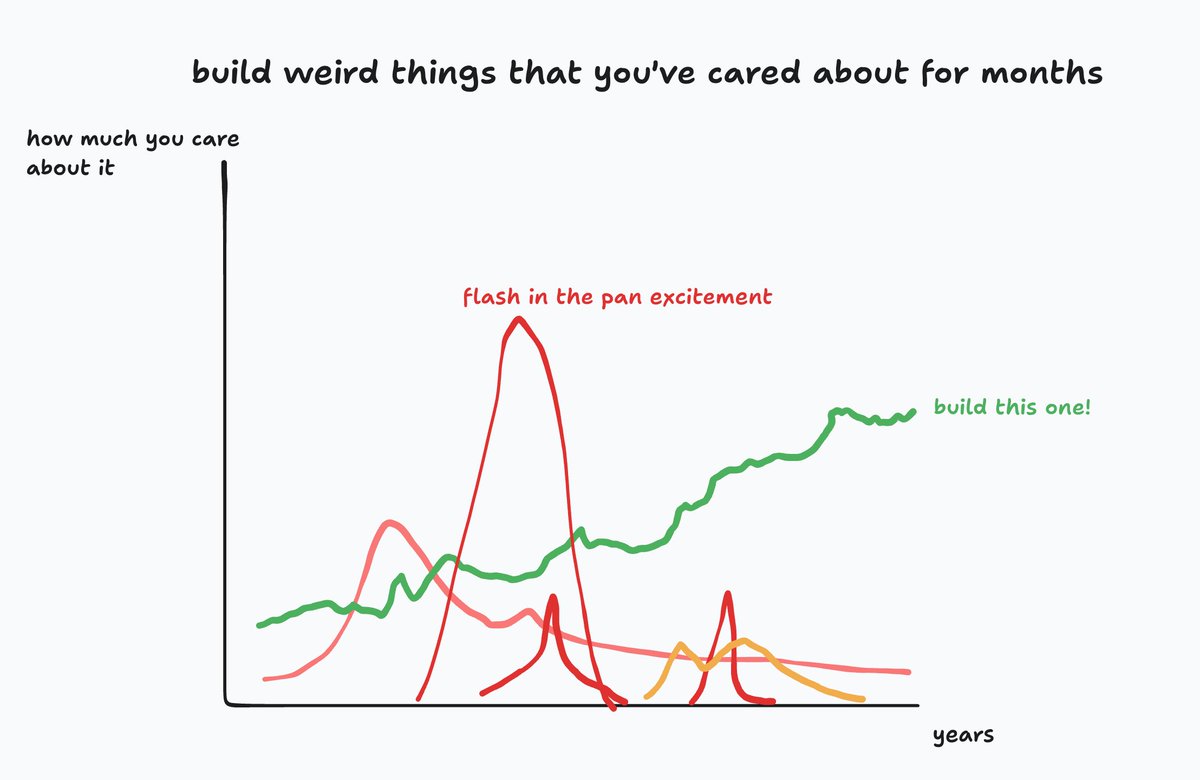
herrick retweetledi

Koah has raised a $5M seed round led by @ForerunnerVC, with participation from @southpkcommons.
In just 8 months, apps reaching 100M+ users are monetizing sustainably with Koah’s AI-native ads.
We deliver $10+ eCPMs, premium demand, and minimal impact on retention. We are quickly becoming the standard for consumer AI monetization.
This round will accelerate our mission to make scalable, native monetization effortless for every AI app.
English