
Paco Guzmán
410 posts

Paco Guzmán
@guzmanhe
Researcher in Language Technologies
San Francisco, CA Katılım Mart 2009
168 Takip Edilen343 Takipçiler

.@CleanlabAI has just been acquired by @joinHandshake!
This “recruiting marketplace” has silently grown in just 1 year to be a dominant player in human data for AI.
With Cleanlab's deep roots in research, Handshake is doubling down on building out its AI research org to strengthen the data foundations for frontier AI.
English
English

News: @CleanlabAI has been acquired by @joinHandshake!!
We're excited to ensure frontier AI systems are trained on the highest-quality data, accelerating our mission toward AI that's actually reliable. Data is only good as the experts producing it and the best work at Handshake

English
Super excited to welcome @CleanlabAI, led by @cgnorthcutt, @jomulr, and @anishathalye, to Handshake AI.
Their work has shaped how we think about data quality, reliability, and evaluation. Together, we’re advancing research in RL environments, evals, and human data to build the foundations of trustworthy AI.
techcrunch.com/2026/01/28/ai-…
English

This release represents a huge team effort. So proud of this team! It's a joy to work alongside such brilliant people, and I can't wait to see how the research community uses @TranslateGemma in the future!
#AI #Gemma3
Google AI Developers@googleaidevs
🗣 Introducing TranslateGemma, our new collection of open translation models built on Gemma 3. The model is available in 4B, 12B, and 27B parameter sizes, and furthers communication across languages, no matter what device you own. blog.google/innovation-and…
English
As AI accelerates, it’s worth taking time to ask what’s actually shaping these systems.
The new Handshake Research Hub brings together research and essays that explore how human expertise drives progress in AI, examining how we measure human input, codify expertise, and align AI with human judgment.
Explore the work joinhandshake.com/research/
English
I’m now part of the NAACL board
NAACL@naacl
Happy new year #NAACL! The 2026 election results are here. Congrats🥳 Chair: Anna Rumshisky @arumshisky Secretary: Jessy Li @jessyjli Board members: Muhao Chen @muhao_chen, Francisco (Paco) Guzmán, Ana Marasović @anmarasovic naacl.org/posts/2025-12-… Thank you all for voting!
English

Hallelujah!
I’m excited to share that I’ve been selected as a 2025 AI2050 Early Career Fellow by @Schmidtsciences
This year’s fellows represent 42 institutions across eight countries, working to ensure AI benefits humankind.
Learn more at: lnkd.in/eZA5FHci
Schmidt Sciences@schmidtsciences
We're excited to welcome 28 new AI2050 Fellows! This 4th cohort of researchers are pursuing projects that include building AI scientists, designing trustworthy models, and improving biological and medical research, among other areas. buff.ly/riGLyyj
English
Paco Guzmán retweetledi

🚀 GPT‑5 is here: deep reasoning + lightning speed. The leap toward AGI just got real.
Recap + takeaways in thread.
English
Paco Guzmán retweetledi

