@anemll @maderix I know why. I measure ANE compute capacities couple months ago. AFAICR, MIL doesn't support INT8. With MPSGraph, which uses MLIR, you can get expected INT8 performance.
github.com/freedomtan/mea…
English
freedom Koan-Sin Tan
1.7K posts
@koansin
Coder?








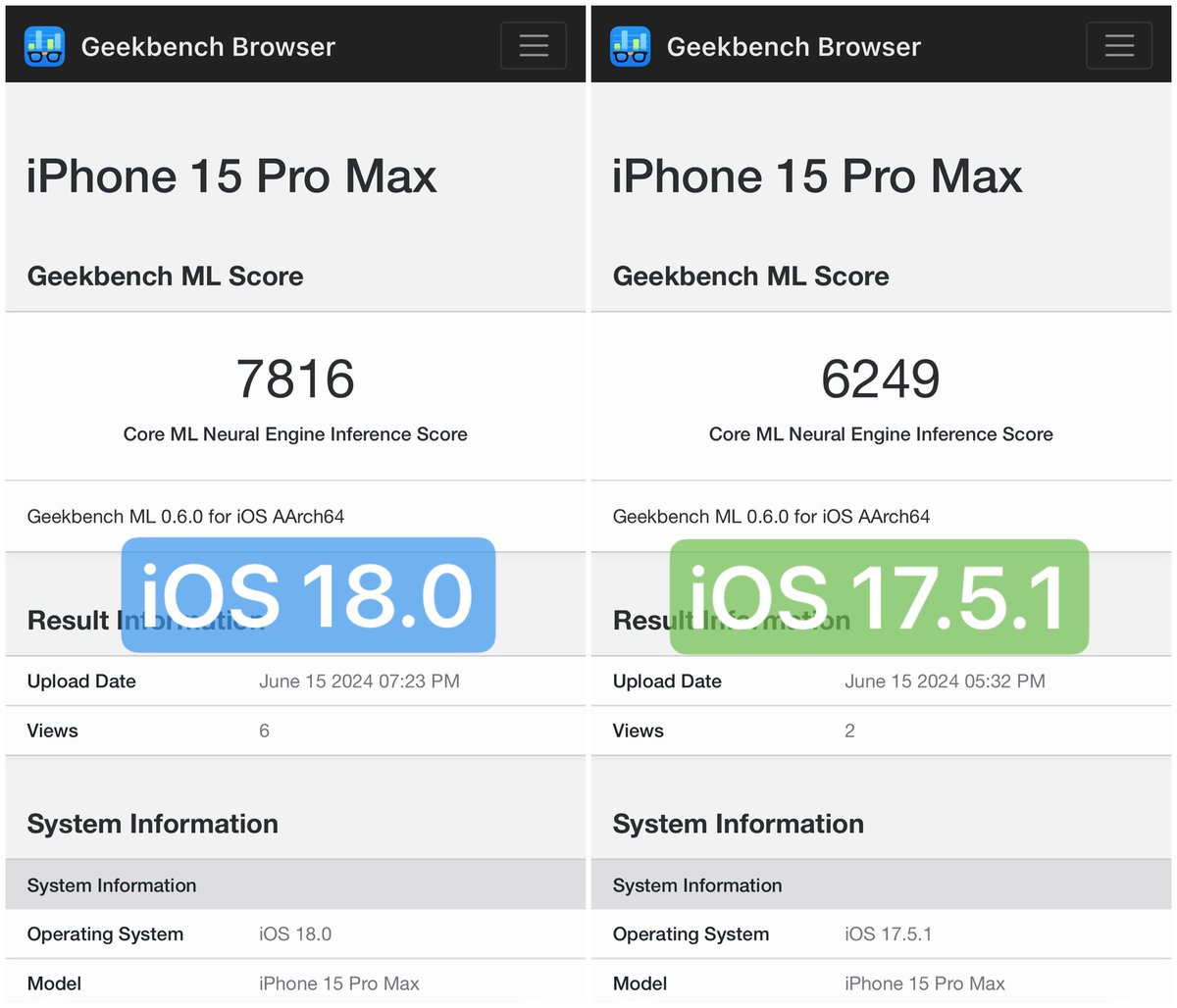
Trying to speed up Llama on Apple Neural Engine. Turns out I missed something obvious. (Can you guess it from the screenshot?) 👉 We have to transpose large matrices to compute attention. This is slow. Storing either K or V cache pre-transposed saves ~11% of the time. 11% 🙃