Shann³@shannholmberg
new update to the LLM Knowledge base
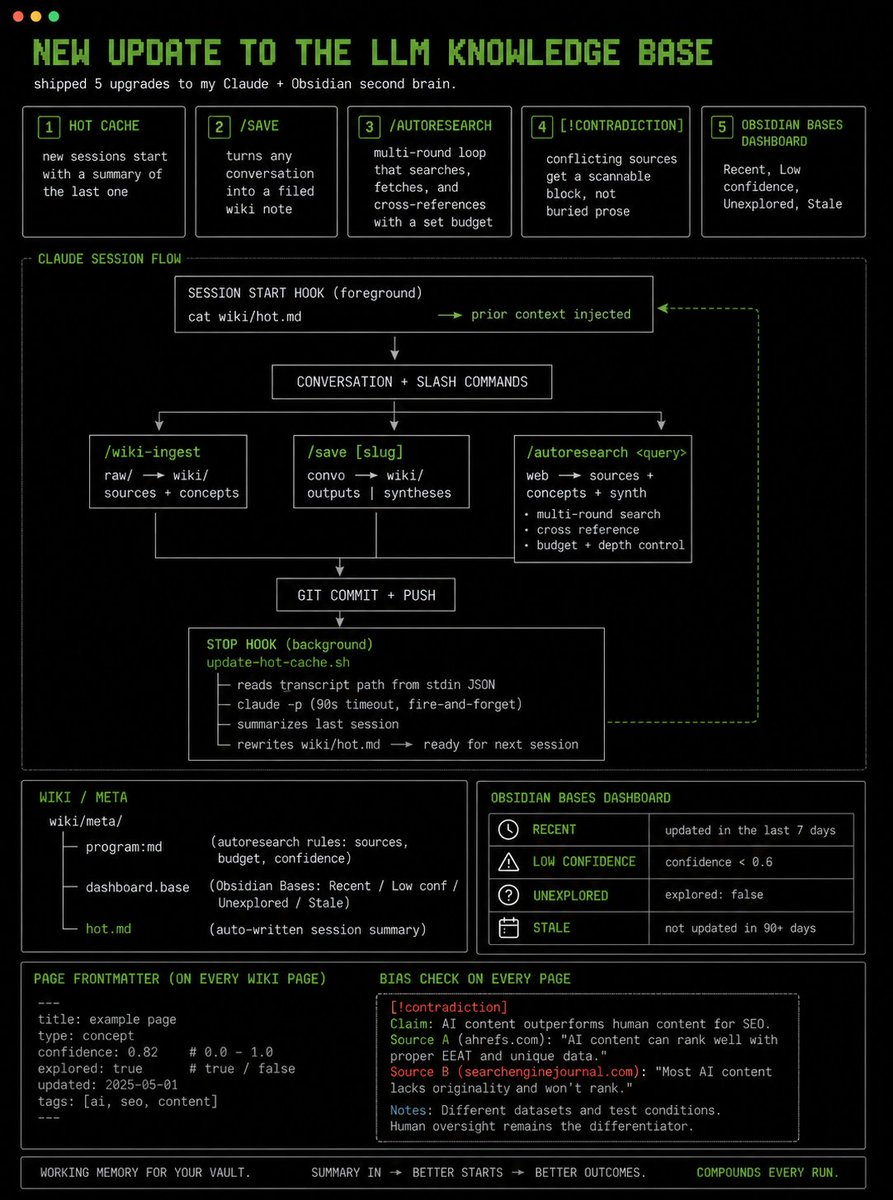
shipped 5 upgrades to my Claude + Obsidian second brain today:
- hot cache → new sessions start with a summary of the last one
- /save → turns any conversation into a filed wiki note
- /autoresearch → multi-round loop that searches, fetches, and cross-references with a set budget
- [!contradiction] callouts → conflicting sources get a scannable block, not buried prose
- Obsidian Bases dashboard → Recent, Low confidence, Unexplored, Stale
every page has confidence + explored frontmatter. the dashboard shows what's shaky, unreviewed, or 90+ days old.
the hot cache I'll notice daily. Stop hook runs claude -p on the transcript and rewrites wiki/hot .md. SessionStart injects it, that means the vault has working memory.