@DejounteMurray Hey man would love to dm u, I dmed on instagram too 🙏🏽
English
ryan mathieu
258 posts

@gapDEEPry
kernel guy. || Fast vs Slow Thinking



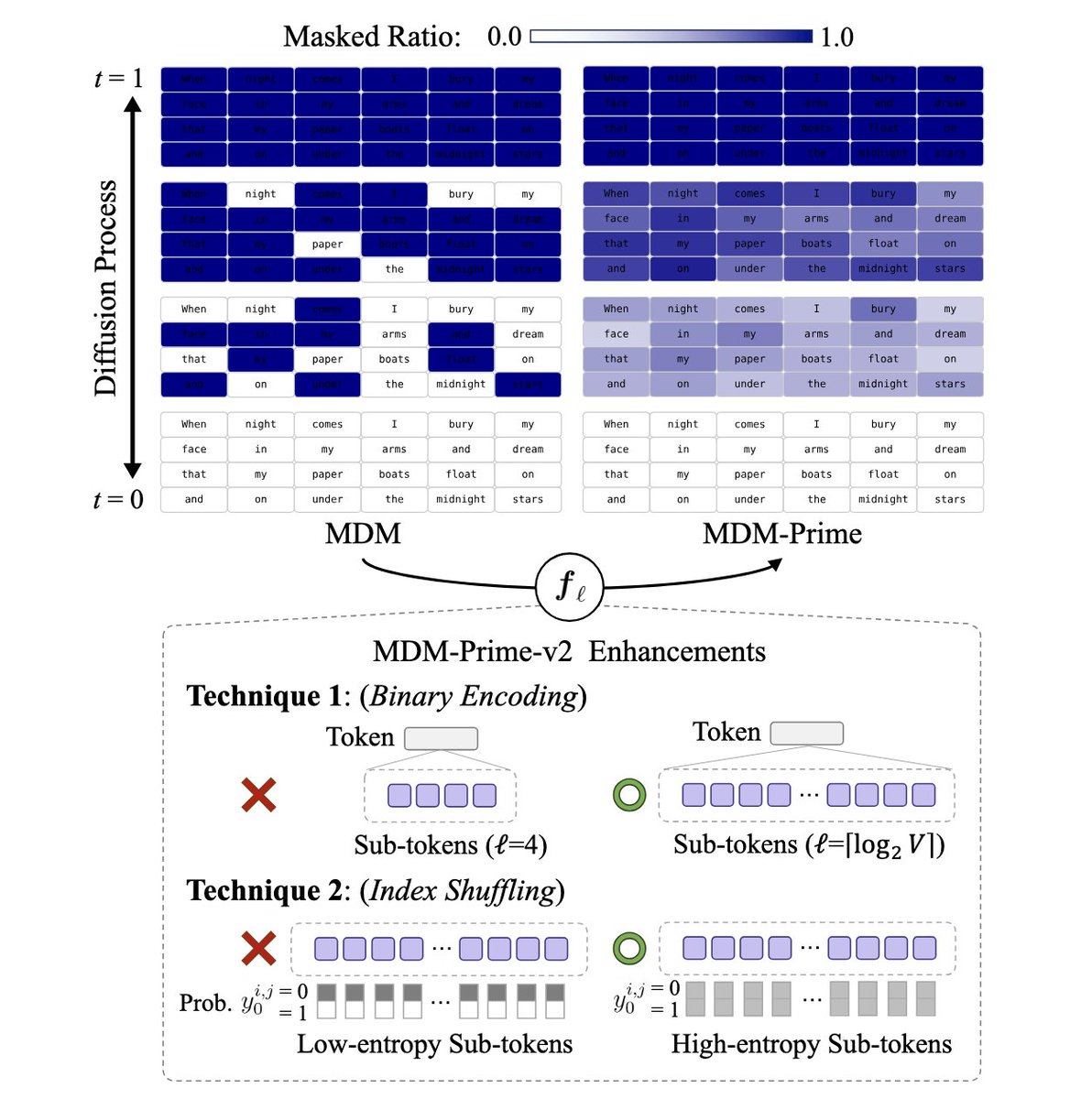

HUGE if true. If true, this is probably a larger efficiency gain than ALL publicly available techniques since DeepSeekMoE(Jan 2024) COMBINED. And it can just win modded-nanogpt speedrun. (1e18 is 250s@50%MFU, but the loss is significantly lower than 3.28) cc @classiclarryd

(2/7) 💵 With training costs exceeding $100M for GPT-4, efficient alternatives matter. We show that diffusion LMs unlock a new paradigm for compute-optimal language pre-training.

Introducing Mixedbread Wholembed v3, our new SOTA retrieval model across all modalities and 100+ languages. Wholembed v3 brings best-in-class search to text, audio, images, PDFs, videos... You can now get the best retrieval performance on your data, no matter its format.


Sources: Cursor is in early talks to raise billions in a new funding round at a post-money valuation of up to $60B; one source puts the round size at $5B (@cityofthetown / Newcomer) newcomer.co/p/cursor-weigh… #a260311p57" target="_blank" rel="nofollow noopener">techmeme.com/260311/p57#a26…
📥 Send tips! techmeme.com/contact


@thsottiaux Intel Mac support for the codex app…