
Junyu Huang
25 posts
Junyu Huang
@junyu_huang
COO @novita_labs. YC alum (Toma W24), ex-Scale AI, ex-Braze
San Francisco Katılım Nisan 2016
273 Takip Edilen68 Takipçiler

Today, we are thrilled to officially launch RadixArk with $100M in Seed funding at a $400M valuation. The round was led by @Accel and co-led by @sparkcapital.
RadixArk exists to make frontier AI infrastructure open and accessible to everyone. Today, the systems behind the most capable AI models are concentrated in a small number of companies. As a result, most AI teams are forced to rebuild training and inference stacks from scratch, duplicating the same infrastructure work instead of focusing on new models, products, and ideas.
RadixArk was founded to change that. We are building an AI platform that makes it easier for teams to train and serve the best models at scale.
RadixArk comes from the open-source community. We started with SGLang, where many of us are core developers and maintainers, and expanded our work to Miles for large-scale RL and post-training. We will continue contributing to both projects and working with the community to make them the strongest open-source infrastructure foundations for frontier AI.
We would like to thank our long-term partners, contributors, and the broader SGLang community for believing in this mission. We're also grateful to @Accel and @sparkcapital, NVentures (Venture capital arm of @nvidia), Salience Capital, A&E Investment, @HOFCapital, @walden_catalyst, @AMD, LDVP, WTT Fubon Family, @MediaTek, Vocal Ventures, @Sky9Capital and our angel investors @ibab, @LipBuTan1, Hock Tan, @johnschulman2, @soumithchintala, @lilianweng, @oliveur, @Thom_Wolf, @LiamFedus, @robertnishihara, @ericzelikman, @OfficialLoganK, and @multiply_matrix among others.
Thanks for the exclusive interview with @MeghanBobrowsky at @WSJ about our vision.

English

I'm excited to join @SpaceX and @xai to build the future of coding.
The opportunity for impact at xAI is monumental. By solving autonomous engineering, we’ll be able to accelerate our progress towards the future and reveal new secrets about the universe.
Over the last few years I've worked on the first open source AI coding agent and the number one rated plugin for JetBrains. Now I'm excited to join the world's most ambitious team to advance Al coding.
If you want to join this incredible team - my DMs are open!
English

Junyu Huang retweetledi



I spent only $10 in credits to recreate the @claudeai "ChatGPT diss” Super Bowl ad in a few hours using AI.
I’m giving away the entire AI playbook for free, showing you exactly how to make your first AI ad. (with full video prompts).
Comment “Playbook” & I’ll DM it to you.
Claude@claudeai
Ads are coming to AI. But not to Claude. Keep thinking.
English
Junyu Huang retweetledi

🟢 Novita Render Arena is almost here…
A vibe-first hackathon
Vibe coding only. No stress. No grinding.
prompts → visuals → vibes.
⏳ Starts when the next SOTA model lands.
💰 $2,000 credits pool.
Join the arena and make it glow. ✨
👇 Turn on notifications so you don’t miss the drop.

