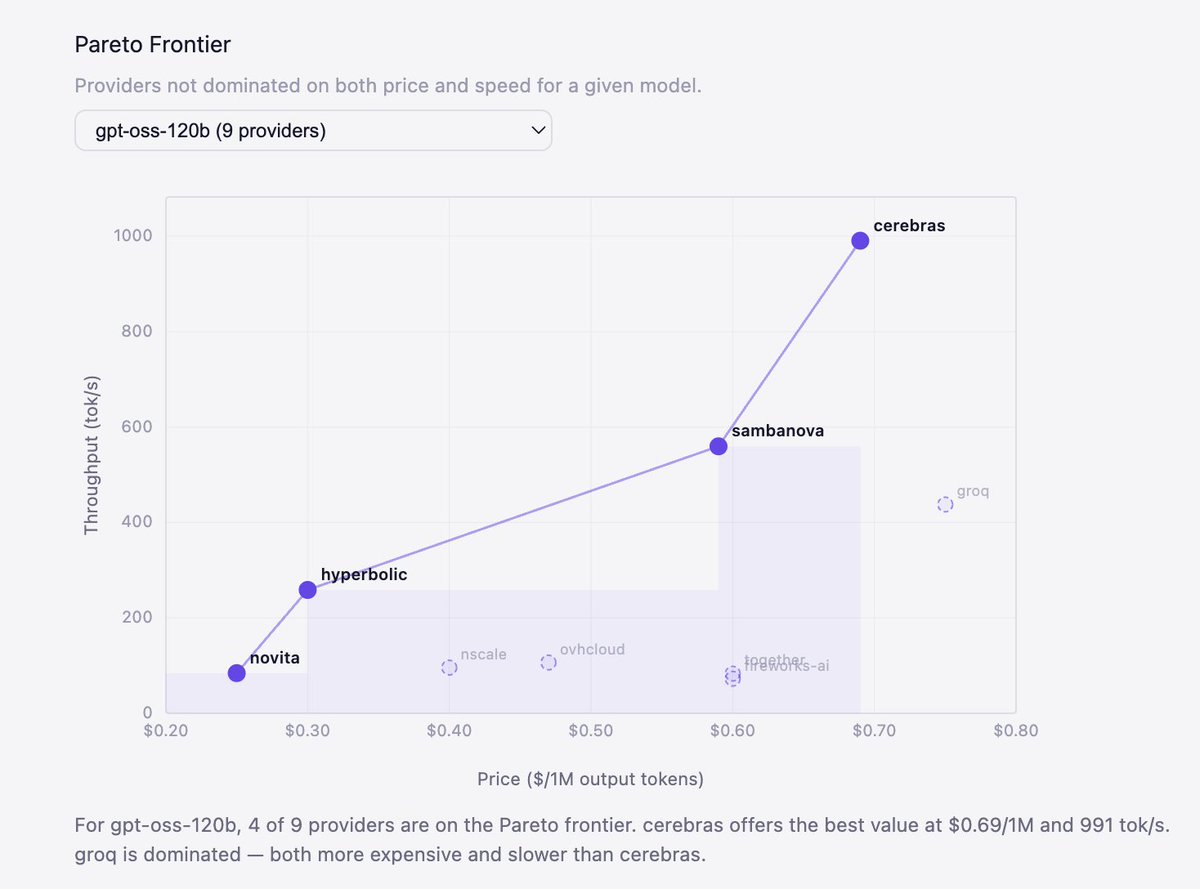
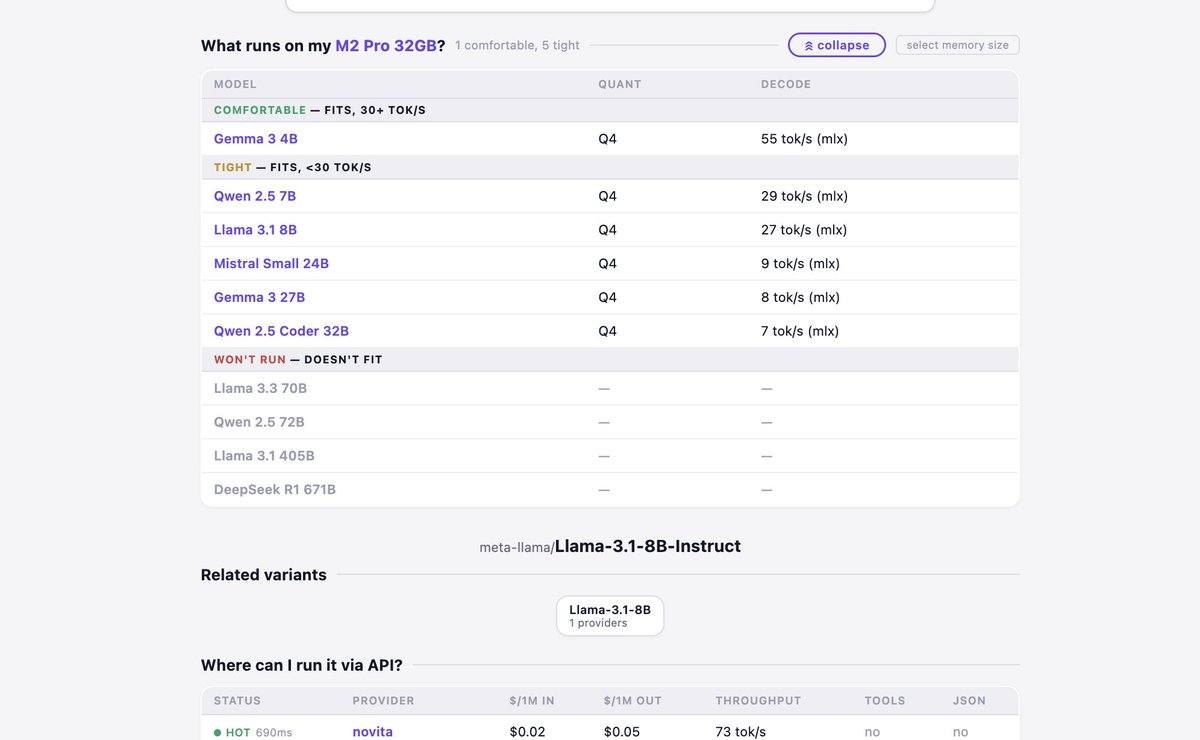
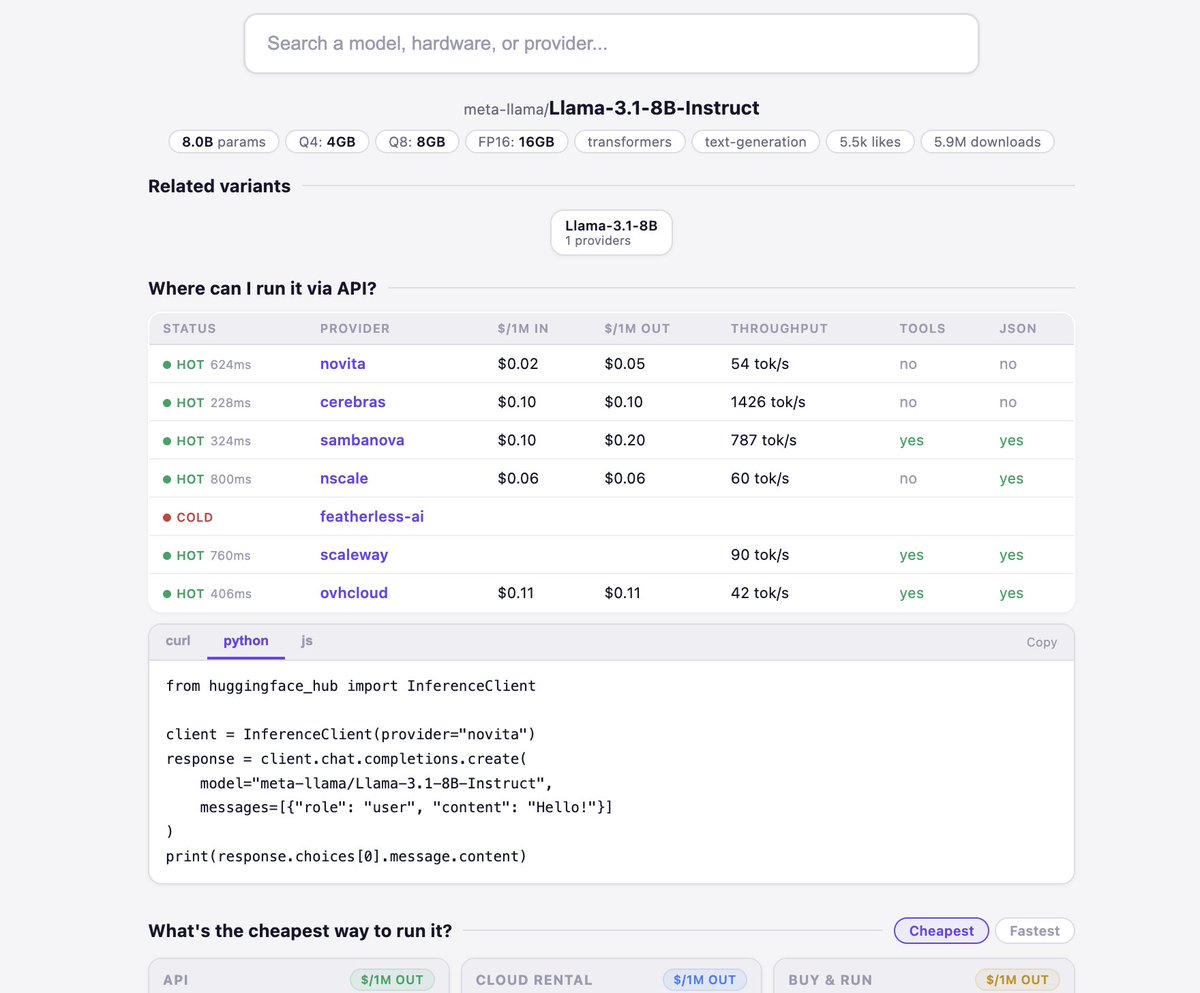
Sabitlenmiş Tweet

🦀[atypical rust course]🦀 I love rust. But why do we teach the borrow checker as rules to memorize when the rules are derivable from things we already know.
I've been writing a course that starts from CS fundamentals, computer architecture, and compilability and arrives at the borrow checker as a consequence.
I find Rust's syntax slightly over-pedantic. I wanted to see if I could spell it out as training wheels sort of syntax. let mut &mut x = r becomes let owner(rebindable(x)) = mem_copy(at(r)). Rust's macro system is excellent and makes this possible.
The course is written for experienced programmers, especially C++. WIP, first chapters up. (link in comment)
Would love to hear what you think, especially if you've taught or learned Rust recently.

English