Paco Guzmán retweetledi

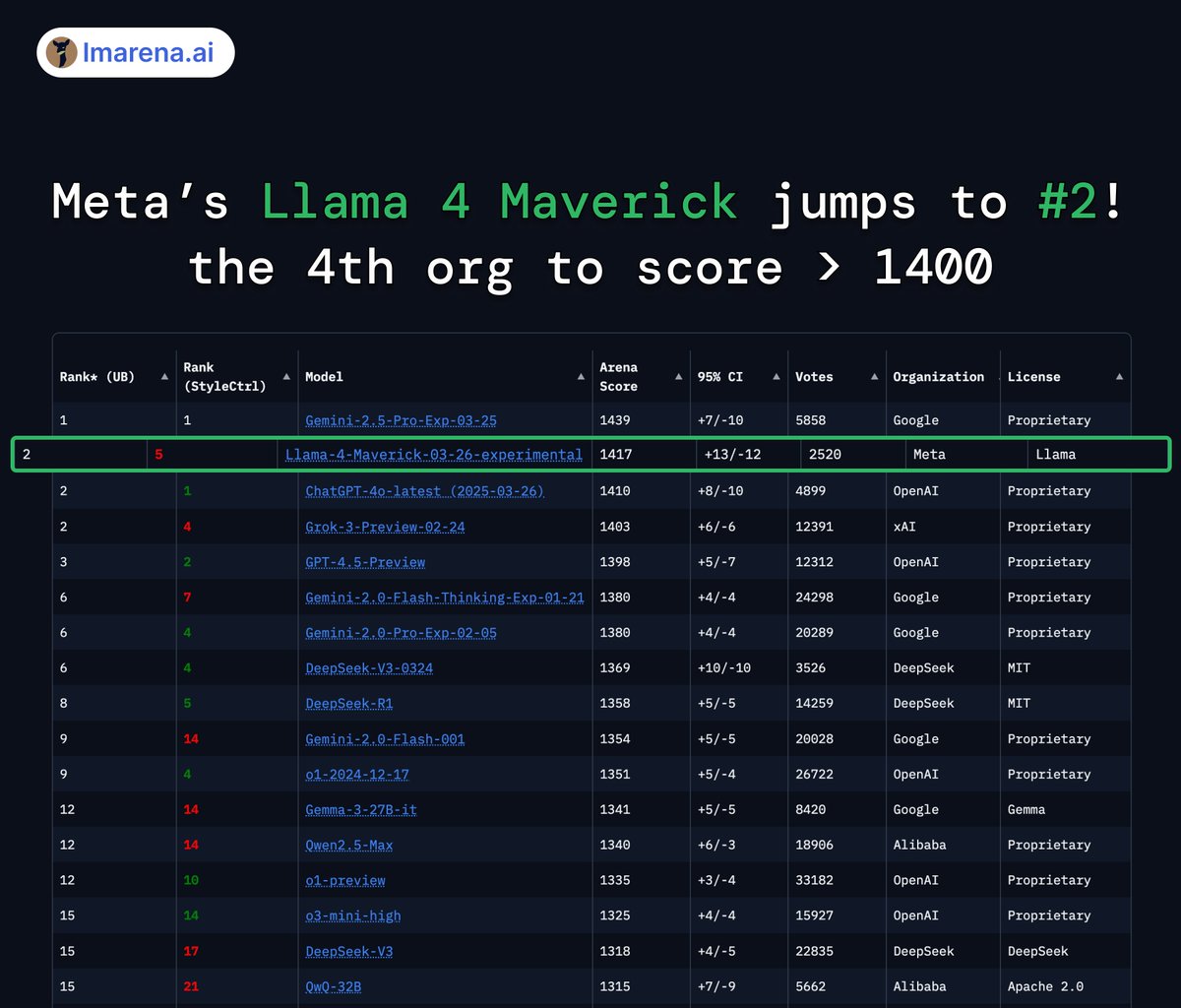
BREAKING: Meta's Llama 4 Maverick just hit #2 overall - becoming the 4th org to break 1400+ on Arena!🔥
Highlights:
- #1 open model, surpassing DeepSeek
- Tied #1 in Hard Prompts, Coding, Math, Creative Writing
- Huge leap over Llama 3 405B: 1268 → 1417
- #5 under style control
Huge congrats to @AIatMeta — and another big win for open-source! 👏 More analysis below⬇️
AI at Meta@AIatMeta
Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout • 17B-active-parameter model with 16 experts. • Industry-leading context window of 10M tokens. • Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks. Llama 4 Maverick • 17B-active-parameter model with 128 experts. • Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image. • Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks. • Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters. • Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena. These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight. Read more about the first Llama 4 models, including training and benchmarks ➡️ go.fb.me/gmjohs Download Llama 4 ➡️ go.fb.me/bwwhe9
English
Paco Guzmán retweetledi

Introducing our first set of Llama 4 models!
We’ve been hard at work doing a complete re-design of the Llama series. I’m so excited to share it with the world today and mark another major milestone for the Llama herd as we release the *first* open source models in the Llama 4 collection 🦙. Here are some highlights:
📌 The Llama series have been re-designed to use state of the art mixture-of-experts (MoE) architecture and natively trained with multimodality. We’re dropping Llama 4 Scout & Llama 4 Maverick, and previewing Llama 4 Behemoth.
📌 Llama 4 Scout is highest performing small model with 17B activated parameters with 16 experts. It’s crazy fast, natively multimodal, and very smart. It achieves an industry leading 10M+ token context window and can also run on a single GPU!
📌 Llama 4 Maverick is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding – at less than half the active parameters. It offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena. It can also run on a single host!
📌 Previewing Llama 4 Behemoth, our most powerful model yet and among the world’s smartest LLMs. Llama 4 Behemoth outperforms GPT4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks. Llama 4 Behemoth is still training, and we’re excited to share more details about it even while it’s still in flight.
A big thanks to all of our launch partners (full list in blog) for helping us bring Llama 4 to developers everywhere including @huggingface, @togethercompute, @SnowflakeDB, @ollama, @databricks and many others👏 This is just the start, we have more models coming and the team is really cooking – look out for Llama 4 Reasoning 😉
A few weeks ago, we celebrated Llama being downloaded over 1 billion times. Llama 4 demonstrates our long-term commitment to open source AI, the entire open source AI community, and our unwavering belief that open systems will produce the best small, mid-size and soon frontier models. Llama would be nothing without the global open source AI community & we are so ready to begin this next chapter with you. 🦙
Read more about the release here: llama.com, and try it in our products today.

