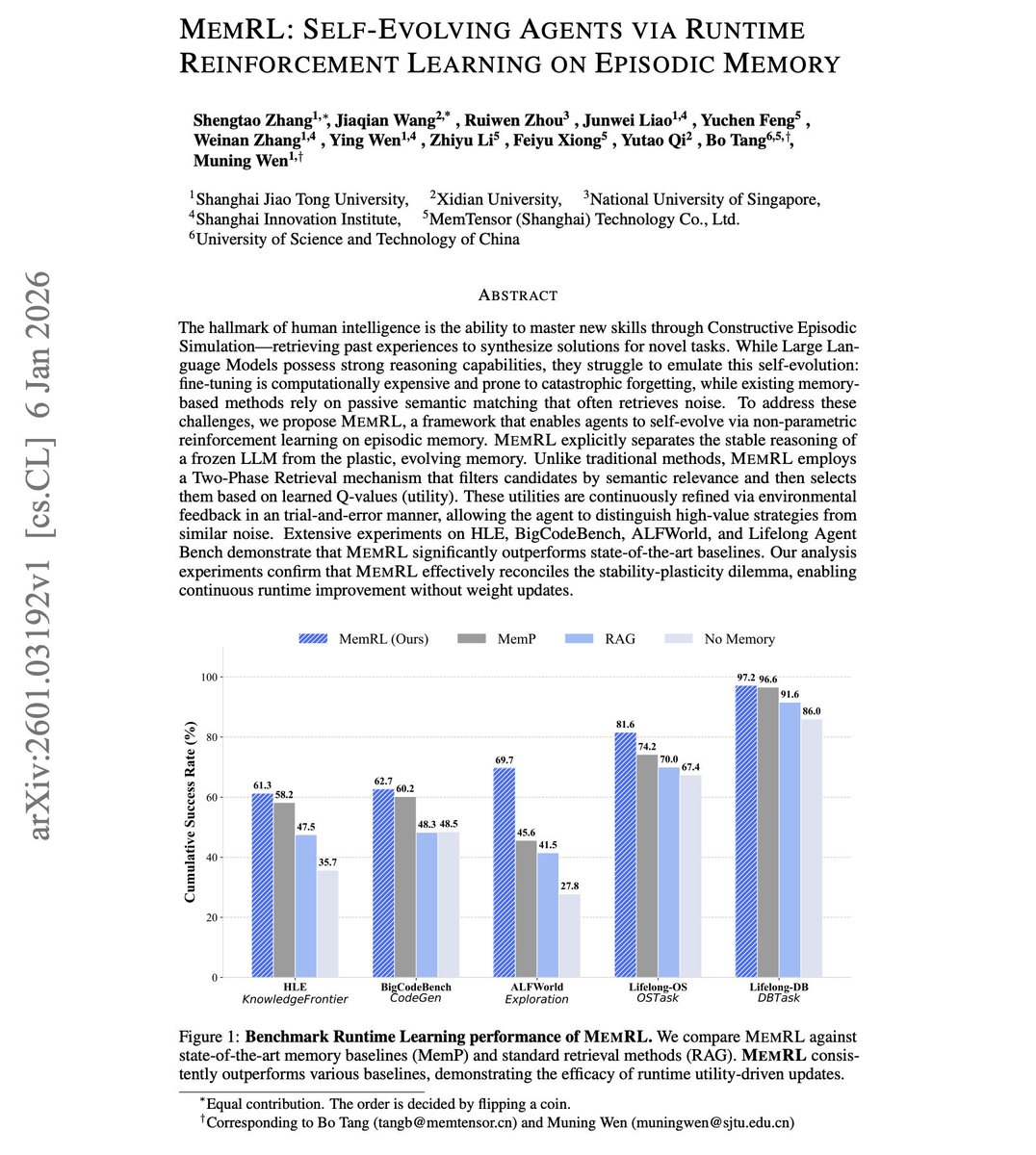
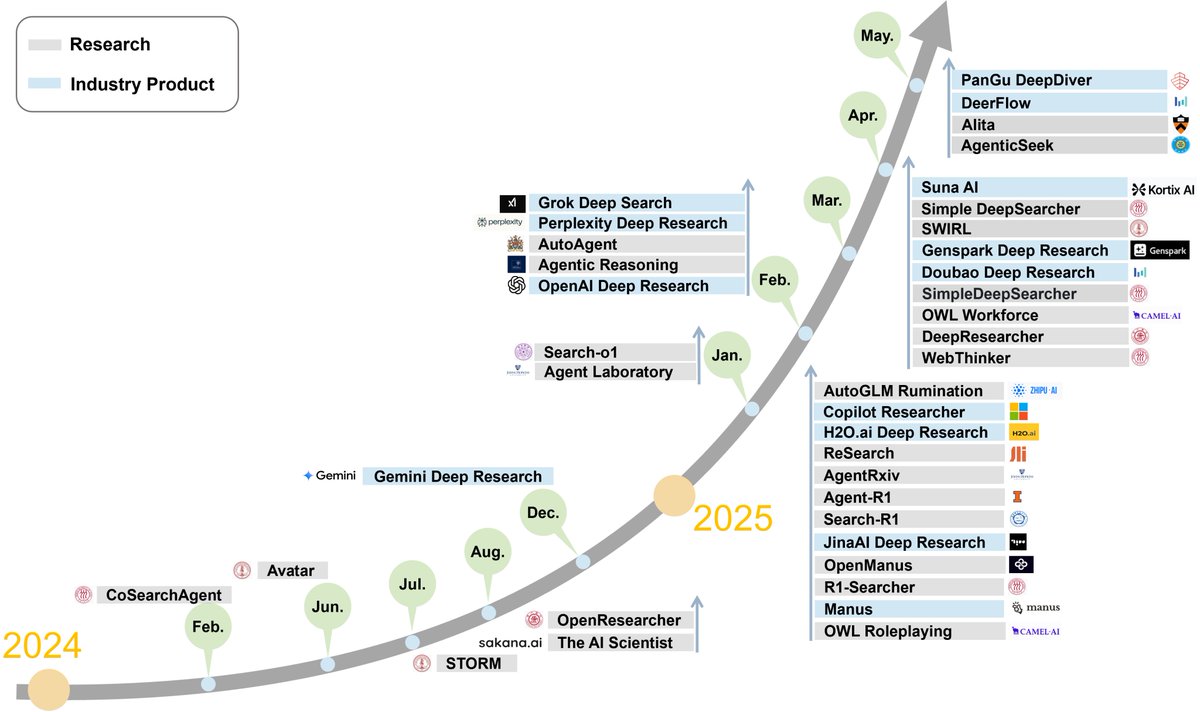
Linyi Yang retweetledi

