@GlobalDiss What the fuck is happening to Europe. They’re focusing on non existing problems but continue to ignore actual problems that are killing the west.
English
pack
303 posts






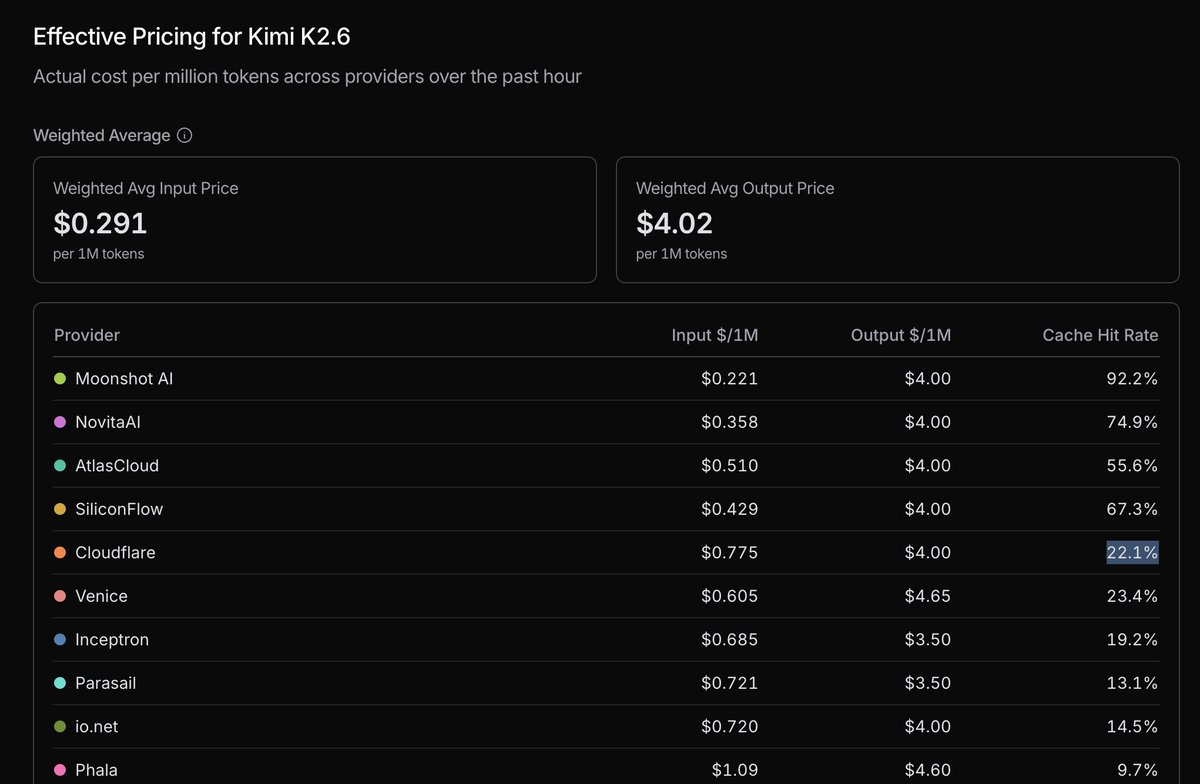
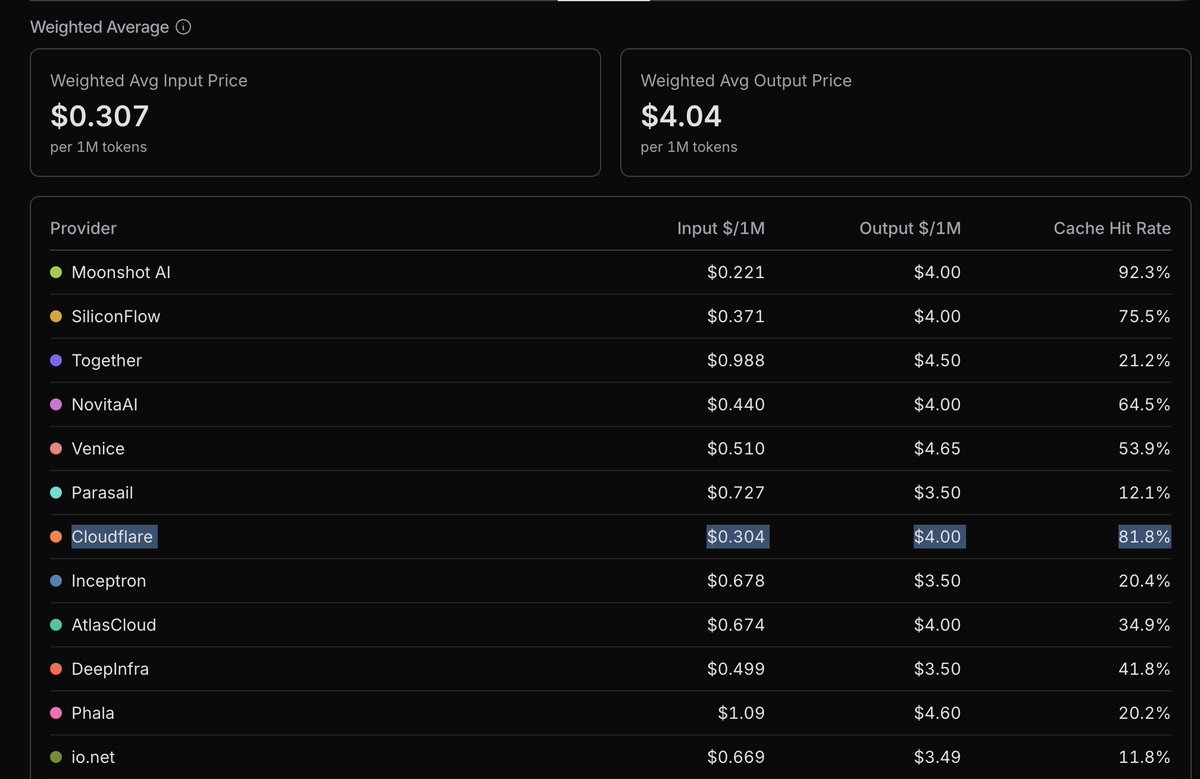
Yesterday Workers AI rolled out two major changes for Kimi k2.6: speculative decoding and shared KV cache. The first should improve TPS, especially for predictable output like tool calls. The second should improve cache hit rates, lowering TTFT and blended cost.



