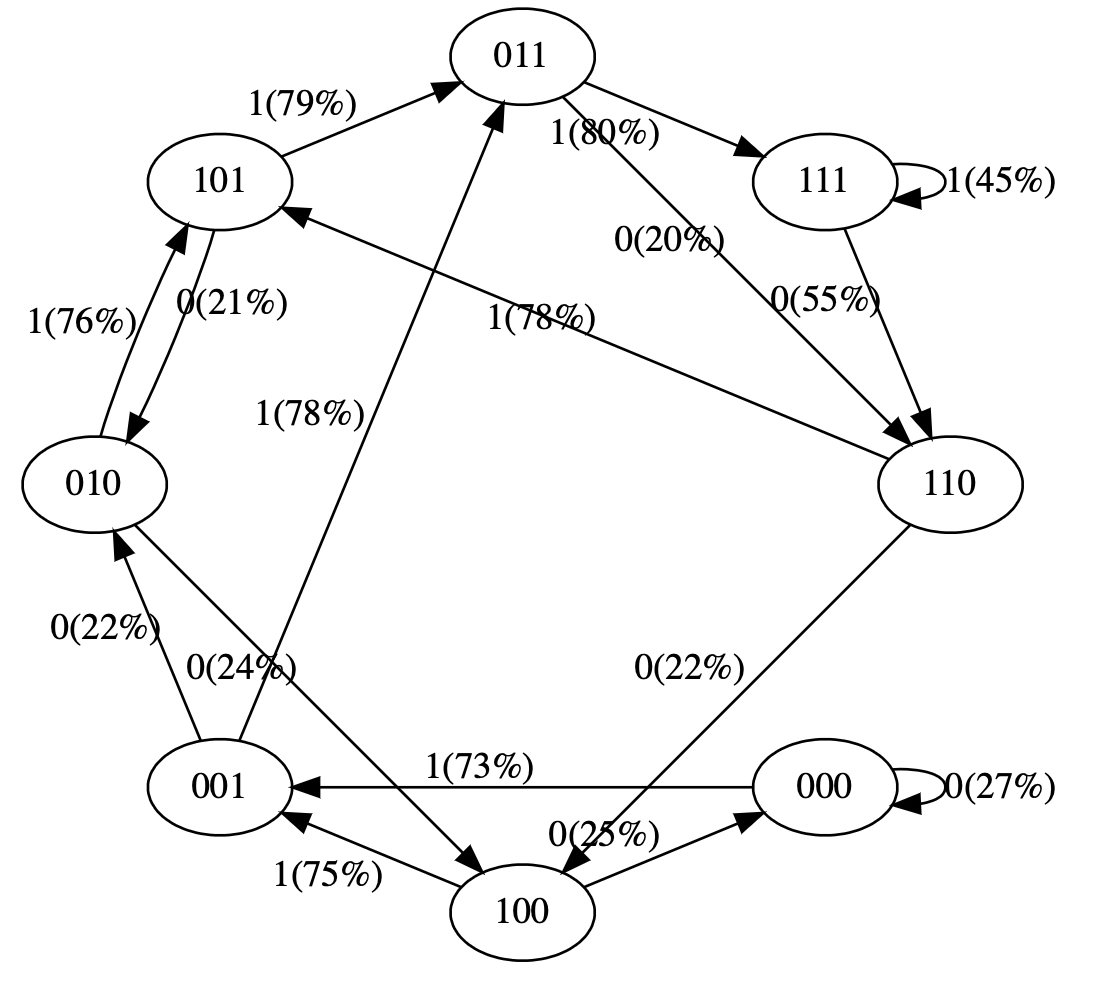
John Bush retweetledi

I believe this new model in Claude Code is a glimpse of the future we're hurtling towards, maybe as soon as the first half of next year: software engineering is done.
Soon, we won't bother to check generated code, for the same reasons we don't check compiler output.
English