English
Junyu Huang retweetledi

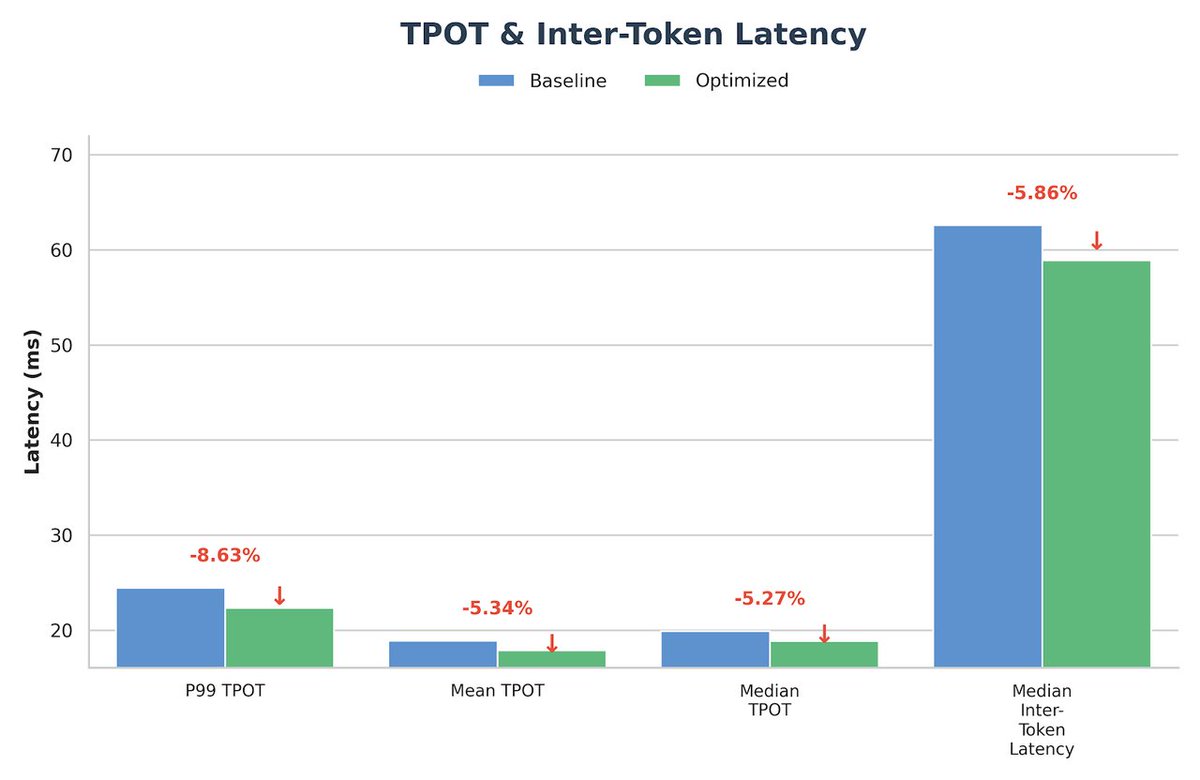
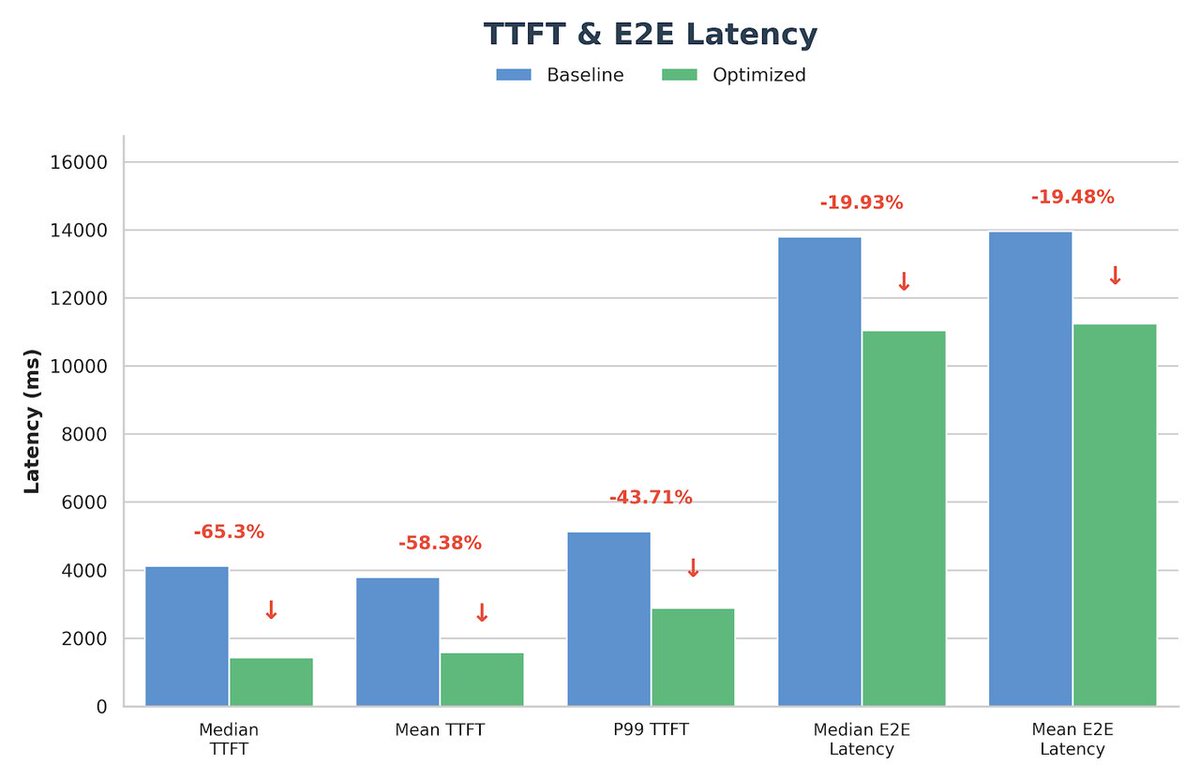
Check out our new blog by @novita_labs, where we achieved up to 65% lower TTFT and 22% faster TPOT in production!
This is an end-to-end optimization strategy spanning kernel efficiency, MoE execution, and cross-node scheduling, validated in real production environments.
Highlights
✅ Up to 65% lower Time-to-First-Token (TTFT)
✅ 22% faster TPOT under agentic coding workloads
✅ Validated on NVIDIA H200 clusters (TP8, FP8)
Key optimizations include
✨Shared Experts Fusion to boost MoE compute efficiency
✨QK-Norm + RoPE fusion to cut kernel launch overhead
✨Async transfer for PD-disaggregated deployments
✨Suffix Decoding, a model-free speculative decoding method tailored for agentic coding
Most of these optimizations are already upstream or in progress in SGLang, and are actively used in Novita AI’s production inference service.

