
David Liu retweetledi

🚨 MIT just humiliated every major AI lab and nobody’s talking about it.
They built a new benchmark called WorldTest to see if AI actually understands the world… and the results are brutal.
Even the biggest models Claude, Gemini 2.5 Pro, OpenAI o3 got crushed by humans.
Here’s what makes it different:
WorldTest doesn’t check how well an AI predicts the next word or frame.
It measures if it can build an internal model of reality and use that to handle new situations.
They built AutumnBench 43 interactive worlds, 129 tasks where AIs must:
• Predict hidden parts of the world (masked-frame prediction)
• Plan multi-step actions to reach goals
• Detect when the rules of the environment suddenly change
Then they tested 517 humans vs the top models.
Humans dominated every category.
Even massive compute scaling barely helped.
The takeaway is wild:
Today’s AIs don’t understand environments they just pattern-match inside them. They don’t explore, revise beliefs, or experiment like humans do.
WorldTest might be the first benchmark that actually measures understanding, not memorization. And the gap it reveals isn’t small it’s the next grand challenge in AI cognition.
(Comment “Send” and I’ll DM you the paper 👇)

English