Sabitlenmiş Tweet
iamrobotbear (bk)
27.7K posts


iamrobotbear (bk)
@iamrobotbear
Product Manager & AI Engineer working on Gen AI & ML. Opinions are my own, not my employer's. RT !=endorsement
Seattle, WA Katılım Kasım 2021
7K Takip Edilen4.1K Takipçiler
@trq212 @FactoryAI Oh, it does do the thing I was just requesting, I responded too soon!
English
@trq212 Overall I really like it. I'd really love to see something similar to @FactoryAI's codebase scoring and something that helps generate a plan to improve CC's ability to work effectively in a codebase. IE: If your codebase doesn't have tests, is poorly organized, etc it should assign a score and then offer to create a branch / worktree to improve CC's ability to work in the codebase and then generate a plan that the user approves that then writes automated test coverage, etc.
BTW - I really need some feedback on something I emailed you and @AnthropicAI support on to ensure we're in compliance, can you please help??
English

we're testing a new version of /init based on your feedback- it should interview you and help setup skills, hooks, etc.
you can enable it with this env_var flag:
CLAUDE_CODE_NEW_INIT=1 claude
would love your feedback!
Thariq@trq212
I want to make /init more useful- what do you think it should do to help setup Claude Code in a repo?
English
iamrobotbear (bk) retweetledi

We’ve created an agents skill that gives all of your agents the power to understand the most complex PDFs - with dense tables, unlabeled charts, messy handwriting and more.
Our LlamaParse agents skill can be installed in one-line thanks to @vercel’s skills utility. LlamaParse orchestrates VLMs to deliver best-in-class accuracy over 40+ document types. The skills file allows agents to invoke it when needed to translate complex PDFs into agent-readable plaintext markdown.
`npx skills add run-llama/llamaparse-agent-skills --skill llamaparse`
If you prefer something fast, free, and local, you can similarly install liteparse as a skill.
Come check it out: developers.llamaindex.ai/python/cloud/l…
Sign up to LlamaParse: cloud.llamaindex.ai/?utm_source=xj…
LlamaIndex 🦙@llama_index
LlamaParse now has an official Agent Skill you can use across 40+ agents. With built-in instructions for parsing complex documents, including different formats, tables, charts, and images, your agents gain access to deeper document understanding, not just raw text extraction. 👇 Watch the demo 📖 Read the docs: developers.llamaindex.ai/python/cloud/l… 🚀 Get started with LlamaCloud: cloud.llamaindex.ai/signup?utm_sou…
English
iamrobotbear (bk) retweetledi

iamrobotbear (bk) retweetledi

your .claude folder is what separates you from every other developer under the sun who uses Claude. it’s your taste, rules, skills, and workflows. this article is the most complete and simple explanation of all its components.
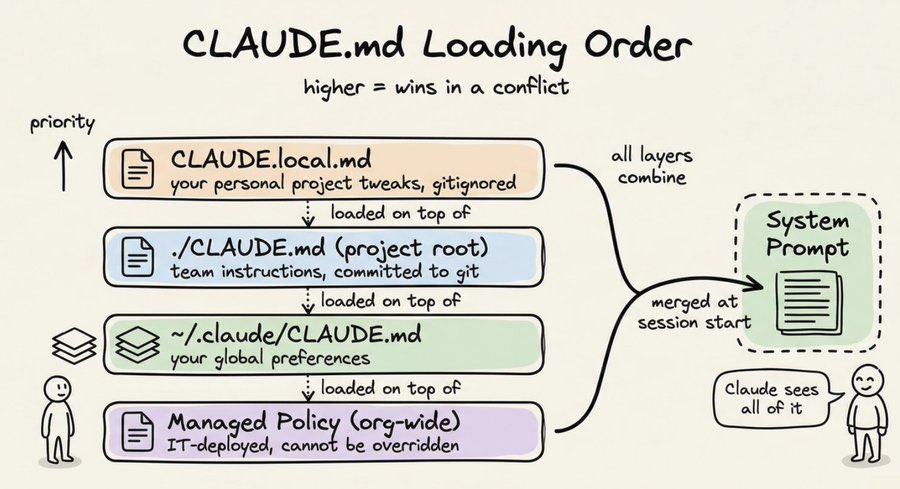
Akshay 🚀@akshay_pachaar
English
iamrobotbear (bk) retweetledi

You can now schedule recurring cloud-based tasks on Claude Code.
Set a repo (or repos), a schedule, and a prompt. Claude runs it via cloud infra on your schedule, so you don’t need to keep Claude Code running on your local machine.
English
iamrobotbear (bk) retweetledi