English
Paco Guzmán retweetledi

🦙 Excited to release LLAMA-3.3! 405B performance at 70B. Check it out !!
Ahmad Al-Dahle@Ahmad_Al_Dahle
Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques including online preference optimization, this model improves core performance at a significantly lower cost, making it even more accessible to the entire open source community 🔥 huggingface.co/meta-llama/Lla…
English
@ArmenAgha Congratulations Armen! Looking forward to what you build
English

Say hello to our new company Perceptron AI.
Foundation models transformed the digital realm, now it’s time for the physical world. We’re building the first foundational models designed for real-time, multi-modal intelligence across the real world.
perceptron.inc
English
Paco Guzmán retweetledi

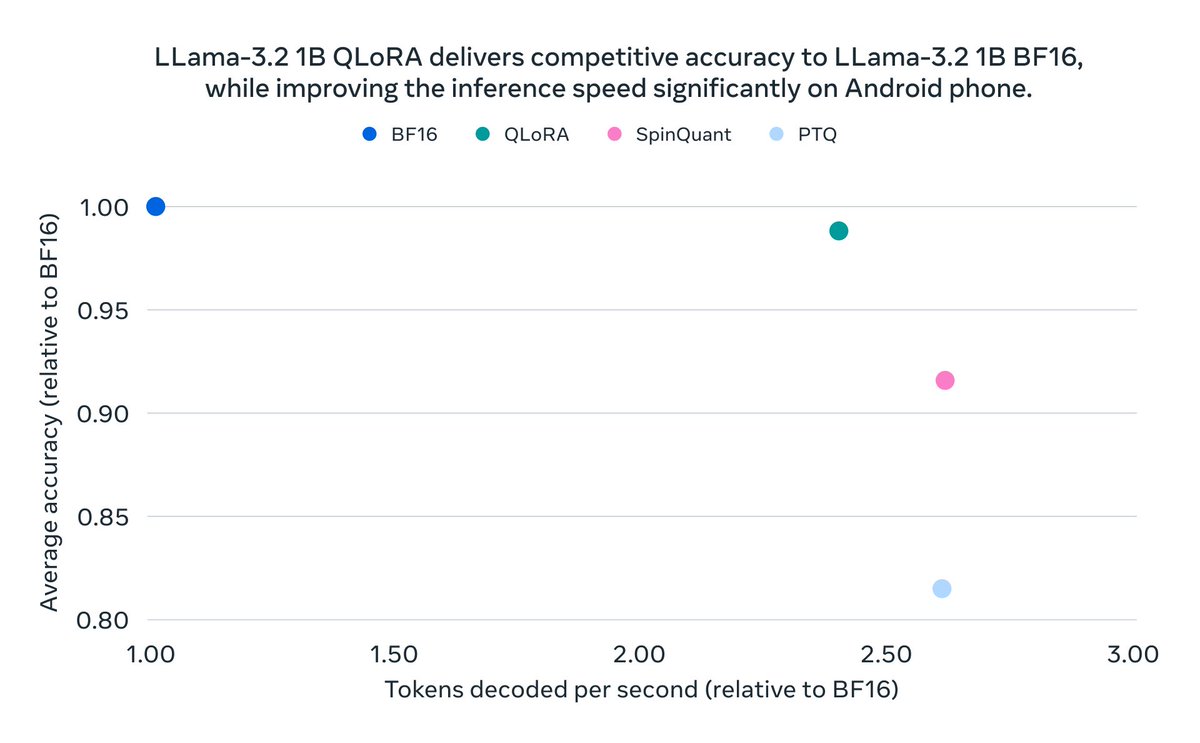
Quantized Llama 3.2 1B/3B models are here! Blazing fast CPU inference at ~50 tokens/sec for 1B & ~20 tokens/sec for 3B while being competitive on quality with the respective bf16 versions.
Very proud of the team. Can't wait to see what developers build with the foundation models.
AI at Meta@AIatMeta
We want to make it easier for more people to build with Llama — so today we’re releasing new quantized versions of Llama 3.2 1B & 3B that deliver up to 2-4x increases in inference speed and, on average, 56% reduction in model size, and 41% reduction in memory footprint. Details on our new quantized Llama 3.2 on-device models ➡️ ai.meta.com/blog/meta-llam… While quantized models have existed in the community before, these approaches often came at a tradeoff between performance and accuracy. To solve this, we Quantization-Aware Training with LoRA adaptors as opposed to only post-processing. As a result, our new models offer a reduced memory footprint, faster on-device inference, accuracy and portability — while maintaining quality and safety for developers to deploy on resource-constrained devices. The new models can be downloaded now from Meta and on @huggingface.
English
Paco Guzmán retweetledi
On device and small models are a really important part of the Llama herd so we are introducing quantized versions with significantly increased speed. These models have a 2-3x increased speedup – that is fastI Add a link if you want to share what you are building with Llama! ai.meta.com/blog/meta-llam…
English
We've just released new quantized Llama 3.2 models. the 1B is 50 tokens/s on mobile cpu. The best thing? minimal quality degradation. Read all on @sacmehtauw's post
Sachin@sacmehtauw
We’ve released QUANTIZED Llama 3.2 1B/3B models. ⚡️FAST and EFFICIENT: 1B decodes at ~50 tok/s on a MOBILE PHONE CPU. ⚡️As ACCURATE as full-precision models. ⚡️Ready to CONSUME on mobile devices. Looking forward to on-device experiences these models will enable! Read more👇
English