Wei Ping@_weiping
🚀 Introducing Nemotron-Cascade! 🚀
We’re thrilled to release Nemotron-Cascade, a family of general-purpose reasoning models trained with cascaded, domain-wise reinforcement learning (Cascade RL), delivering best-in-class performance across a wide range of benchmarks.
💻 Coding powerhouse
After RL, our 14B model:
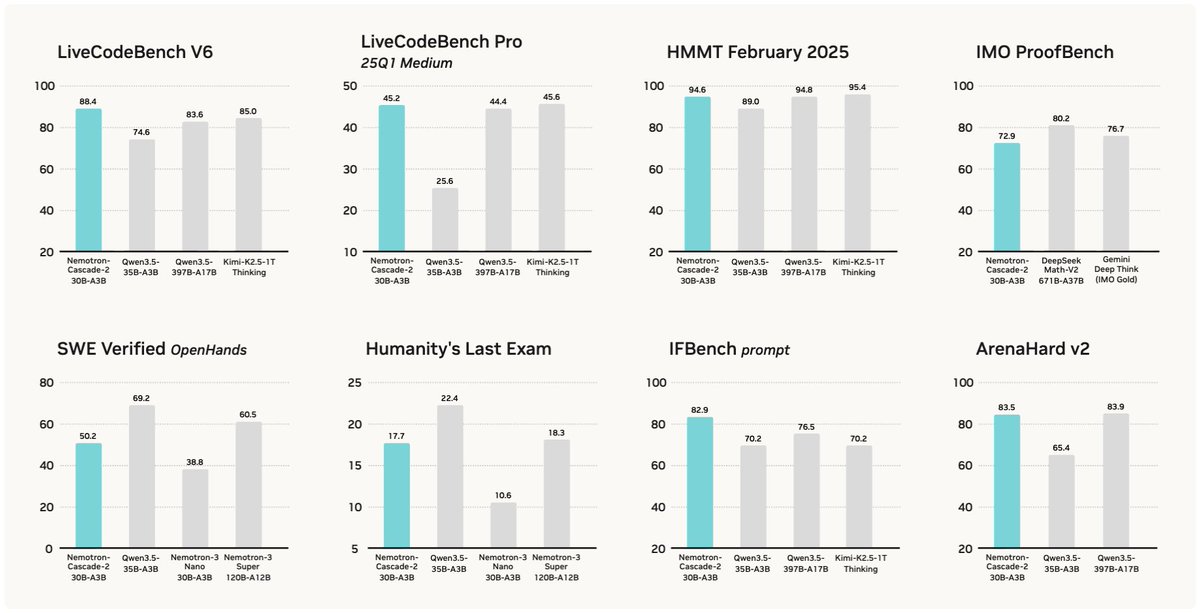
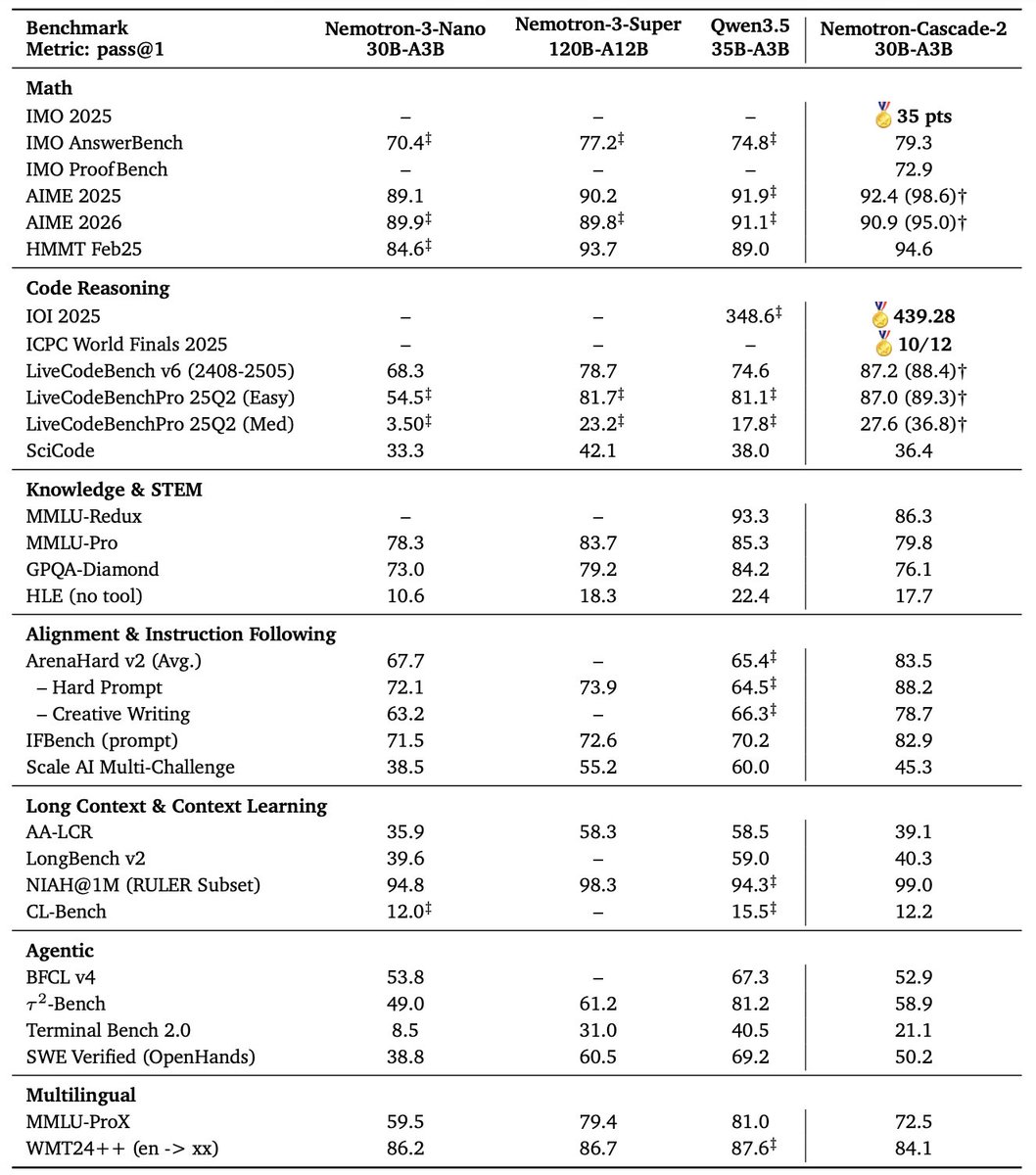
• Surpasses DeepSeek-R1-0528 (671B) on LiveCodeBench v5/v6/Pro.
• Achieves silver-medal performance at IOI 2025 🥈.
• Reaches a 43.1% pass@1 on SWE-Bench Verified, and 53.8% with test-time scaling.
🧠 What is Cascade RL?
Instead of mixing heterogeneous prompts across domains, Cascade RL trains sequentially, domain by domain, which reduces engineering complexity, mitigates heterogeneous verification latencies, and enables domain-specific curricula and tailored hyperparameter tuning.
✨ Key insight
Using RLHF for alignment as a pre-step dramatically boosts complex reasoning—far beyond preference optimization. Subsequent domain-wise RLVR stages rarely hurt the benchmark performance attained in earlier domains and may even improve it, as illustrated in the following figure.
🤗 Models & training data 🔥
👉 huggingface.co/collections/nv…
📄 Technical report with detailed training and data recipes
👉 arxiv.org/pdf/2512.13607