BREAKING
Elon Musk endorsed my Top 26 Essential Papers for Mastering LLMs and Transformers
Implement those and you’ve captured ~90% of the alpha behind modern LLMs.
Everything else is garnish.
This list bridges the Transformer foundations
with the reasoning, MoE, and agentic shift
Recommended Reading Order
1. Attention Is All You Need (Vaswani et al., 2017)
> The original Transformer paper. Covers self-attention,
> multi-head attention, and the encoder-decoder structure
> (even though most modern LLMs are decoder-only.)
2. The Illustrated Transformer (Jay Alammar, 2018)
> Great intuition builder for understanding
> attention and tensor flow before diving into implementations
3. BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018)
> Encoder-side fundamentals, masked language modeling,
> and representation learning that still shape modern architectures
4. Language Models are Few-Shot Learners (GPT-3) (Brown et al., 2020)
> Established in-context learning as a real
> capability and shifted how prompting is understood
5. Scaling Laws for Neural Language Models (Kaplan et al., 2020)
> First clean empirical scaling framework for parameters, data, and compute
> Read alongside Chinchilla to understand why most models were undertrained
6. Training Compute-Optimal Large Language Models (Chinchilla) (Hoffmann et al., 2022)
> Demonstrated that token count matters more than
> parameter count for a fixed compute budget
7. LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023)
> The paper that triggered the open-weight era
> Introduced architectural defaults like RMSNorm, SwiGLU
> and RoPE as standard practice
8. RoFormer: Rotary Position Embedding (Su et al., 2021)
> Positional encoding that became the modern default for long-context LLMs
9. FlashAttention (Dao et al., 2022)
> Memory-efficient attention that enabled long context windows
> and high-throughput inference by optimizing GPU memory access.
10. Retrieval-Augmented Generation (RAG) (Lewis et al., 2020)
> Combines parametric models with external knowledge sources
> Foundational for grounded and enterprise systems
11. Training Language Models to Follow Instructions with Human Feedback (InstructGPT) (Ouyang et al., 2022)
> The modern post-training and alignment blueprint
> that instruction-tuned models follow
12. Direct Preference Optimization (DPO) (Rafailov et al., 2023)
> A simpler and more stable alternative to PPO-based RLHF
> Preference alignment via the loss function
13. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)
> Demonstrated that reasoning can be elicited through prompting
> alone and laid the groundwork for later reasoning-focused training
14. ReAct: Reasoning and Acting (Yao et al., 2022 / ICLR 2023)
> The foundation of agentic systems
> Combines reasoning traces with tool use and environment interaction
15. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (Guo et al., 2025)
> The R1 paper. Proved that large-scale reinforcement learning without
> supervised data can induce self-verification and structured reasoning behavior
16. Qwen3 Technical Report (Yang et al., 2025)
> A modern architecture lightweight overview
> Introduced unified MoE with Thinking Mode and Non-Thinking
> Mode to dynamically trade off cost and reasoning depth
17. Outrageously Large Neural Networks: Sparsely-Gated Mixture of Experts (Shazeer et al., 2017)
> The modern MoE ignition point
> Conditional computation at scale
18. Switch Transformers (Fedus et al., 2021)
> Simplified MoE routing using single-expert activation
> Key to stabilizing trillion-parameter training
19. Mixtral of Experts (Mistral AI, 2024)
> Open-weight MoE that proved sparse models can match dense quality
> while running at small-model inference cost
20. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints (Komatsuzaki et al., 2022 / ICLR 2023)
> Practical technique for converting dense checkpoints into MoE models
> Critical for compute reuse and iterative scaling
21. The Platonic Representation Hypothesis (Huh et al., 2024)
> Evidence that scaled models converge toward shared
> internal representations across modalities
22. Textbooks Are All You Need (Gunasekar et al., 2023)
> Demonstrated that high-quality synthetic data allows
> small models to outperform much larger ones
23. Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet (Templeton et al., 2024)
> The biggest leap in mechanistic interpretability
> Decomposes neural networks into millions of interpretable features
24. PaLM: Scaling Language Modeling with Pathways (Chowdhery et al., 2022)
> A masterclass in large-scale training
> orchestration across thousands of accelerators
25. GLaM: Generalist Language Model (Du et al., 2022)
> Validated MoE scaling economics with massive
> total parameters but small active parameter counts
26. The Smol Training Playbook (Hugging Face, 2025)
> Practical end-to-end handbook for efficiently training language models
Bonus Material
> T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019)
> Toolformer (Schick et al., 2023)
> GShard (Lepikhin et al., 2020)
> Adaptive Mixtures of Local Experts (Jacobs et al., 1991)
> Hierarchical Mixtures of Experts (Jordan and Jacobs, 1994)
If you deeply understand these fundamentals; Transformer core, scaling laws, FlashAttention, instruction tuning, R1-style reasoning, and MoE upcycling, you already understand LLMs better than most
Time to lock-in, good luck!