What a ridiculous decision from #NeurIPS!
Some of the companies affected have sponsored you for years!
Blows my mind!
#AI #MachineLearning


English
Linyi Yang
117 posts







Fine-tuning LLM Agents without Fine-tuning LLMs! Imagine improving your AI agent's performance from experience without ever touching the model weights. It's just like how humans remember past episodes and learn from them. That's precisely what Memento does. The core concept: Instead of updating LLM weights, Memento learns from experiences using memory. It reframes continual learning as memory-based online reinforcement learning over a memory-augmented MDP. Think of it as giving your agent a notebook to remember what worked and what didn't! How does it work? The system breaks down into two key components: 1️⃣ Case-Based Reasoning (CBR) at work: Decomposes complex tasks into sub-tasks and retrieves relevant past experiences. No gradients needed, just smart memory retrieval! 2️⃣ Executor Executes each subtask using MCP tools and records outcomes in memory for future reference. Through MCP, the executor can accomplish most real-world tasks & has access to the following tools: 🔍 Web research 📄 Document handling 🐍 Safe Python execution 📊 Data analysis 🎥 Media processing I found this to be a really good path toward building human-like agents. 👉 Over to you, what are your thoughts? I have shared the relevant links in next tweet! _____ Share this with your network if you found this insightful ♻️ Find me → @akshay_pachaar for more insights and tutorials on AI and Machine Learning!

Fine-tuning LLM Agents without Fine-tuning LLMs Catchy title and very cool memory technique to improve deep research agents. Great for continuous, real-time learning without gradient updates. Here are my notes:








The reason I didn't write a proper arxiv paper for Muon is because I simply don't think there's any relationship between the ability to publish a paper with lots of good-looking results about a new optimizer, and whether that optimizer actually works. I only trust speedruns.



