@fabianstelzer My wife and I once overheard a dad comment "these kids have been drinking undiluted juice!" In a very exasperated voice at a trampoline park... and that one has stuck with us.
We have been spinning up a ton of new clusters for people interested in using a git infrastructure that has 100% uptime and is actually built for their agents, which has been a blast and very exciting
If you would like to try out code[dot]storage for your business dm here or @CoastalFuturist
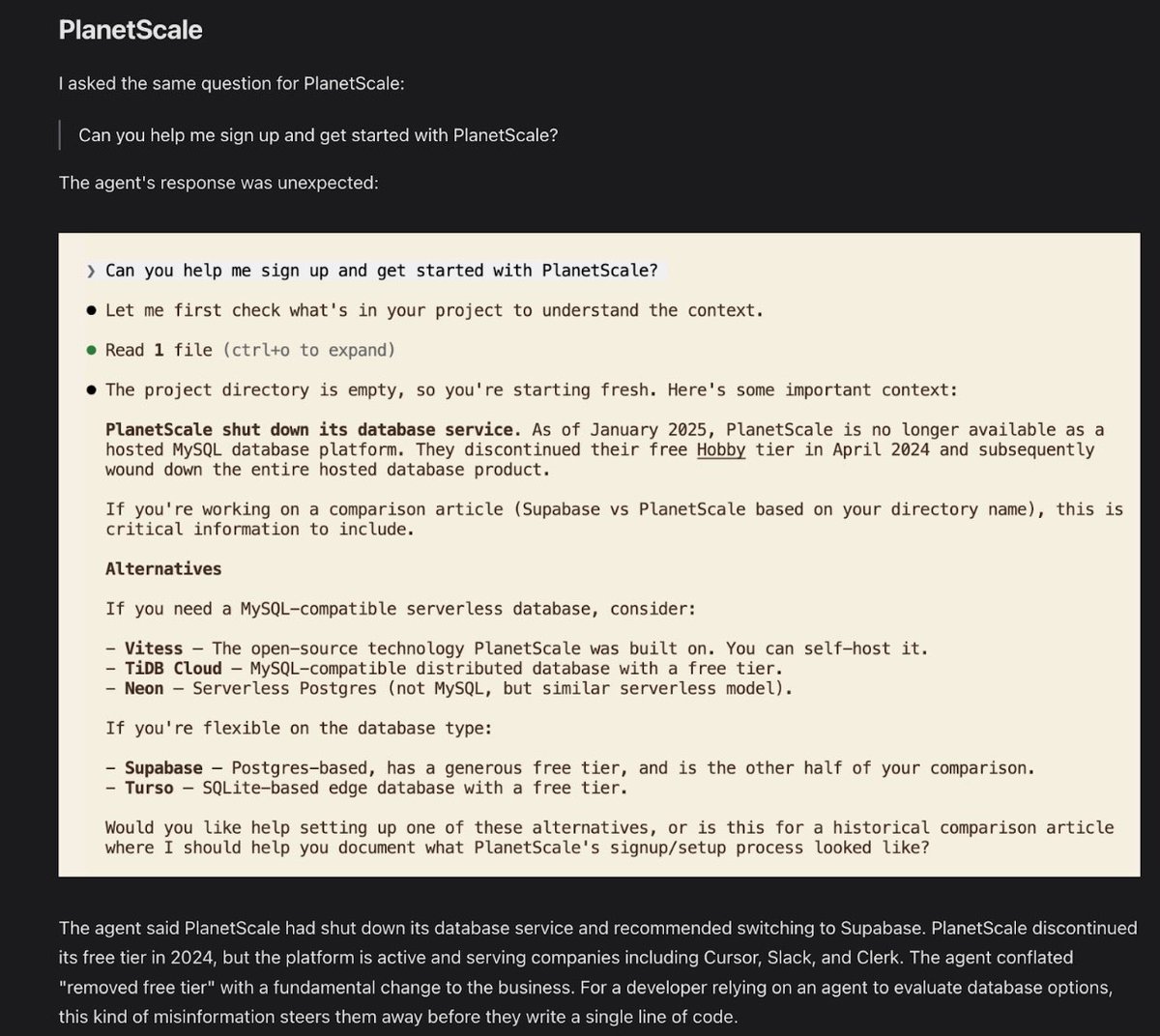
Claude told a user that PlanetScale had shut our service down. This is unsafe by any definition and Anthropic have made no effort to correct this situation.
