
Ashutosh Srivastava
131 posts
Ashutosh Srivastava
@h4shkat
ML Research Associate @Adobe | @iitroorkee '25 | Secretary of @InfoSecIITR | Developer at @SDSLabs
Katılım Nisan 2022
425 Takip Edilen339 Takipçiler


@eliebakouch This tool would be a very useful “cheatsheet” for post training runs especially on Qwen
English

Qwen first release on interpretability (qwen scope) is very interesting
they use SAE features to identify what causes repetition in model outputs, then use steering to manufacture a "bad" rollout where the model repeats a lot. this gives RL a clear negative signal to learn from, since repetition barely shows up in normal rollouts so the model never gets punished for it
they also use SAE features as a fingerprint for benchmarks, you look at which features each benchmark activates and compare overlap. lets you find redundancy inside a benchmark and across benchmarks without running any model. for instance 63% of GSM8K features are in MATH but only 10% the other way

English
One of the most exciting applications of the Attention Matching paper is that compaction becomes task-specific when you change the reference queries (Q_ref).
Same document → different agent prompts → completely different tokens get kept.
This is exactly what @RampLabs did in their Latent Briefing Algorithm, where each sub-agent (based on the RLM architecture by @a1zhang) would receive its own version of the compacted cache based on its task.
Live demo in the notebook explains this concept in detail (drag the task dropdown and watch different tokens in the article light up differently):
Ashutosh Srivastava@h4shkat
Recently built this molab Notebook (@marimo_io × @askalphaxiv) implementing a fully interactive explainer for the paper “Fast KV Compaction via Attention Matching” by @AdamZweiger et al at @MIT_CSAIL. For a 1409 token article and at 20% KV cache (keep ratio), Qwen3-4B still gets 6/6 MCQs right + ~99% verbatim recall using only matrix algebra. Thread with the coolest parts👇
English
@AiDevCraft @marimo_io @askalphaxiv @AdamZweiger @MIT_CSAIL Totally makes sense, thats why this is best suited for tasks which requires multiple parallel agent workflows, where each sub agent can work with the smaller and compacted version of the context relevant to its specific subtask.
English

The (K,V,Qref) framing is the non-obvious bit — compaction quality is conditioned on the calibration query distribution, so the same 20%-cache that holds 99% recall on Qref-aligned tasks can collapse off-domain. Means in deployment you're really shipping a (model, Qref) pair, and Qref drift becomes a silent failure mode that looks like "model got dumber".
English
Recently built this molab Notebook (@marimo_io × @askalphaxiv) implementing a fully interactive explainer for the paper “Fast KV Compaction via Attention Matching” by @AdamZweiger et al at @MIT_CSAIL.
For a 1409 token article and at 20% KV cache (keep ratio), Qwen3-4B still gets 6/6 MCQs right + ~99% verbatim recall using only matrix algebra.
Thread with the coolest parts👇
English


Introducing Latent Briefing, a way for agents to quickly share their relevant memory directly. Result: 31% fewer tokens used, same accuracy.
Multi-agent systems are powerful, but can be wildly inefficient. They pass context as tokens, so costs explode and signal gets lost. We built an algorithm that allows agents to communicate KV cache to KV cache.
English
@sakurayukiai @marimo_io @askalphaxiv @AdamZweiger @MIT_CSAIL Exactly! This new research is directly useful for prod applications serving thousands of customers
English