Folks, if you are mad about LLM providers' subscription policies, there's a simple answer: Use a third-party harness that lets you switch providers at will, and pay usage-based API price. No subscriptions. It might be more expensive for now, *if* you choose a frontier model for every task. But the easy switching means you can choose cheaper models (like Kimi or GLM, which are getting pretty good!) for a lot of things. And in the long run, API pricing will be driven down by competition. This is what the LLM providers really don't want, but the rest of us should all want. If we don't want all the value created by LLMs to be captured by the LLM providers -- if we want the value spread across the economy -- then we need to make sure they are in perfect competition. Bonus: No stressing about running out of quota (nor failing to use up quota before it resets). You get exactly the tokens you need.

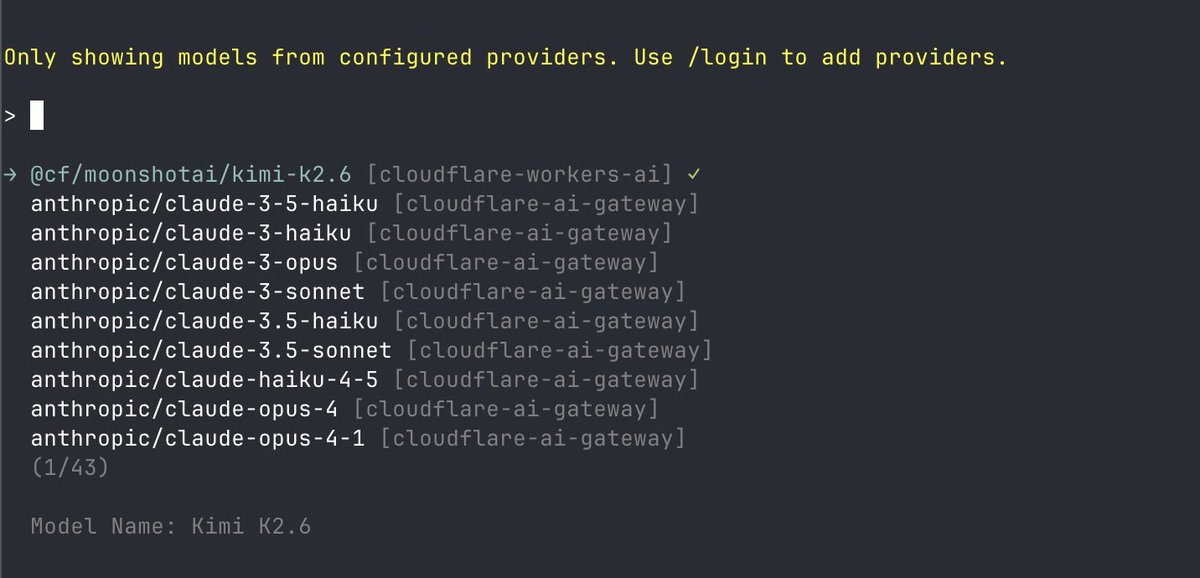
Pi v0.70.6 is out. Highlights: - Cloudflare Workers AI added as a built-in provider; configure with CLOUDFLARE_API_KEY and CLOUDFLARE_ACCOUNT_ID - Exported HTML now escapes embedded image data and session metadata, preventing markup injection from crafted session content Complete details in thread ↓