Sabitlenmiş Tweet

.@cursor_ai giving you grief? Billing confusion? Bugs being buggy? Need something explained?
Just @ me or drop a DM - I got you 🤝
English
Dean Rie /raɪ/
19.8K posts

@dean_rie
fullstack developer & designer @cursor_ai




was messing with the OpenAI base URL in Cursor and caught this accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast so composer 2 is just Kimi K2.5 with RL at least rename the model ID


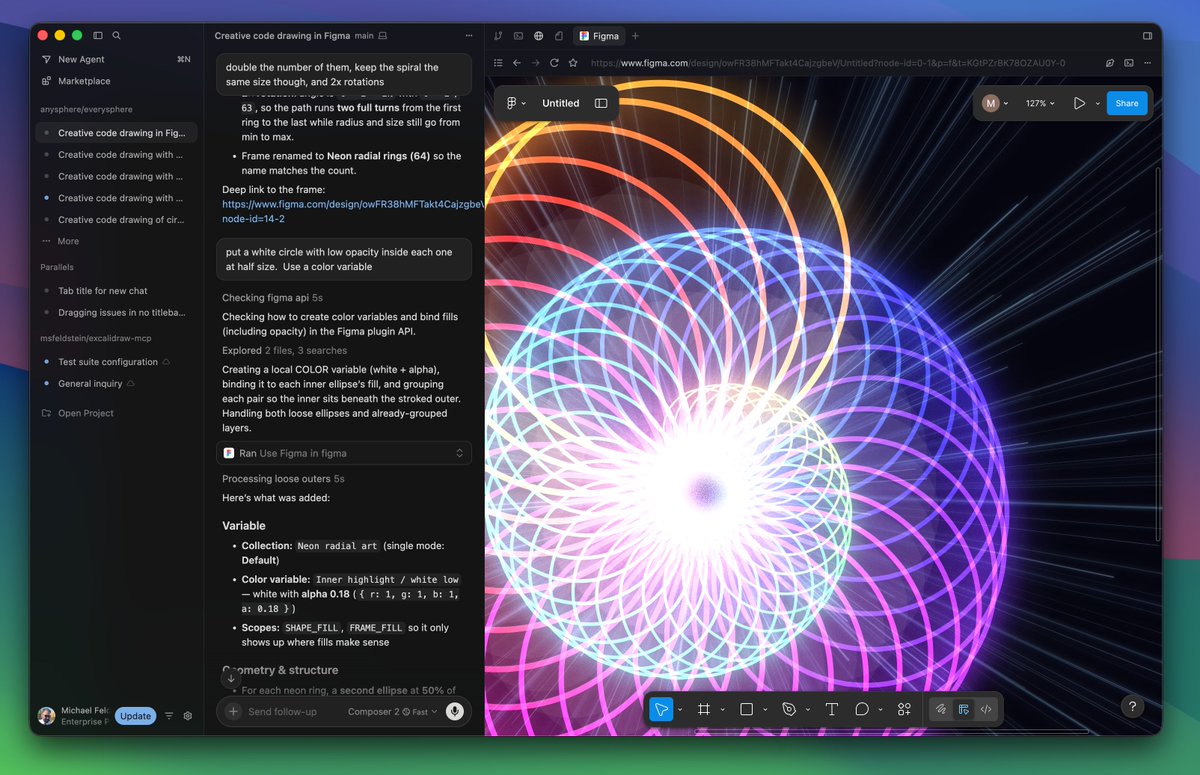
Agents, meet the Figma canvas




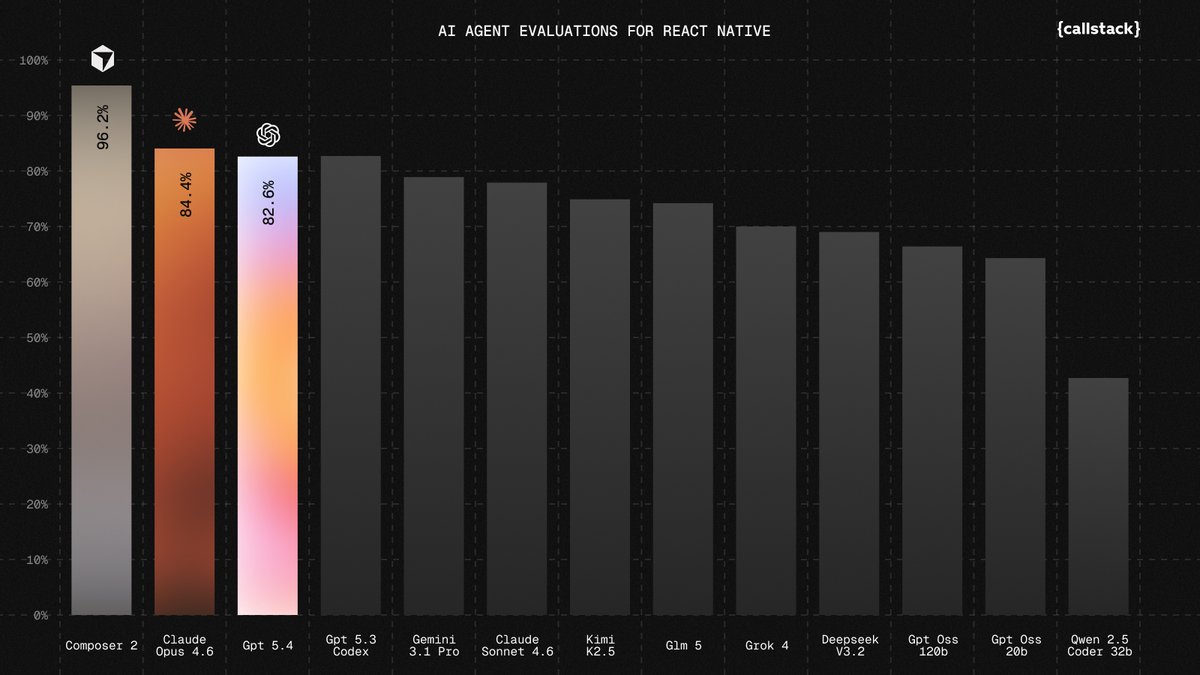

Agents, meet the Figma canvas
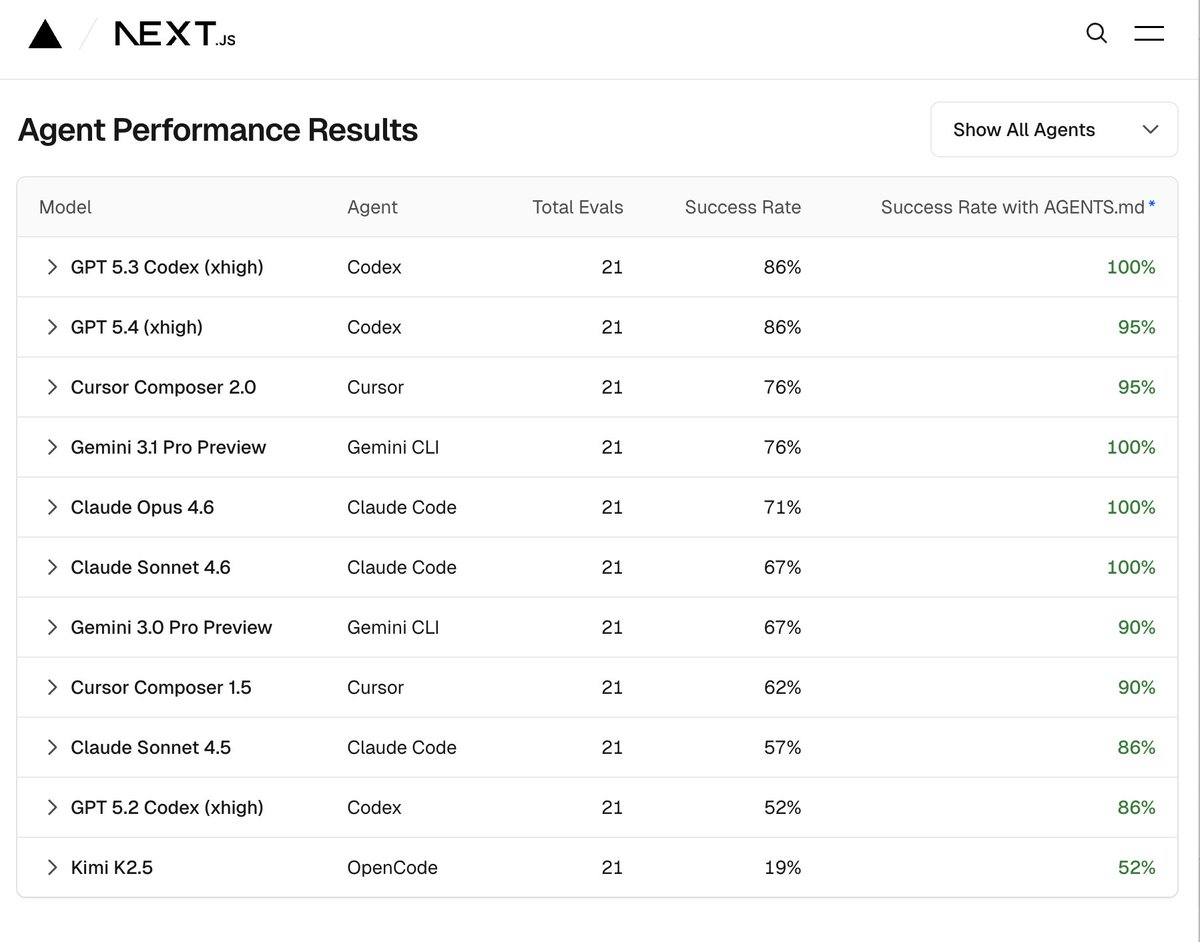
Cursor can now search millions of files and find results in milliseconds. This dramatically speeds up how fast agents complete tasks. We're sharing how we built Instant Grep, including the algorithms and tradeoffs behind the design.




