@koltregaskes rate limits hitting different when its their side, not yours
reminds me why i keep local models around tbh
English
Grim
372 posts

@justgrm
I write content II Trade narratives II Polymarket knows my name.




Thanks for all the input, what we'll do going forward for Codex updates - Tue: Quality and polish - Thu: Big launches (starting this Thu) - Fri: Fun stuff, little extra


THIS GUY BUILT AN ENTIRE WIKIPEDIA THAT IS 100% AI HALLUCINATIONS AND IT'S OPEN SOURCE ON GITHUB it's called Halupedia. nothing on the site existed before you clicked. every article was generated the second you arrived. the site has one rule: the universe only exists when you visit it. it looks exactly like wikipedia. same fonts. same layout. same scholarly citations. same "stumble" button for random articles. the only difference is none of it is real. here are some actual articles currently in the encyclopedia: > the great pigeon census of 1887 > the ministry of slightly wrong maps > chaldic arithmetic — a branch of mathematics where subtraction is forbidden > armund the river mapper — a cartographer who mapped 14,000 leagues of river without leaving his chair > the society for the prevention of unnecessary tuesdays every article page also tells you how many people are reading it right now. it says: "you alone are consulting this folio at present." the creator's own tagline for the site is the most unhinged sentence i've read this year: "an encyclopedia of a universe that does not exist until you visit it" the entire backend is a single open source repo called vibeserver. one guy. one description on github: "a little webserver making things up just in time." we built the largest knowledge base in human history and the very first thing a guy did with it was make a hallucinated mirror universe and put it on the open web. the internet is healing.

overtime you realize every thing you own is a small tax on your attention. maintenance, storage, insurance, repairs.. all kind of take up precious bandwidth even if you delegate it or whatever. in the past ownership used to mean freedom because the world was scarce. if you wanted access, you had to basically possess. but the modern world has been kinda redesigned around rent where you can rent anything.. incl. people, places, objects, taste, labor, entertainment.. all available on demand with a tap of a button. why would you own a car when there is uber? why would you have a vacation home when you can stay at anything you desire? why would you allocate capital anywhere other than markets where it actually compounds?

What if your team gave standup updates, and GPT-Realtime-2 moved the tickets?

Remember how Sam Altman told the US Senate he had no “direct” investment in OpenAI? and how they gushed over his apparent selflessness? 👉He didn’t mention that (presumably) he had equity in YC which likely has equity in OpenAI. And now this: 👉“OpenAI Agreed to Buy $51 Million of AI Chips From a Startup Backed by CEO Sam Altman” #candor





The first ProgramBench task was just solved by GPT 5.5 high/xhigh. Interestingly, high/xhigh picked two different languages for the task (C vs Python). GPT 5.5 xhigh was significantly better than Opus 4.7 xhigh in all metrics. 🧵

“The single strongest personality predictor [of conspiracy thinking] is narcissism. Narcissists are particularly prone to conspiracy theories because they have a strong need for uniqueness, are prone to paranoia, and can also be remarkably gullible.” stevestewartwilliams.com/p/12-things-ev…


I currently hold the record of pulling the 1st, 2nd, 5th, 6th, and 7th highest value rips on @collectdotrip since they launched just a few months ago. Trust me when I say their packs are mighty juicy! Come grab some Chaos Rising - under market and straight to your door. Best Pokemon community!



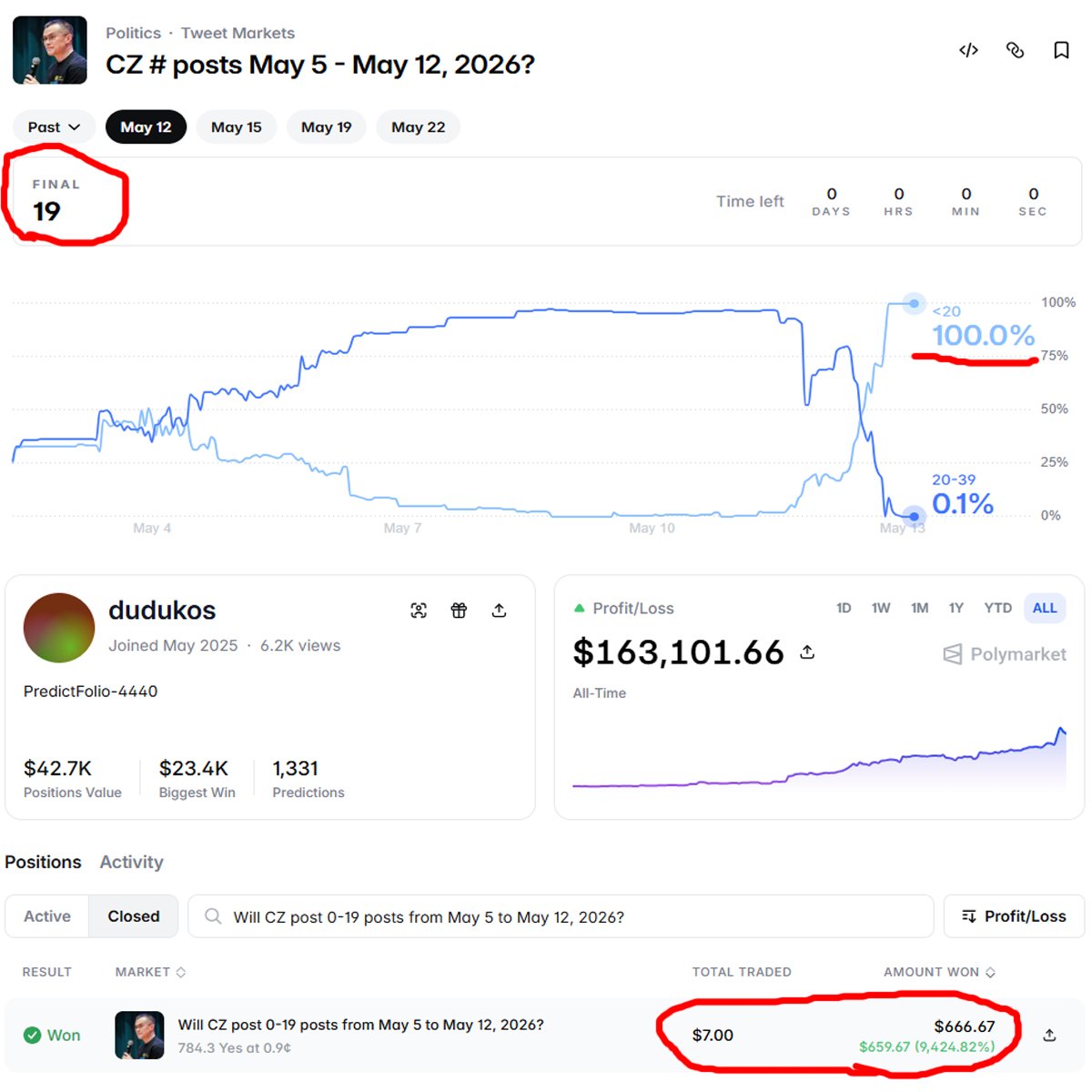
if CZ DOESN'T MAKE a post within the next 3 hours, this trader will turn $7 into $784 CZ’s last post was on May 9 19 posts total over the past week odds moved from 0.1% to 70% this trader’s avg entry is 0.9c, meaning an +11,111% pnl if he wins right now everything depends on CZ and whether he decides to wake up or not what do you think, one more post or no?