English
Junyu Huang retweetledi

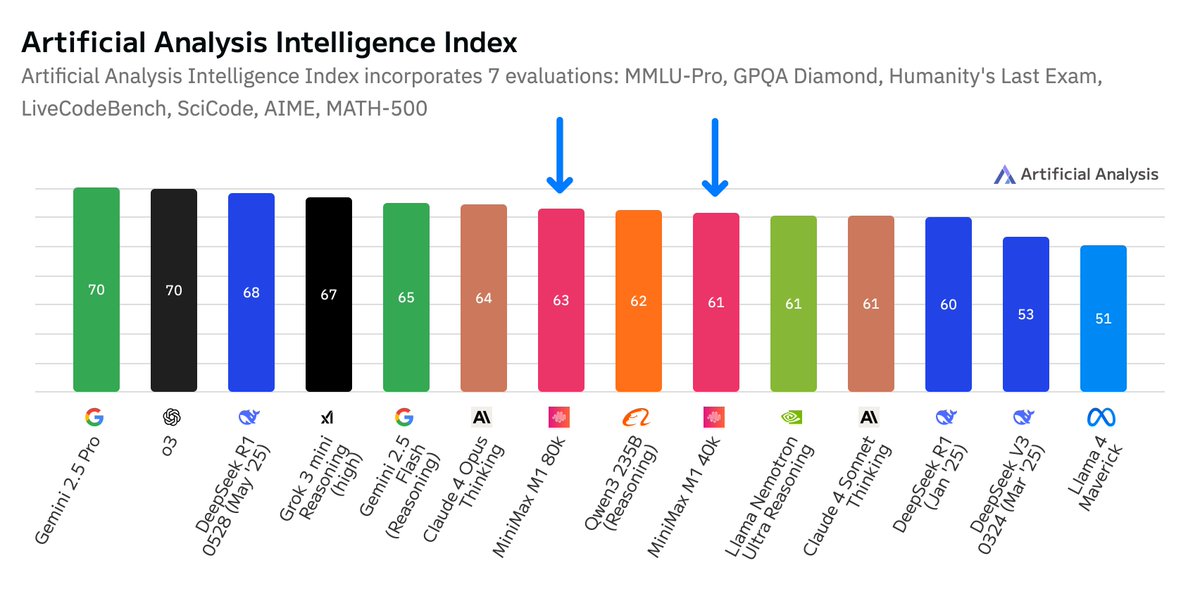
MiniMax launches their first reasoning model: MiniMax M1, the second most intelligent open weights model after DeepSeek R1, with a much longer 1M token context window
@minimax_ai M1 is based on their Text-01 model (released 14 Jan 2025) - an MoE with 456B total and 45.9B active parameters. This makes M1’s total parameter count smaller than DeepSeek R1’s 671B total parameters but larger than Qwen3 235B-A22B. Both Text-01 and M1 only support text input and output.
MiniMax M1 80K scores 63 on the Artificial Analysis Intelligence Index. This lags DeepSeek R1 0528, but is slightly ahead of Alibaba’s Qwen3 235B-A22B and NVIDIA’s Llama 3.1 Nemotron Ultra. MiniMax M1 is offered in two variants: M1 40K and M1 80K, offering 40k and 80k token thinking budgets respectively.
MiniMax discloses that their full RL training on Text-01 to create M1 used 512 H800 GPUs for three weeks - equivalent to a rental cost of $0.53M. This number is an interesting datapoint for the current degree of scaling of reinforcement learning. We note that it is not comparable to DeepSeek’s famous $5.6M training cost claim for DeepSeek V3, as DeepSeek’s number referred to full pre-training of the model not the reinforcement learning step.
MiniMax offers models across multiple modalities on their Talkie app and API, including their Artificial Analysis Speech Leaderboard topping Speech-02 model, and Video models (T2V-01, and I2V-01). MiniMax M1 is the first of five announcements in their MiniMax Week.
Availability:
➤ MiniMax M1 is available via MiniMax’s first-party API, priced at $0.4/$2.1 per 1M input/output tokens for ≤200k input tokens. The price increases to $1.2/$2.1 per 1M input/output tokens for >200k input tokens
➤ M1 is also currently available on @Novita, priced at $0.55/$2.2 per 1M input/output tokens with a 128k token context window
➤ M1 40k and M1 80k are both open weights models released under the Apache 2.0 license and we expect to see more third-party APIs supporting these models
English
Junyu Huang retweetledi