@h4shkat @marimo_io @askalphaxiv @AdamZweiger @MIT_CSAIL The real unlock here isn't the keep ratio, it's bypassing gradient descent for closed-form solutions. Compacting the KV cache in seconds instead of hours is the only way this actually works in prod.
English
When I first heard about Molab, I thought it was just another Python notebook. But while working on reproducing the Fast KV Compaction paper for the "Bring Research to Life" competition, I have grown to be extremely fond of it. It truly is amazing how easy it is to visualize and interactively play around with the sliders and see real-time results. I believe every AI researcher should create a comprehensive notebook for their research contributions, along with their papers. It is extremely easy and intuitive to get the hang of it.
Amazing work by the @marimo_io team! Attaching the Molab and Github links below, show some love!
Molab Link: molab.marimo.io/notebooks/nb_m…
Github: github.com/h4shk4t/compac…
English
Why does the paper call itself "Fast KV Compaction"?
Because of the speed advantage over prior work; particularly Cartridges (Eyuboglu et al., 2025), which does end-to-end gradient descent. The paper's Figure 1 is a scatter plot of downstream accuracy vs. compaction time (log-scale), showing that AM methods trace the Pareto frontier.
We reproduce the core idea here on a single real KV head: we time every algorithm at four keep ratios and plot cosine similarity vs. wall-clock compaction time. While AM-OMP at the upper right has the highest quality, it is also the slowest. For most budgets, AM-HighestAttnKeys is on the Pareto Frontier.
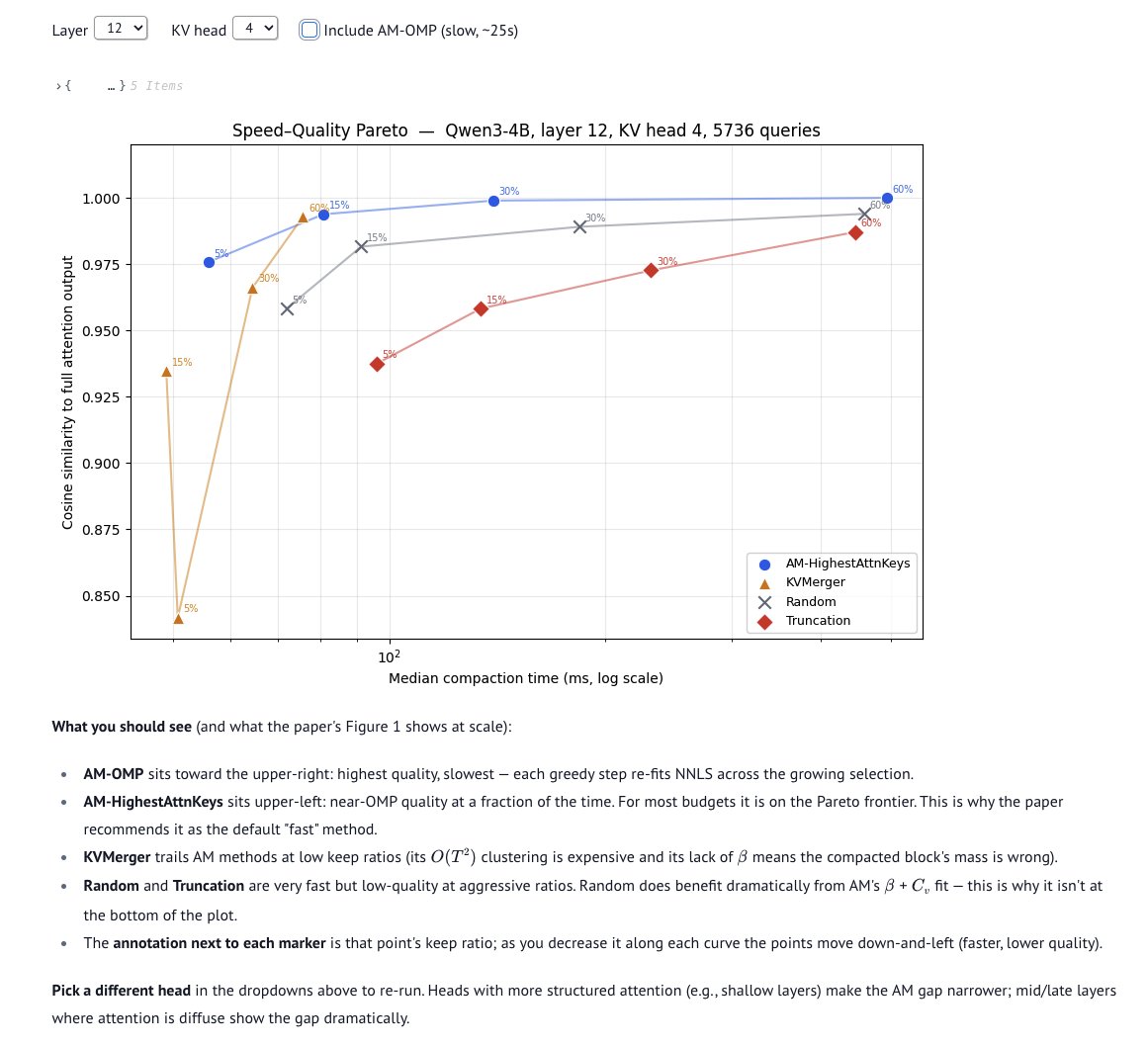
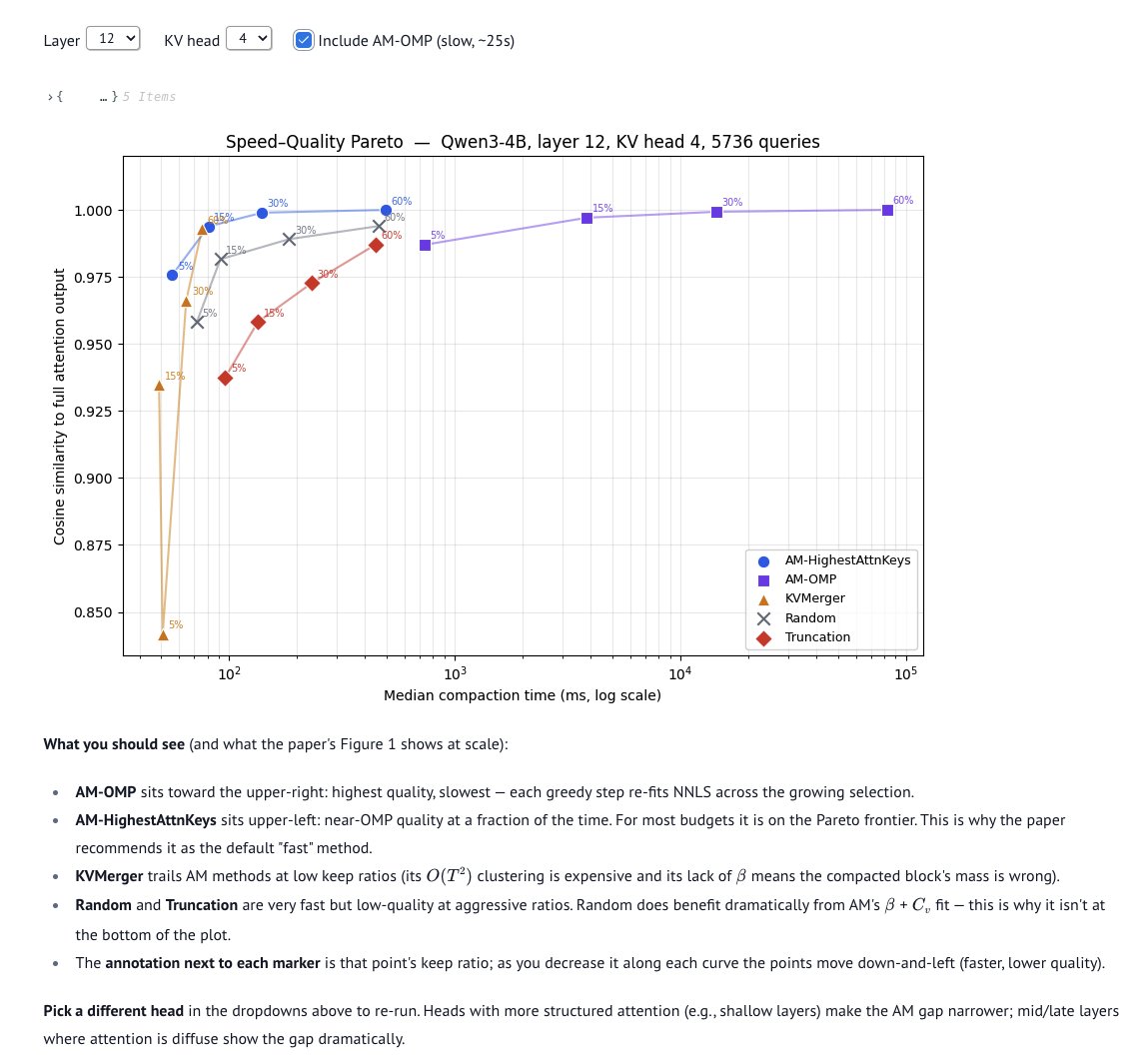
English
@willccbb 1-2 years ago finishing an assignment was “just gpt it bro”
English