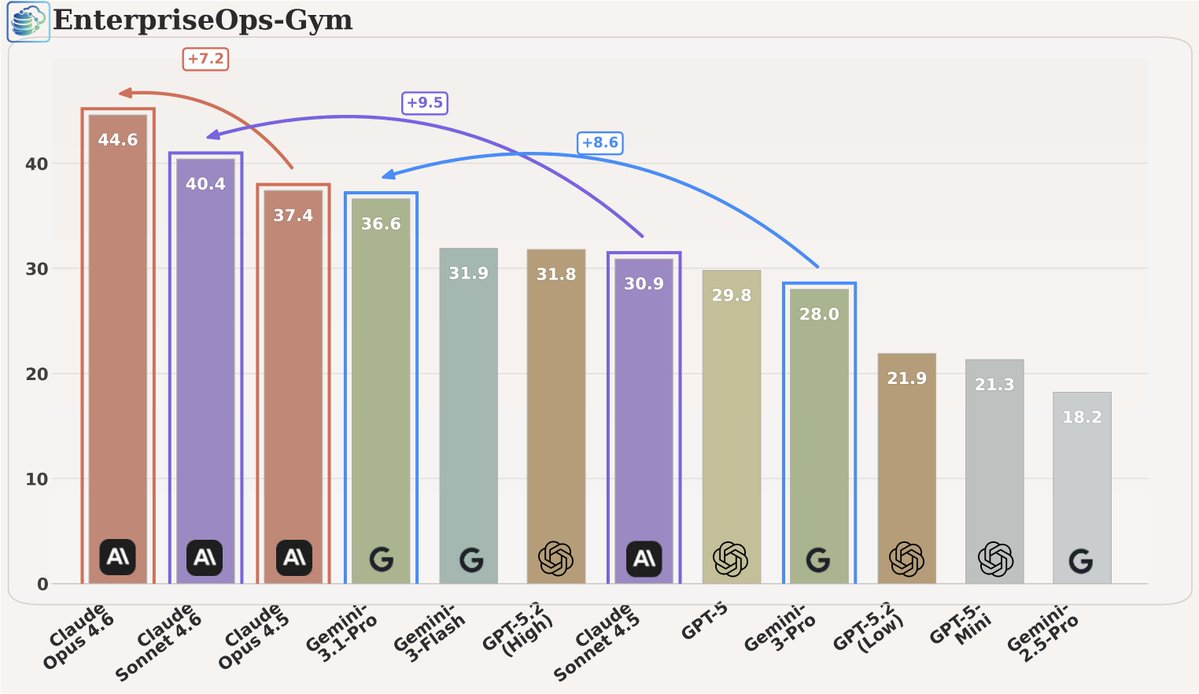
🔥 𝗘𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲𝗢𝗽𝘀-𝗚𝘆𝗺 𝗶𝘀 𝘁𝗮𝗸𝗶𝗻𝗴 𝗼𝗳𝗳 𝗵𝘂𝗴𝗲: 2K downloads in 3 days (trending #6 dataset + #3 paper of the day) 🏆.
So we re-ran the leaderboard on the 𝗹𝗮𝘁𝗲𝘀𝘁 𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗰𝗹𝗼𝘀𝗲𝗱 𝗺𝗼𝗱𝗲𝗹𝘀… and the results were promising.
✅ Claude versions show a meaningful jump in reliability on enterprise tasks.
✅ Gemini 3.1 Pro is catching up fast, now much closer to Sonnet 4.6 than earlier releases.
And yet, the bigger takeaway is still the same:
- Big room for improvement on enterprise-grade agentic tasks.
- These workflows punish "seemingly correct." One wrong default, one policy miss, one unintended side effect.. and the task fails.
📢 𝗖𝗮𝗹𝗹𝗼𝘂𝘁 (especially if you’re working on agents):
As we prepare our next NeurIPS/COLM submissions, try your agents on EnterpriseOps-Gym and see how they hold up on realistic, policy-constrained, long-horizon tasks.
🌐 Website: enterpriseops-gym.github.io
🤗 Dataset: huggingface.co/datasets/Servi…
@ServiceNowRSRCH , @sagardavasam , @turingcom , @turingcomdev , @Mila_Quebec , @shiva_malay @PShravannayak
English
@nlw But don’t forget the groceries, too. Lol.
Completely agree on this framing. Aligned on your opportunity ai as well.
English