🚀 Exciting News: DeepSite v2 is Here! 🚀
We are thrilled to announce the release of DeepSite v2, packed with innovative features to enhance your experience!
✨ Brand new UI, Redesign your Site, Smart Code Editing... and more!
Wanna see more? Try DeepSite v2 today! 🌟
👇 Link
English
Junyu Huang retweetledi
The development of SGLang has greatly benefited from the computing resources provided by Novita AI (@novita_labs). We are excited to see what we will create together in the future!
Novita AI@novita_labs
Thrilled to partner with @lmsysorg! 🚀 Our high-performance GPU cloud is powering their game-changing inference engine, revolutionizing LLM deployment with breakthrough RL framework and multi-LLM serving capabilities. Together, we're bringing lightning-fast AI inference to developers worldwide! ⚡️
English
Junyu Huang retweetledi
Thrilled to partner with @lmsysorg! 🚀
Our high-performance GPU cloud is powering their game-changing inference engine, revolutionizing LLM deployment with breakthrough RL framework and multi-LLM serving capabilities.
Together, we're bringing lightning-fast AI inference to developers worldwide! ⚡️

English
Junyu Huang retweetledi

🚀Join us for the AI MCP Hackathon on May 1st (Thursday) 🌉
- Free Food 🍕
- Prizes 🏆
- Public Demos 🎤
📍 San Francisco | Powered by @Snowflake and @fondocom
🔗 Scan the QR code to register - limited spots!
English
Junyu Huang retweetledi

Big thanks to @novita_labs and @junyu_huang for powering the hackathon with high-performance and reliable LLM support 💪
Their stable infrastructure helped participants turn bold ideas into real AI products — fast, smart, and smooth. 🚀
#Trae #novita #LLM #cloud




English
Junyu Huang retweetledi
Trae is coming to @UCBerkeley!
Join us for an exciting AI Hackathon hosted by @Trae_ai in collaboration with @AIEBerkeley and @FreeVentures.
Cohost with:
@pinai_io: Amazing A16Z-backed AI + Web3 startup from Stanford University building a personalized AI platform.
@novita_labs: A global provider of cloud infrastructure, LLM services, and GPU computing solutions.
📍 Location: UC Berkeley Campus
🗓 When: April 6, 9:00 AM – 6:30 PM
🎁 Perks: Every participant will receive $50 in LLM credits and a chance to win prizes worth thousands of dollars!
👉Event Link: lu.ma/76gy00z6
#trae #hackathon #UCBerkeley

English