🚨 Holy shit... Alibaba just dropped a vector database that runs inside your app.
It's called Zvec and it runs directly inside your application no server, no config, no infrastructure costs.
No Docker. No cloud bills. No DevOps nightmare.
Built on Proxima, Alibaba's battle-tested vector search engine powering their own production systems at scale.
The numbers don't lie:
→ Searches billions of vectors in milliseconds
→ pip install zvec and you're searching in under 60 seconds
→ Dense + sparse vectors + hybrid search in a single call
And it runs everywhere:
→ Notebooks
→ Servers
→ Edge devices
→ CLI tools
100% Opensource. Apache 2.0 license.
This is the vector DB the RAG community has been waiting for production-grade performance without the production-grade headache.
Link in the first comment 👇
I’ve spent 10 years teaching math to machine learning engineers.
80% of university math is irrelevant to your actual job.
Luckily, I've created a FREE roadmap to teach you the 20% you actually need.
Like, retweet, and comment "roadmap" and I'll DM you the link.
This place is toxic.
For the last seven years I warned you that LLMs and similar approaches would not lead us to AGI. Almost nobody is willing to acknowledge that, even though so many of you gave me endless grief about it at the time.
I also warned you -– first –- that Sam Altman could not be trusted, that OpenAI would lose its dominance, that GPT-5 would not be all AGI, and that LLMs lacked world models. That hallucinations would not go away. That out of distribution generalization was THE key issue.
And that the economics of LLMs didn't make sense. And that the LLM companies would start seeking bailouts.
The receipts are all here if you care. As for me, I have had it. If you want to hear other prescient warnings in advance, subscribe to my newsletter Marcus on AI.
Or you can stay here and be lied to; the choice is yours.
The one question Elon Musk would ask AGI
Lex: "So when maybe you or somebody else creates an AGI system, and you get to ask her one question, what would that question be?"
Elon: "What's outside the simulation?"
gm, the food taste so good... And what a luxury to be able to have more than one piece of fruit per day!
I know some of you may have a lot of questions. I won't have all the answers.
Let me chill for a bit. Then figure out the next steps. There are always more opportunities in the future than there were in the past.
I want to thank everyone for your support. It meant a lot to me, and kept me strong in the darkest moments.
A few quick updates/thoughts:
Giggle Academy has been going well, and will be a big part of my life for the next few years.
Will continue to invest in blockchain/decentralized technologies, AI, and biotech. I am a long term investor who care about impact, not returns.
I will also dedicate more time and funding to charity (and education). I have some rough ideas.
Still working on my book. About 2/3 done, I think. Writing a book is a lot more work than I anticipated, but will see this one through.
Oh, @binance seems to be doing well without me back-seat-driving, which is excellent. Every founder's dream!
Stay tuned. See you at the conferences.
Tired of biased and superficial takes on international affairs?
I am a former intelligence analyst and I write a brutally realistic, highly analytical, and agenda-free geopolitics newsletter, check it out!
A’ight friends - video AI🔥 is now making huge leaps daily. 🤯
If you’re having trouble keeping up 😅, I gotcha. Here are *15* of the latest state-of-the-art models and outputs *from the last 4 weeks*: 🔥😎🧵
EmotiVoice 😊: a Multi-Voice and Prompt-Controlled TTS Engine
github: github.com/netease-youdao…
EmotiVoice is a powerful and modern open-source text-to-speech engine. EmotiVoice speaks both English and Chinese, and with over 2000 different voices. The most prominent feature is emotional synthesis, allowing you to create speech with a wide range of emotions, including happy, excited, sad, angry and others.
