Leon retweetledi

New paper! "Forgetting in Language Models: Capacity, Optimization, and Self-Generated Replay"
Andrew Gordon Wilson@andrewgwils
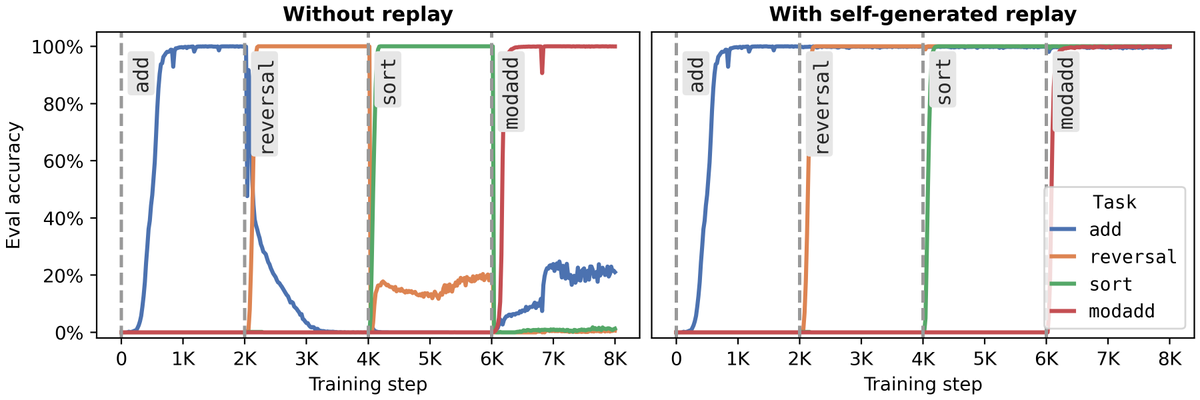
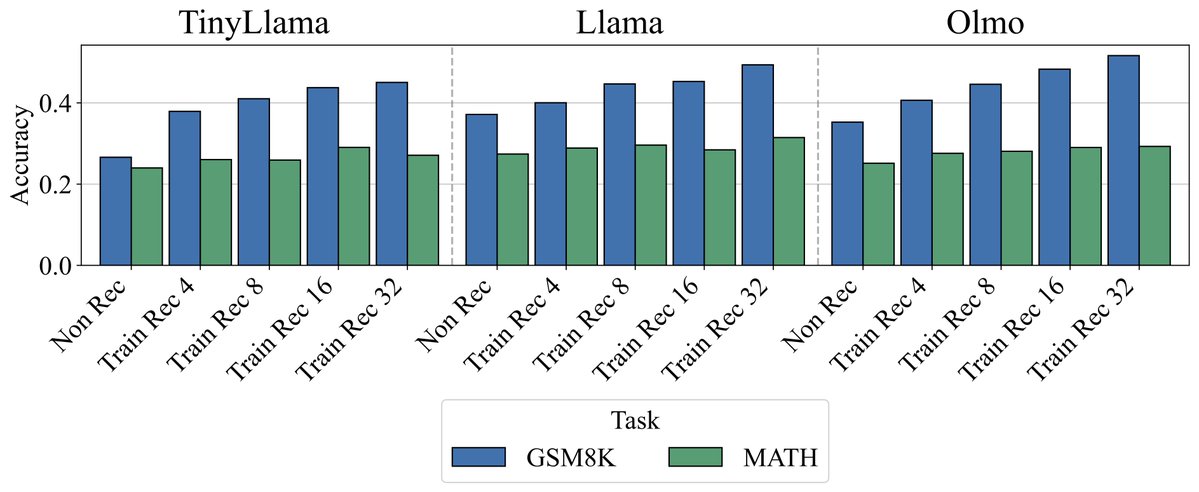
How much does a language model forget when finetuned on new tasks? We show both model size and optimization matter and forgetting can be nearly eliminated with self-generated replay! arxiv.org/abs/2605.26097 w/@mrtnm @dongkyucho @ShikaiQiu @rumichunara @Pavel_Izmailov 1/8
English