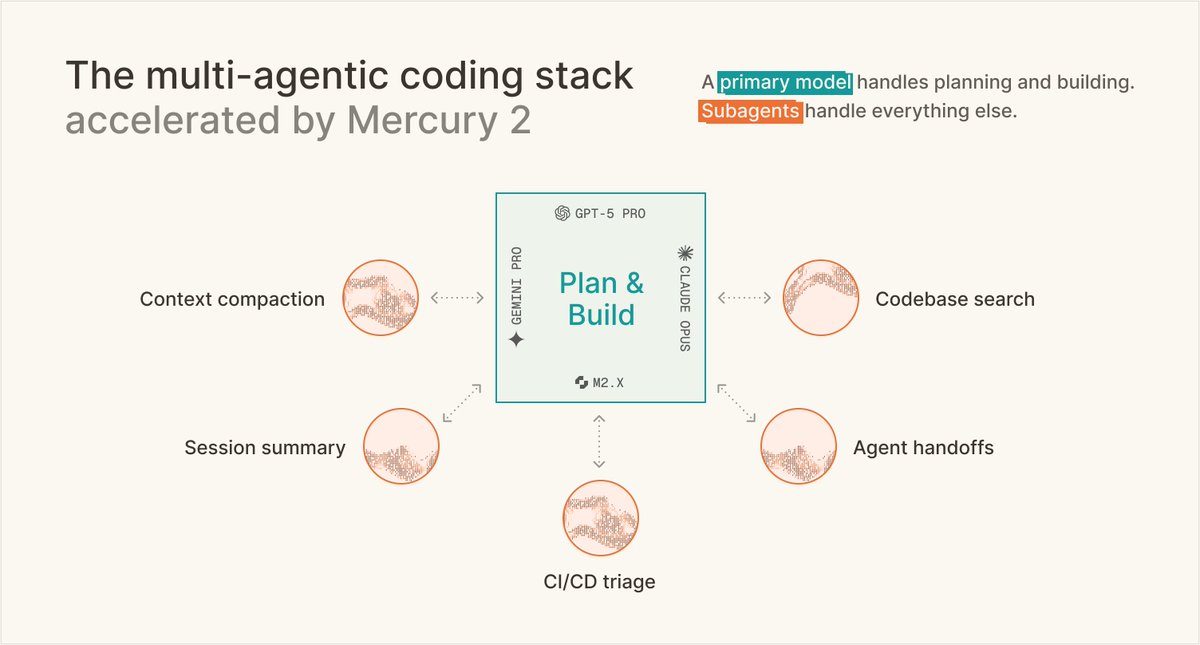
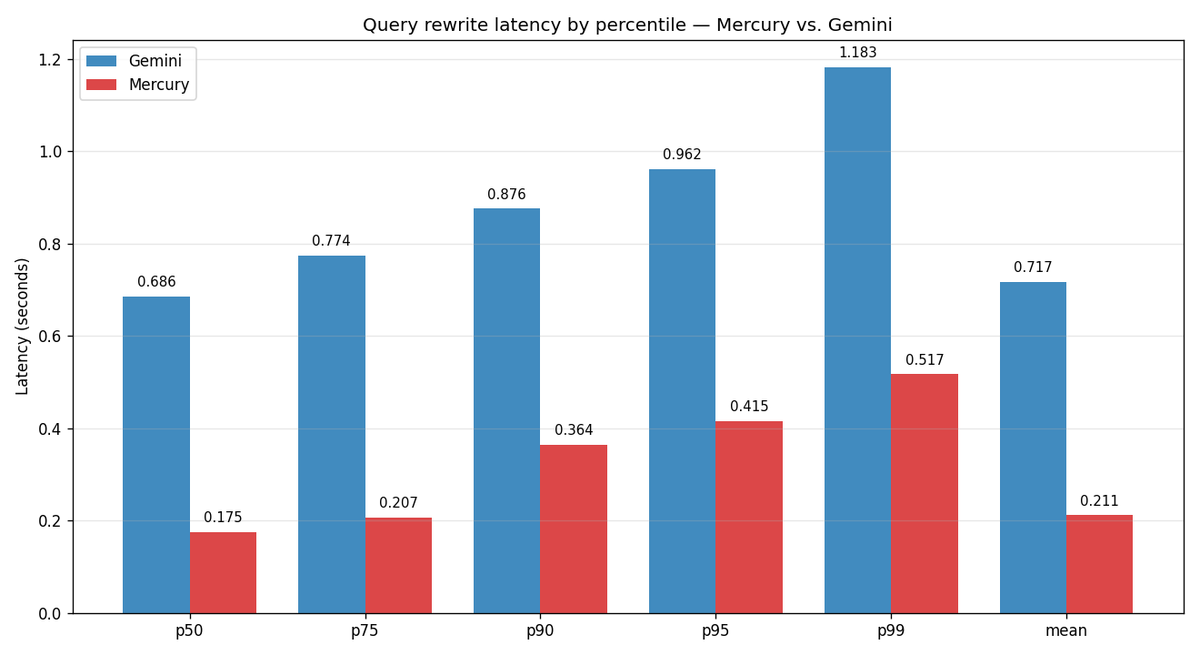
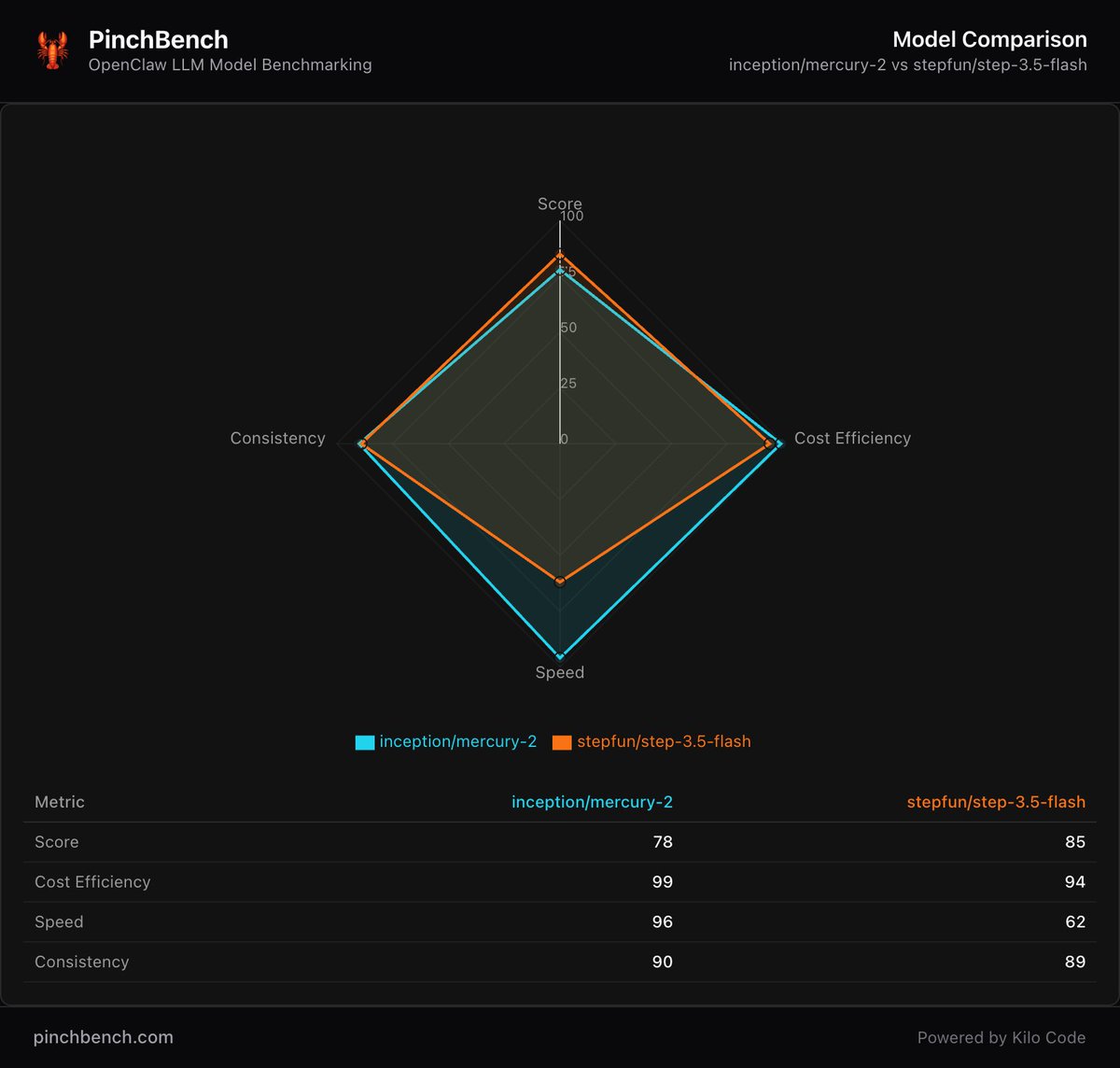
Harley Wiltzer retweetledi

The transformer made training parallel and unlocked scaling laws for pre-training. Inference is still sequential. Diffusion is the evolution for inference.
Inception@_inception_ai
Will the next decade of LLMs run on autoregression, or on diffusion? One of the top questions we got at MLSys this week. Part 6, the final part of our founder story series with @timt at @MenloVentures. Featuring @StefanoErmon, @adityagrover_, @volokuleshov
English