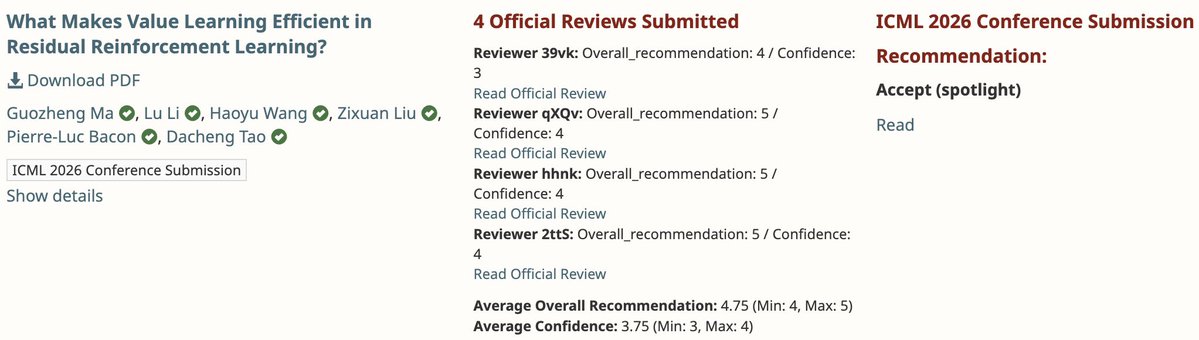
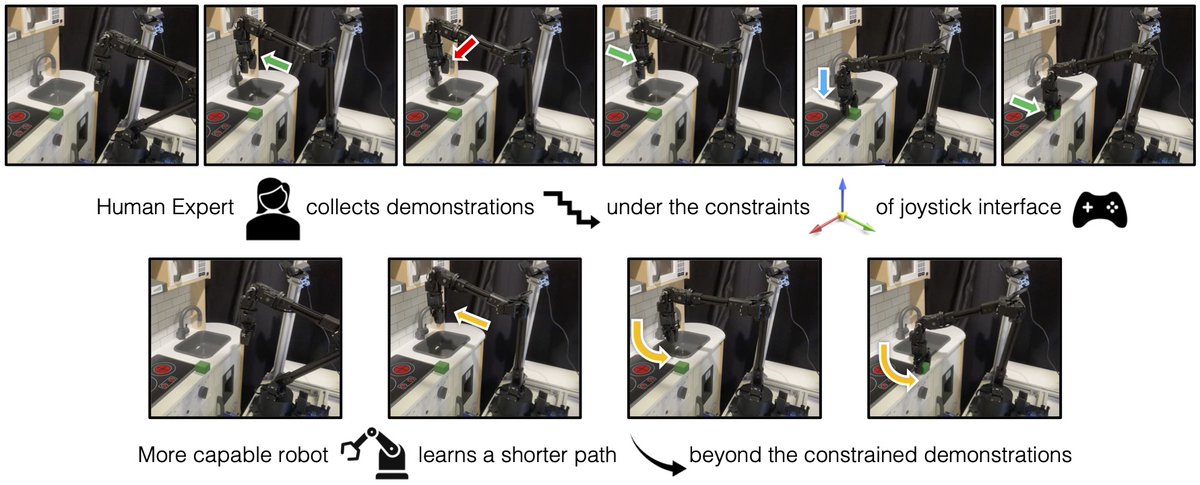
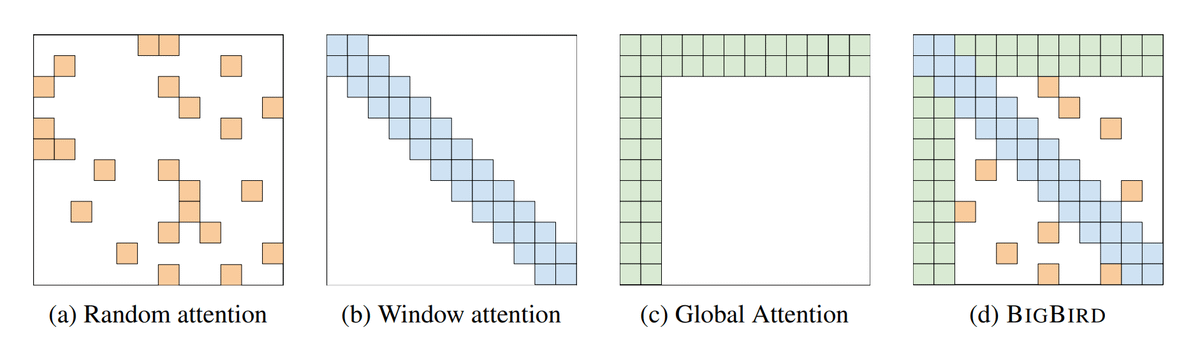
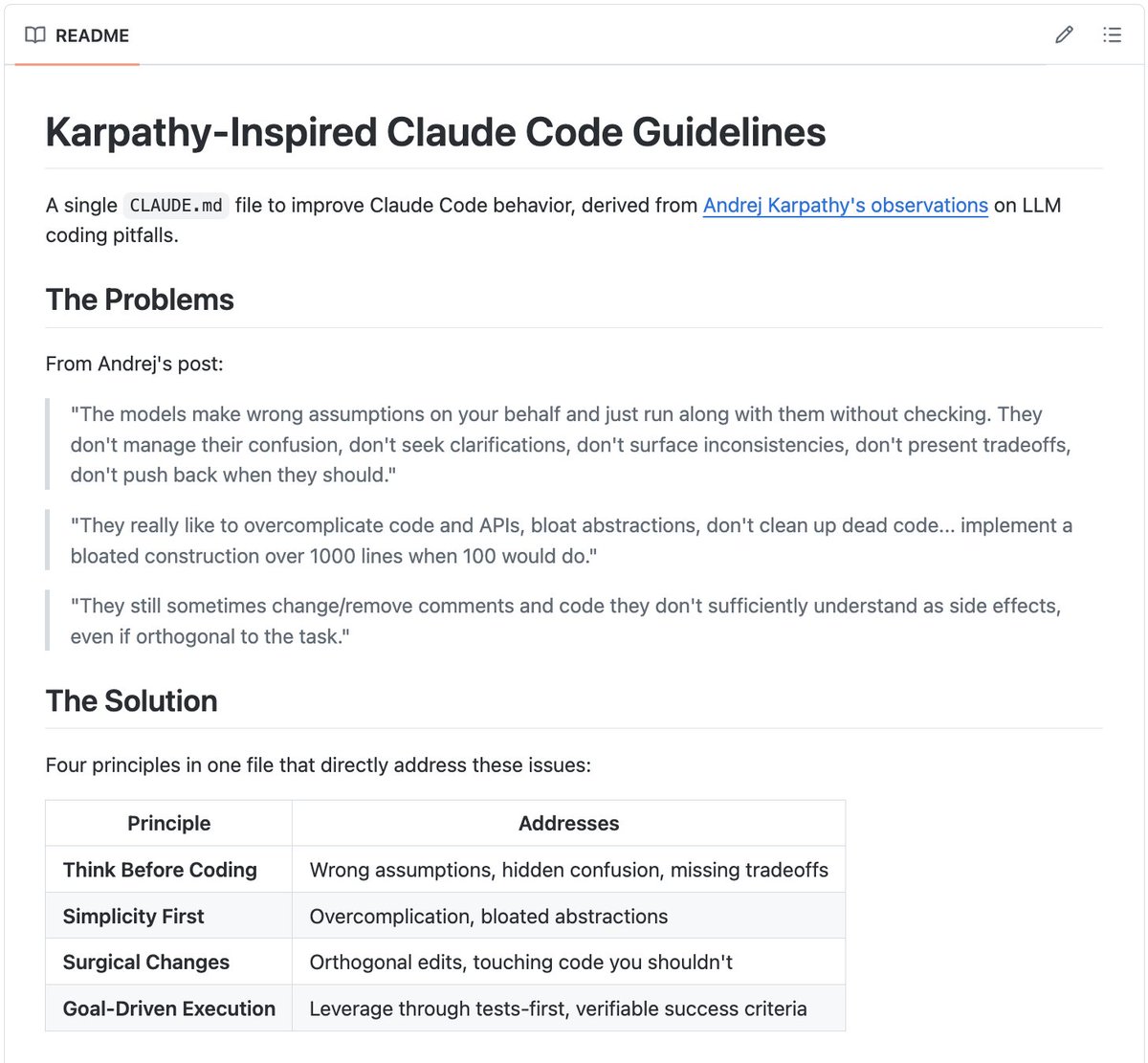
Sabitlenmiş Tweet

👐How can we leverage multi-source human motion data, transform it into robot-feasible behaviors, and deploy it across diverse scenarios?
👤🤖Introduce 𝐇𝐄𝐑𝐌𝐄𝐒: a versatile human-to-robot embodied learning framework tailored for mobile bimanual dexterous manipulation.
English