Sudo su@sudoingX
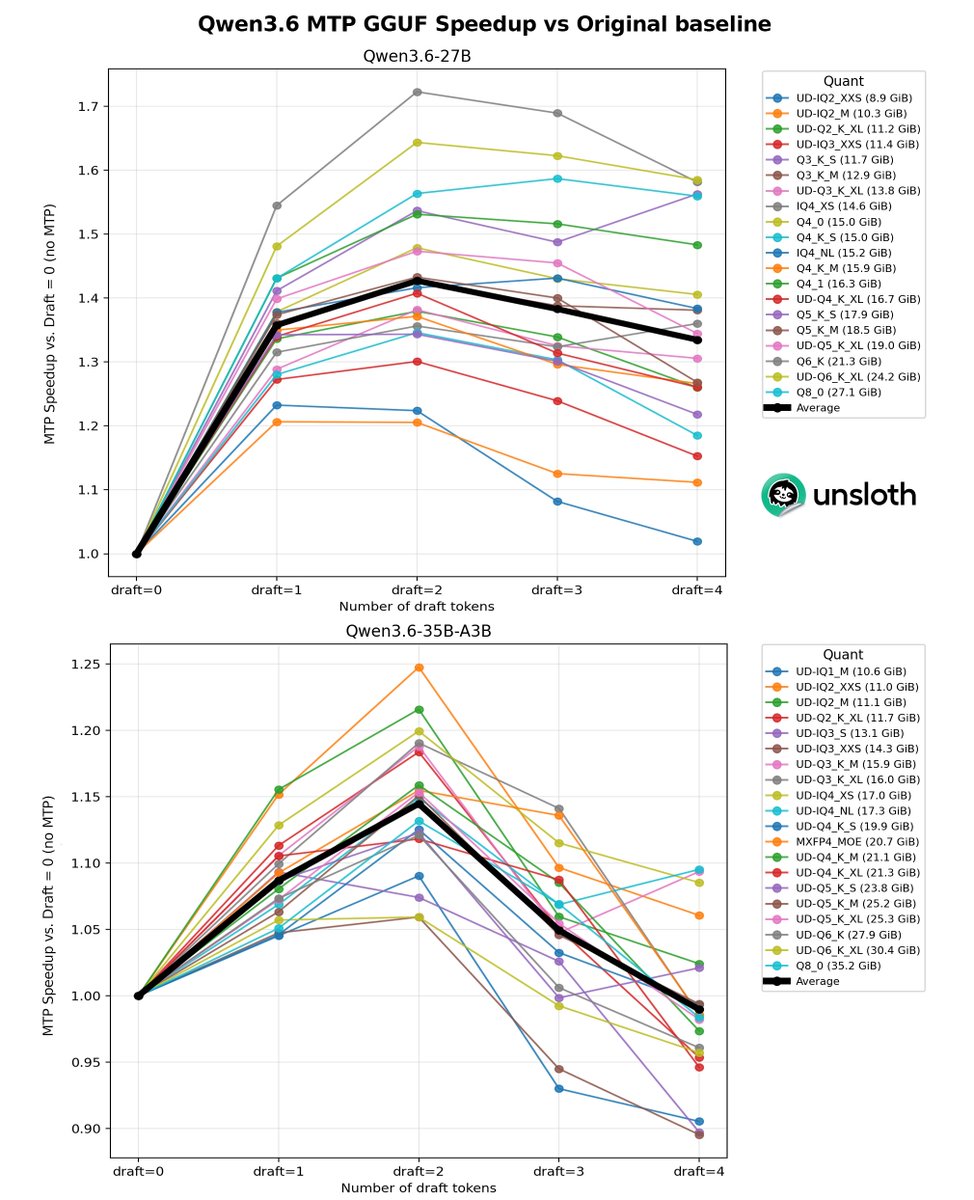
update: qwen 3.6 27b dense q4 just one shotted octopus invaders game on a single 3090. hermes agent drove the whole thing, ~41 tok/s gen 21gb vram at full 262k context, thinking mode on.
one prompt in and the canonical multi-file space shooter benchmark out, the same exact prompt i ran on qwen 3.5 27b dense back in march on the same card.
3.5 needed one external scope bug fix before the game would even load on first play. 3.6 needed nothing. 11 of 11 files written, 2411 lines of code, zero steering interventions, zero external fixes, playable on first load. 16 minutes 41 seconds wall clock from prompt to playable.
consumer tier king on a single 3090 is locked tonight, and the silicon underneath my desk did not change between march and now. the open source ecosystem just moved the floor.
watch it ship itself, the full 16 minutes 41 seconds sped to 3 minutes 45, no human touched the keyboard between the first prompt and the final frame.