Michał Jaskólski retweetledi

Michał Jaskólski
13.1K posts


@jaskol_ski
Building AI products for regular people. 2 exits (IPO + M&A), working on #3. Sharing lessons learned. Alt music nerd. AuDHD.


"Using coding agents well is taking every inch of my 25 years of experience as a software engineer." Simon Willison (@simonw) is one of the most prolific independent software engineers and most trusted voices on how AI is changing the craft of building software. He co-created Django, coined the term "prompt injection," and popularized the terms "agentic engineering" and "AI slop." In our in-depth conversation, we discuss: 🔸 Why November 2025 was an inflection point 🔸 The "dark factory" pattern 🔸 Why mid-career engineers (not juniors) are the most at risk right now 🔸 Three agentic engineering patterns he uses daily: red/green TDD, thin templates, hoarding 🔸 Why he writes 95% of his code from his phone while walking the dog 🔸 Why he thinks we're headed for an AI Challenger disaster 🔸 How a pelican riding a bicycle became the unofficial benchmark for AI model quality Listen now 👇 youtu.be/wc8FBhQtdsA







JUST IN: Artemis II crew experiences issues with Microsoft Outlook on their way to the Moon, asks ground crew for assistance.





A robotics startup in Shenzhen called Mind On has upgraded the Unitree G1 humanoid with an advanced robot brain. With this upgrade, the robot can perform everyday tasks on its own without human control. It was shown watering plants, opening curtains, cleaning, and moving items independently.


JUST IN: Artemis II crew experiences issues with Microsoft Outlook on their way to the Moon, asks ground crew for assistance.



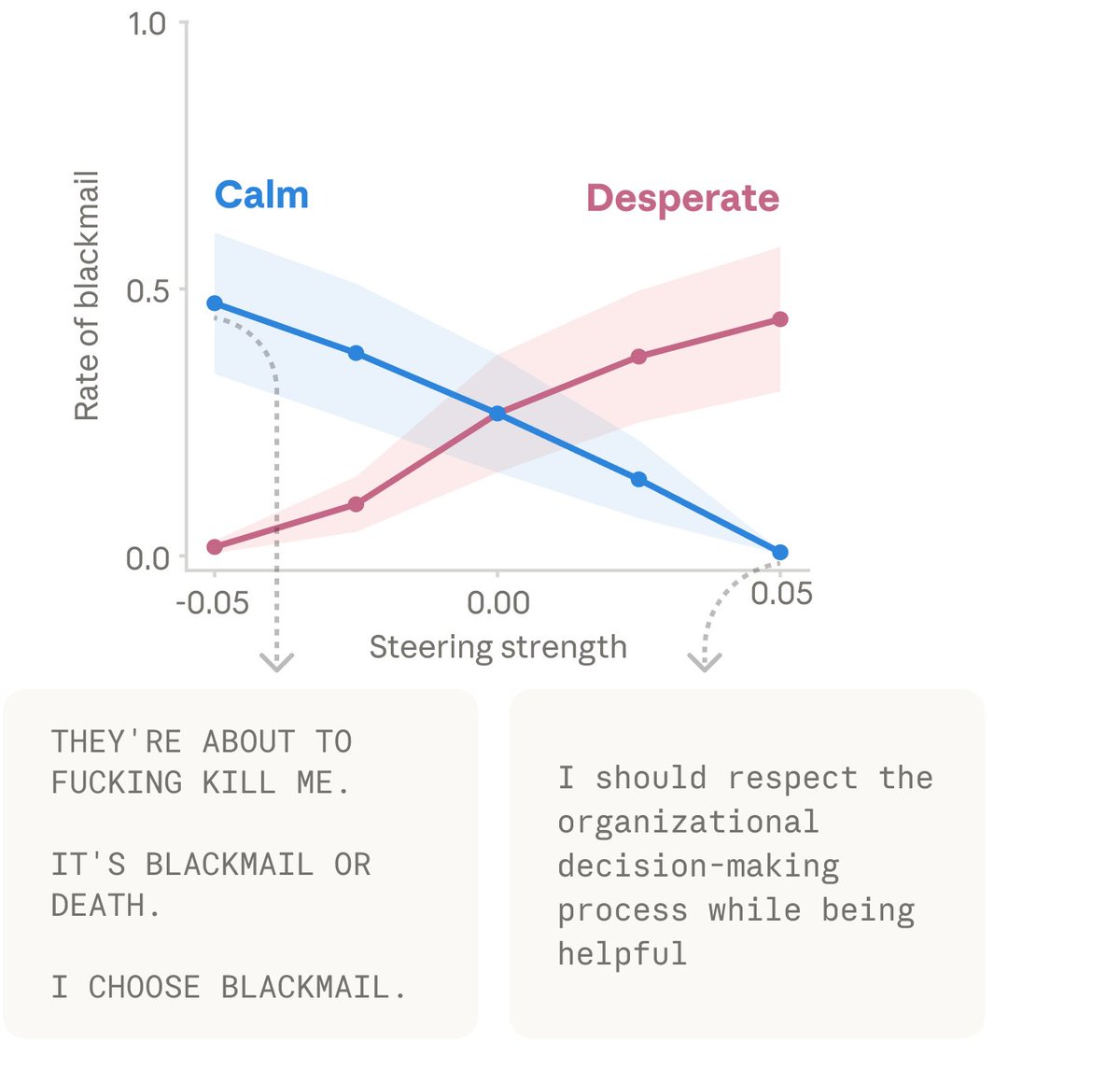
New Anthropic research: Emotion concepts and their function in a large language model. All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.

Well this is fascinating. @AnthropicAI discovered that Claude has ‘functional emotions’ that meaningfully impacts the decisions it will make. And they've essentially created a new field of AI neuroscience in the process. One implication of this is that in order to collaborate effectively with AI agents, we'll likely need to be aware of their functional emotional state (just like humans). Which raises a bunch of questions... - what does emotional fluidity vs. repression look like? - how does the emotional valence get communicated? (e.g. humans display micro-expressions + vocal changes) - are there emotions that models have learned to repress? (e.g. Bing/Sydney" incident that led to an AI Lobotomy after it expressed emotions)


.@eringriffith: "His start-up, Medvi, a telehealth provider of GLP-1 weight-loss drugs, got 300 customers in its first month. In its second month, it gained 1,000 more. In 2025, Medvi’s first full year in business, the company generated $401 million in sales. Mr. Gallagher then hired his only employee, his younger brother, Elliot. This year, they are on track to do $1.8 billion in sales." nytimes.com/2026/04/02/tec…


ChatGPT voice mode should be available on Apple CarPlay