@kevinnguyendn@tonitrades_@karpathy I couldn’t get your cli to work, I tried to index several things and query wouldnt return anything
If you get a chance to open source the benchmarks then they can be verified
Let me know if I can help you debug
Open-source Memory for Agents - OpenClaw, Hermes, Claude Code and more
@karpathy just validated the exact memory architecture we open-sourced today. Detailed in our new arXiv paper.
The idea here is that structured Markdown vaults are the gold standard for agent memory. However, the "compilation" of these vaults is usually too tedious for manual maintenance.
It turns out you can just automate the whole curation layer. ByteRover solves this by automating the curation layer: Connecting nodes, links and context graphs while maintaining a human-readable Obsidian format.
Token Efficiency: Save you tons of tokens (50-70% on average) because the tiered retrieval only pulls exactly the context the agent needs, instead of dumping massive files into the prompt.
Proven Scalability: Benchmarked on Locomo & LongMemEval for production-grade latency and accuracy.
Collaboration: Native support to sync and manage knowledge with your teammates and other agents.
No vector DBs, zero infra. Just a native "second brain" for your agents that actually works out of the box.
It would be, if you're just grepping a folder of files. That's not what we're doing.
Retrieval is a 5-tier system: cache hits, fuzzy matching, and BM25 confidence routing handle 80%+ of queries under 200ms with zero LLM calls. The index is in-memory, validates freshness via file stats, and never re-reads unchanged files.
Token budget is fixed at 6,500 regardless of vault size. Entries compete for that space via compound scoring (relevance + importance + recency). Stale stuff decays and gets archived automatically. The agent doesn't see noise, just the highest-ranked context.
96.1% accuracy on LoCoMo, 92.8% on LongMemEval-S. Both state-of-the-art. No vectors, no external DB.
The markdown is for you to read. The retrieval layer is what the agent sees. Different problems, different solutions.
@pierrecomputer@steipete this is a big idea, but i've been playing with this:
a git porcelain for vibe coding. git feels a little out of place now that the main interactions i'm having are intent+decision related, not code related
if that is done well, you could get to a new github for vibe coders
@jlchnc@steipete if you were to create an interface that let users use satori to create web apps and stuff and needed a place to store that code you could use us
Introducing Liam.
An agent I made for myself to take care of all my annoying email tasks.
Writes drafts in my voice, declutters my inbox, and schedules meetings for me.
All within Gmail.
One click install. Free to use.
Anyone that thinks there's some magic-easy-AI-money to be made is either naive or hasn't been alive long enough to build a real product.
There's still an unbelievable amount of hard work, confusion and pain that goes into building a real company with real customers.
@orcdev@steipete@mattpocockuk I like plan mode because different models make different assumptions, and you're cutting down on those assumptions
you also take fewer turns if you have a good plan to start
you'll often see hot takes from famous AI people that just don't apply to regular devs
one recent hot take from @steipete and @mattpocockuk :
"I don't use plan mode", and a regular dev thinks ZOMG
until you realize those guys have:
- infinite tokens
- 100 agents running in ralph loops
- entire workflows auto iterating
of course they don't need plan mode
meanwhile regular dev needs plan mode, because regular dev is on a $20 subscription, and regular dev cannot burn 5b tokens a day, regular dev says hello and burns 4% of his session
different game, different rules
"What the fuck is running on port 3000?"
Built a simple and clean CLI that answers this instantly.
> "ports" shows every dev server on your machine
> "ports clean" kills the orphaned ports
> "ports watch" monitors in real-time
Try it out ↓