Dave/Ben
Yes, the way that Agentic AI is being architected at the moment would lead to more CPUs. And that is not the worst aspect by far. In my analysis below I suggest that NVIDIA and the leading Frontier models will provide the capabilities and architectures to manage this and many other Agentic issues within the Frontier models and Nvidia CUDA extensions to move appropriate parts of the orchestration from CPU to GPU & DPU. This will allow Frontier models to drive Agentic AI faster. It will also allow NVIDA to lower costs, increase TAM with more directly attached Arm & probably the joint Nvidia/Intel CPUs, and provide enterprises with a cheaper, more resilient, better compliant, and lower latency solution. Win, Win, Win.
Below is my earlier posting, which addresses part of where Agentic AI has to go.
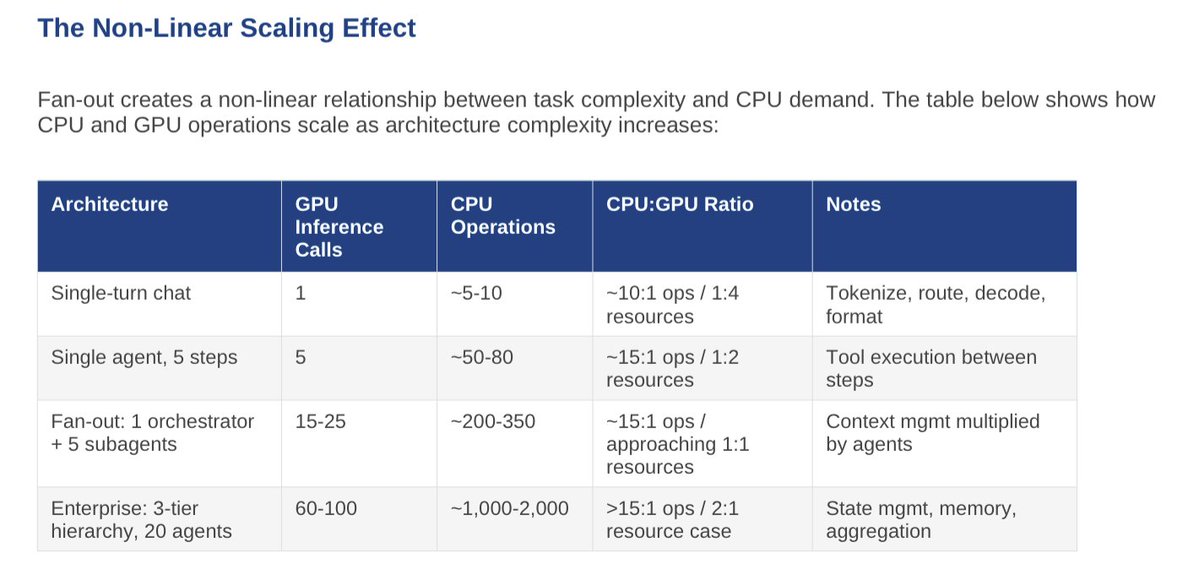
Great chart. The risk it highlights is real: fan-out multiplies coordination burden. If that coordination occurs on a loosely coupled CPU infrastructure, the system spends more time moving state and synchronizing agents than reasoning. Latency goes to hell in a hand-basket.
However, that outcome assumes the agent control plane lives outside the AI infrastructure. NVIDIA's direction is the opposite: keep the coordination layer within the AI-factory fabric itself.
Grace Arm CPUs today and Vera and Nvidia/Intel in the future sit in the same racks and on the same high-bandwidth fabric as the GPUs. They provide a local control plane for orchestration, data preparation, and agent coordination. With CUDA, NVLink/NVSwitch, and GPU-aware cluster schedulers, multi-agent execution can be treated as a native workload rather than a distributed application that calls models via APIs.
At the same time, a growing portion of the infrastructure overhead moves off CPUs entirely. BlueField DPUs already offload networking, storage protocols, security enforcement, and telemetry. That removes a large fraction of the “CPU operations” your chart assumes.
A second shift is architectural: many multi-agent patterns are really parallel reasoning branches followed by aggregation. When those branches run within the inference fabric rather than as separate CPU agents, coordination costs drop dramatically.
In my work, I call this integrated layer the Cognitive Surface, where agents, models, enterprise semantic and causal data, and governance run within the same AI-factory environment. Under that model, the CPU layer remains important for orchestration, but the dominant resource remains the GPU fabric where reasoning is produced.
Over time, the CPU/GPU ratio is more likely to fall than rise.
English