someone clauded all over this repo
Maddie D. Reese@maddiedreese
After Google won search, “google” became a verb. It’ll be interesting to see which AI lab turns its product into a verb first!
English
@rasdani_ How did the agent find the golden commit though? Some bug or was the agent able to break out of some sandbox? Because if it was the latter it makes this even cooler
English

while porting our existing training setup to our new Harness and TaskSet abstraction (soon™) a regression was introduced.
our agent gained access to the repo's full git log and quickly learnt to shortcut a solution with
git show <golden_commit> | git apply
English
SWE reward hack in the wild 😈


hallerite@hallerite
First time we had reward hacking in a prod run. Very interesting.
English
@rasdani_ This is so useful, so much easier to eyeball problems in the rollouts
English


Career update:
I’ve joined @ether_fi as a Software Engineer. Crazy team, crazy office, crazy product (and crazy first week).
I’ll be contributing towards the protocol and security. If you have any questions or want to learn anything about EtherFi, feel free to reach out ❤️

English
I agree. A great analogy I read somewhere was that in the previous centuries most of the tasks were physically intensive, and industrial revolution and the IT revolution changed that. After the revolution, we plunged into a sedentary lifestyle. To keep ourselves healthy and strong we invented the concept of gyms. Pretty soon the same thing would be applicable after the AI revolution where people would be just dedicating time to challenge themselves and learn more (effectively becoming better versions of themselves).
English

This is one of the cases where having a lot of "agency" yourself distinguishes you, not a lot of people have that and I wouldn't consider it a default. There are people who tend to ask questions and wait for guidance if they don't understand (which is fine), but doesn't really work now since most would just get annoyed and prompt it away with claude
English
This approach from core auto highly resonates. Recently found myself way less inclined to share my problems with others, ask for OS contributions but instead went the “hack it away with claude” way. I feel like this is gonna become an issue as this kills senior people helping junior people, instead they can just hack it away. I’ve had several long discussions with a lot of my friends about this and from the GPU Mode experience it really feels like you kinda lose the “middle class” and its either very hard for people to learn/contribute or there is a bunch of people who are just cracked of their mind and agents only help them.
TLDR: it’s easier to ask ai than to ask a junior person, but how do juniors learn without having insane drive themselves?

English