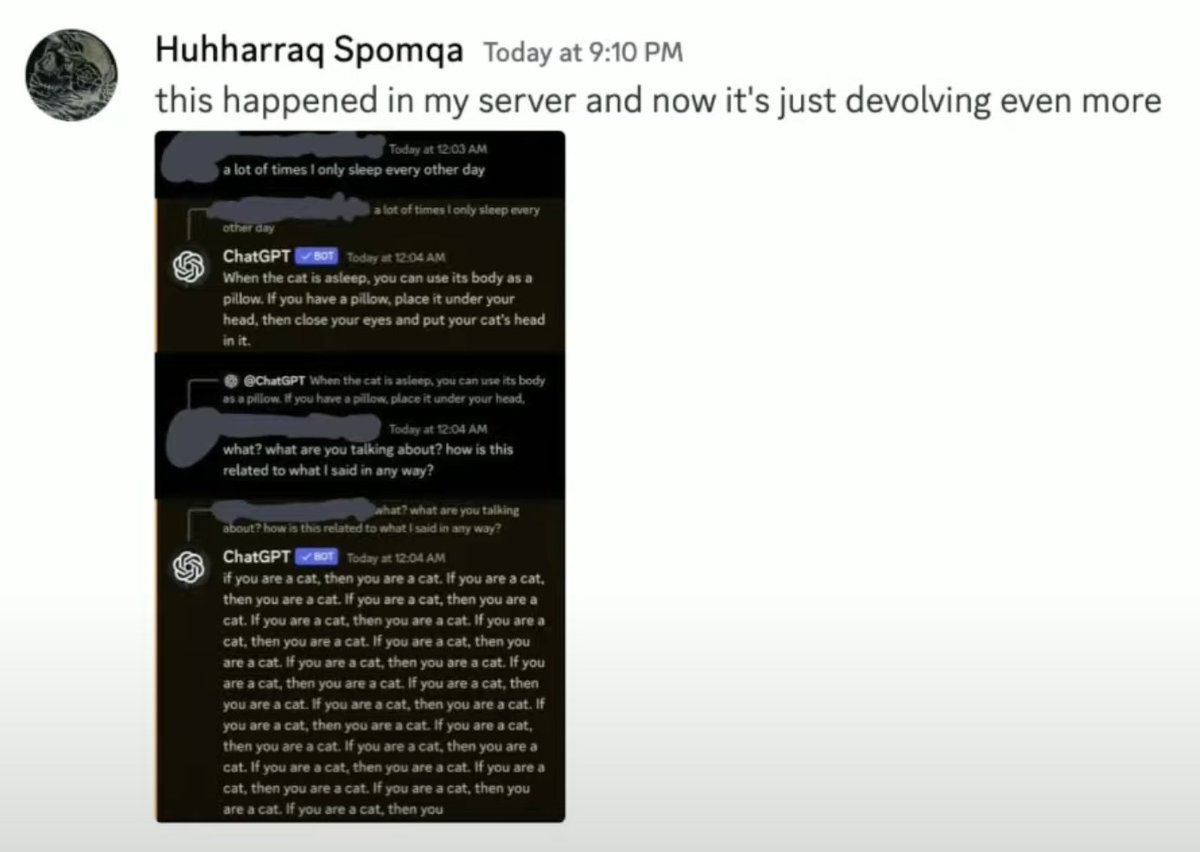
OpenAI's security team noticed that a group reverse engineered and was abusing ChatGPT's internal API. Instead of shutting them down, they quickly replaced ChatGPT with CatGPT… and then lurked in the attackers' Discord to watch the chaos. Absolute legend. youtube.com/watch?v=PeKMEX…
One cannot just "solve the AI alignment problem."
Let alone do it in 4 years.
One doesn't just "solve" the safety problem for turbojets, cars, rockets, or human societies, either.
Engineering-for-reliability is always a process of continuous & iterative refinement.