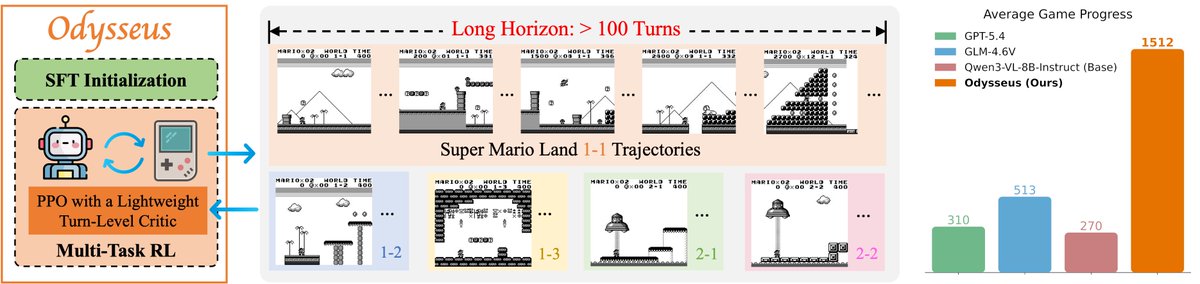
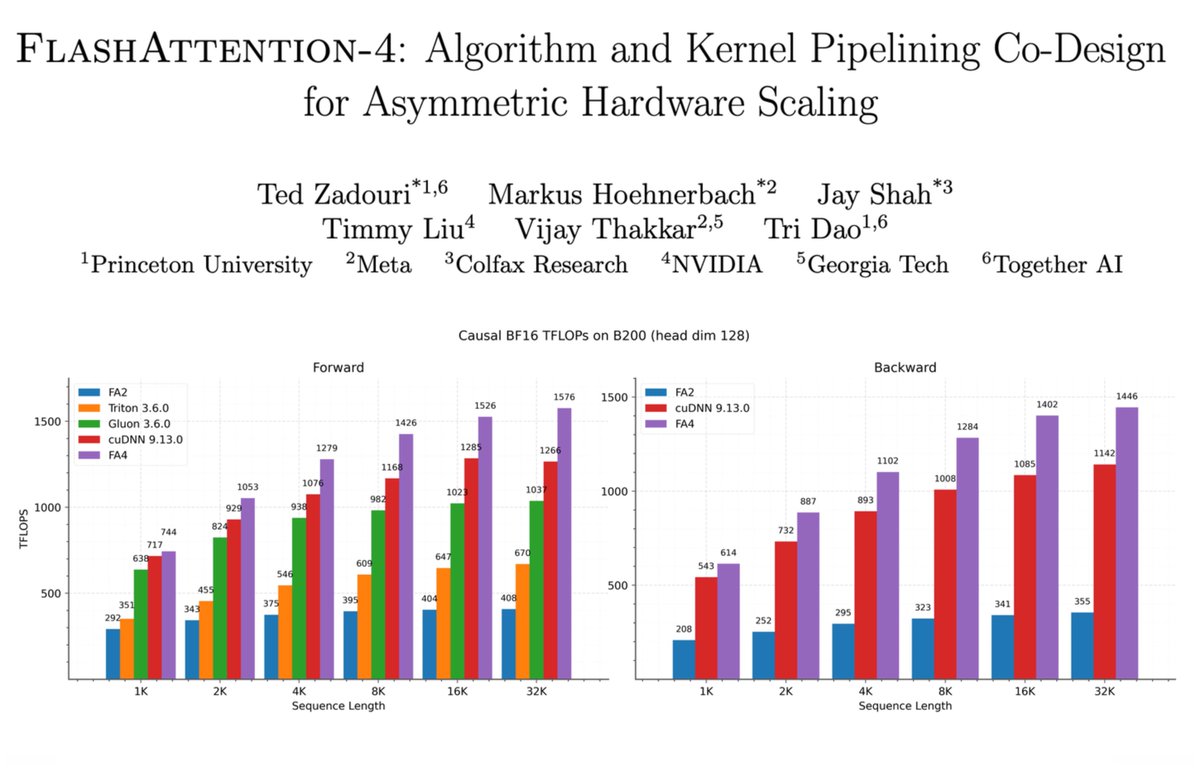
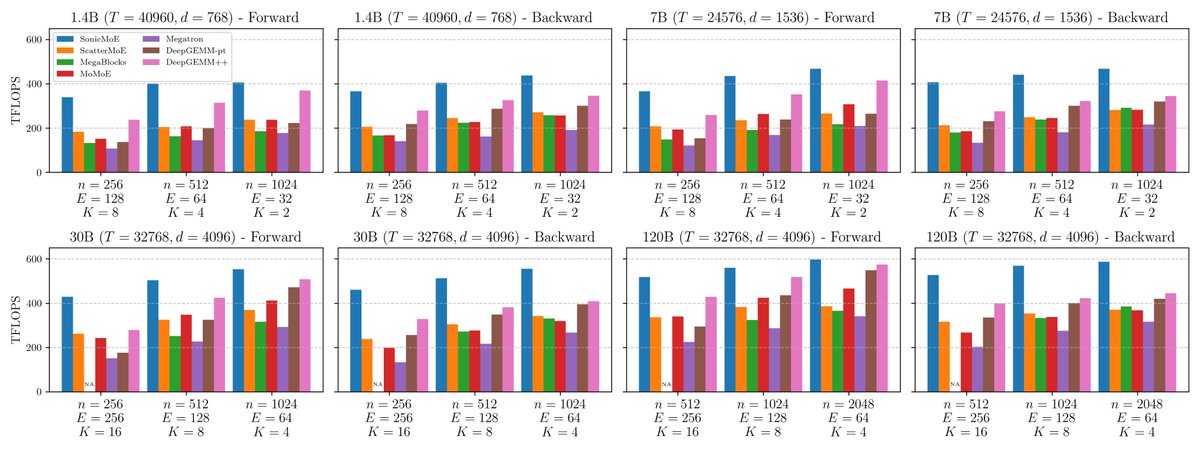
Sabitlenmiş Tweet

Very excited to share our latest work with @susieshang, @stanleyrwei, @prfsanjeevarora, and @noamrazin!
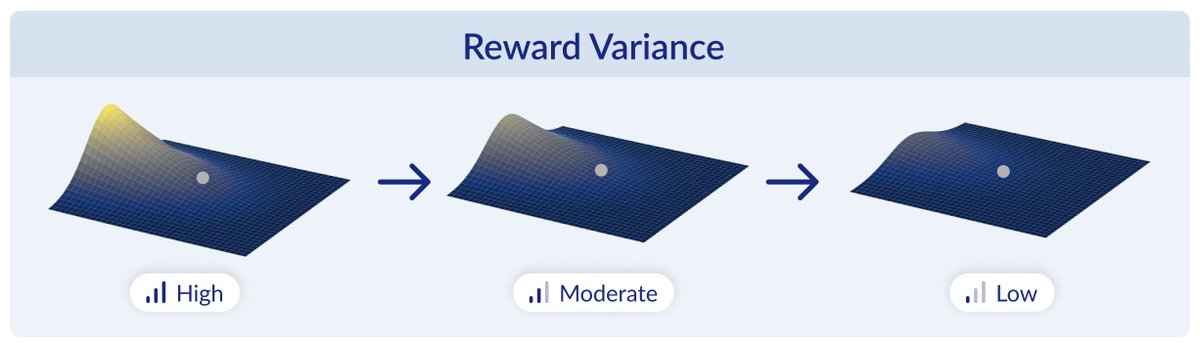
One concrete application is in the code generation setting: unit tests give verifiable rewards, but partial credit for partially passing code is not always benign. It can help learning, or trap the model on almost-correct solutions.
Still a lot to understand about what makes a good proxy reward function!
Noam Razin@noamrazin
📰 RL for LMs often relies on imperfect proxy rewards, which can lead to reward hacking. But are incorrect rewards necessarily harmful? Turns out, they can also be benign or even beneficial! This has implications for reward model evaluation and verifiable reward design. 🧵
English