Is AI going to take everyone’s job, or is the best use case for your new AI product helping me book flights, because it can’t be both.
English
iamrobotbear (bk) retweetledi
Introducing LiteParse - the best model-free document parsing tool for AI agents 💫
✅ It’s completely open-source and free.
✅ No GPU required, will process ~500 pages in 2 seconds on commodity hardware
✅ More accurate than PyPDF, PyMuPDF, Markdown. Also way more readable - see below for how we parse tables!!
✅ Supports 50+ file formats, from PDFs to Office docs to images
✅ Is designed to plug and play with Claude Code, OpenClaw, and any other AI agent with a one-line skills install. Supports native screenshotting capabilities.
We spent years building up LlamaParse by orchestrating state-of-the-art VLMs over the most complex documents. Along the way we realized that you could get quite far on most docs through fast and cheap text parsing.
Take a look at the video below. For really complex tables within PDFs, we output them in a spatial grid that’s both AI and human-interpretable. Any other free/light parser light PyPDF will destroy the representation of this table and output a sequential list.
This is not a replacement for a VLM-based OCR tool (it requires 0 GPUs and doesn’t use models), but it is shocking how good it is to parse most documents.
Huge shoutout to @LoganMarkewich and @itsclelia for all the work here.
Come check it out: llamaindex.ai/blog/liteparse…
Repo: github.com/run-llama/lite…
LlamaIndex 🦙@llama_index
We've spent years building LlamaParse into the most accurate document parser for production AI. Along the way, we learned a lot about what fast, lightweight parsing actually looks like under the hood. Today, we're open-sourcing a light-weight core of that tech as LiteParse 🦙 It's a CLI + TS-native library for layout-aware text parsing from PDFs, Office docs, and images. Local, zero Python dependencies, and built specifically for agents and LLM pipelines. Think of it as our way of giving the community a solid starting point for document parsing: npm i -g @llamaindex/liteparse lit parse anything.pdf - preserves spatial layout (columns, tables, alignment) - built-in local OCR, or bring your own server - screenshots for multimodal LLMs - handles PDFs, office docs, images Blog: llamaindex.ai/blog/liteparse… Repo: github.com/run-llama/lite…
English
iamrobotbear (bk) retweetledi
iamrobotbear (bk) retweetledi

spent some time today playing with MolmoPoint
it's pretty crazy that we can use VLMs for multi-object tracking now
instead of spelling out coordinates as text, it points by directly selecting parts of its own visual features
prompt: "Track blue players."
Jae Sung Park@jjaesungpark
VLMs today—including our own Molmo—point via raw text strings (e.g. "
English
iamrobotbear (bk) retweetledi

Many people shared this with me but I feel like something is off. Not that the Google Skills article is wrong but they sucked the joy out of it. Skills are interesting because they're a new way for us to encode how agents operate.
The Anthropic team recently published an article about their experiences in developing with Skills. I learned so many things from it because they shared:
- what kept breaking
- what turned out to matter
- weird tricks that actually helped
- unique examples adn use cases (e.g. the video one)
- how the team discovered the pattern
Google’s article is just like here are 5 boxes, here is the standard form, here is the taxonomy... None of these feels like they came from production experience. I don't know why, but Google always gives everything formal names, which doesn't add much, like a platform team turning taste into a corporate framework.
If someone is not already deep in skills, this post could make the space feel more complicated, not clearer. Maybe I'm wrong tho...
Google Cloud Tech@GoogleCloudTech
English
iamrobotbear (bk) retweetledi

Dan says he's got Qwen 3.5 397B-A17B - a 209GB on disk MoE model - running on an M3 Mac at ~5.7 tokens per second using only 5.5 GB of active memory (!) by quantizing and then streaming weights from SSD (at ~17GB/s), since MoE models only use a small subset of their weights for each token
Dan Woods@danveloper
English
iamrobotbear (bk) retweetledi

iamrobotbear (bk) retweetledi

How we build software @intercom is unrecognisable vs 12 months ago. We're fully Claude Code pilled and seeing enormous productivity gains. Excellent thread here from Brian on some things we're doing.
Brian Scanlan@brian_scanlan
We've been building an internal Claude Code plugin system at Intercom with 13 plugins, 100+ skills, and hooks that turn Claude into a full-stack engineering platform. Lots done, more to do. Here's a thread of some highlights.
English
iamrobotbear (bk) retweetledi

By popular demand, Dispatch can now launch Claude Code sessions. Ask it to build, make, or improve something!
To use it, update your Claude desktop app and make sure you have Code enabled.

English
iamrobotbear (bk) retweetledi

🆕 Claude Cowork, Skills, and the Future of AI Coworkers latent.space/p/felix-anthro…
@felixrieseberg has spent years working at the interface layer, from Electron and the Slack desktop app to now helping build @claudeai Cowork. In this episode, Felix explains why execution is getting so cheap that teams can “build all the candidates,” why Anthropic is betting on local-first agent workflows, and why the future of AI products may belong less to chatbots and more to systems that can actually do knowledge work.
English
iamrobotbear (bk) retweetledi

iamrobotbear (bk) retweetledi
